This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
Uncomfortable truth incoming: Most people in your organization don’t think about the quality of their data from intake to production of insights. However, as a data team member, you know how important dataintegrity (and a whole host of other aspects of data management) is. What is dataintegrity?
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, DataIntegrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines.
The SAP OData connector supports both on-premises and cloud-hosted (native and SAP RISE) deployments. By using the AWS Glue OData connector for SAP, you can work seamlessly with your data on AWS Glue and Apache Spark in a distributed fashion for efficient processing.
Given the end-to-end nature of many data products and applications, sustaining ML and AI requires a host of tools and processes, ranging from collecting, cleaning, and harmonizing data, understanding what data is available and who has access to it, being able to trace changes made to data as it travels across a pipeline, and many other components.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity. For Add data source , choose Add connection.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. To incorporate this third-party data, AWS Data Exchange is the logical choice.
In this episode of “ Don’t Panic, It’s Just Data ,” host Christina Stathopoulos explores the world of real-time analytics and its impact on financial decision-making. Watch our latest podcast now for an insightful conversation on how real-time data is reshaping the future of financial planning and analysis.
The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau. While real-time data is processed by other applications, this setup maintains high-performance analytics without the expense of continuous processing.
Dataintegrity issues are a bigger problem than many people realize, mostly because they can’t see the scale of the problem. Errors and omissions are going to end up in large, complex data sets whenever humans handle the data. Prevention is the only real cure for dataintegrity issues.
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls.
Leveraging the advanced tools of the Vertex AI platform, Gemini models, and BigQuery, organizations can harness AI-driven insights and real-time data analysis, all within the trusted Google Cloud ecosystem. We believe an actionable business strategy begins and ends with accessible data.
It covers the essential steps for taking snapshots of your data, implementing safe transfer across different AWS Regions and accounts, and restoring them in a new domain. This guide is designed to help you maintain dataintegrity and continuity while navigating complex multi-Region and multi-account environments in OpenSearch Service.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
Private cloud providers may be among the key beneficiaries of today’s generative AI gold rush as, once seemingly passé in favor of public cloud, CIOs are giving private clouds — either on-premises or hosted by a partner — a second look. billion in 2024, and more than double by 2027. billion in 2024 and grow to $66.4
Trustworthy data is essential for the energy industry to overcome these challenges and accelerate the transition toward digital transformation and sustainability. Because much of today’s data is created and handled in a distributed topology, the DCF tags specific pieces of data that have traversed a range of hosts.
AI Security Policies: Navigating the future with confidence During Dubai AI&Web3 Festival recently hosted in Dubai, H.E. Dubai’s AI security policy is built on three key pillars: ensuring dataintegrity, protecting critical infrastructure, and fostering ethical AI usage.
Data also needs to be sorted, annotated and labelled in order to meet the requirements of generative AI. No wonder CIO’s 2023 AI Priorities study found that dataintegration was the number one concern for IT leaders around generative AI integration, above security and privacy and the user experience.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. Access to an SFTP server with permissions to upload and download data. Big Data and ETL Solutions Architect, MWAA and AWS Glue ETL expert. Choose Store a new secret.
IT leaders expect AI and ML to drive a host of benefits, led by increased productivity, improved collaboration, increased revenue and profits, and talent development and upskilling. Ensuring dataintegrity is part of a broader governance approach organizations will require to deploy and manage AI responsibly.
Security vulnerabilities : adversarial actors can compromise the confidentiality, integrity, or availability of an ML model or the data associated with the model, creating a host of undesirable outcomes. Privacy harms : models can compromise individual privacy in a long (and growing) list of ways. [8]
Furthermore, the format of the export and process changes slightly from election to election, making comparing data chronologically almost impossible without substantial data wrangling and ad-hoc cleaning and matching. Easily accessible linked open elections data. The data is publicly available as a SPARQL endpoint at [link].
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). Rather than putting the burden on the user to understand how the application works, with gen AI, the burden is on the computer to understand what the user wants.”
As with all financial services technologies, protecting customer data is extremely important. In some parts of the world, companies are required to host conversational AI applications and store the related data on self-managed servers rather than subscribing to a cloud-based service.
Data ingestion must be done properly from the start, as mishandling it can lead to a host of new issues. The groundwork of training data in an AI model is comparable to piloting an airplane. This may also entail working with new data through methods like web scraping or uploading.
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region.
Once the company selected its preferred technology, Mathur and her team developed a common dataintegration layer. The team built and deployed the digital twin technology in Microsoft Azure, which helped provide global access, performance, scalability, and lower cost than if it hosted in-house.
The producer account will host the EMR cluster and S3 buckets. The catalog account will host Lake Formation and AWS Glue. The consumer account will host EMR Serverless, Athena, and SageMaker notebooks. Prerequisites You need three AWS accounts with admin access to implement this solution. It is recommended to use test accounts.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and dataintegrity.
You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. With these insights, teams have the visibility to make dataintegration pipelines more efficient. Typically, you have multiple accounts to manage and run resources for your data pipeline.
DataIntegration. Dataintegration is key for any business looking to keep abreast with the ever-changing technology landscape. As a result, companies are heavily investing in creating customized software, which calls for dataintegration. Real-Time Data Processing and Delivery. Final Thoughts.
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG dataintegrity and fostering collaboration with sustainability teams.
Rise in polyglot data movement because of the explosion in data availability and the increased need for complex data transformations (due to, e.g., different data formats used by different processing frameworks or proprietary applications). As a result, alternative dataintegration technologies (e.g.,
Additionally, by managing the data product as an isolated unit it can have location flexibility and portability — private or public cloud — depending on the established sensitivity and privacy controls for the data. Doing so can increase the quality of dataintegrated into data products.
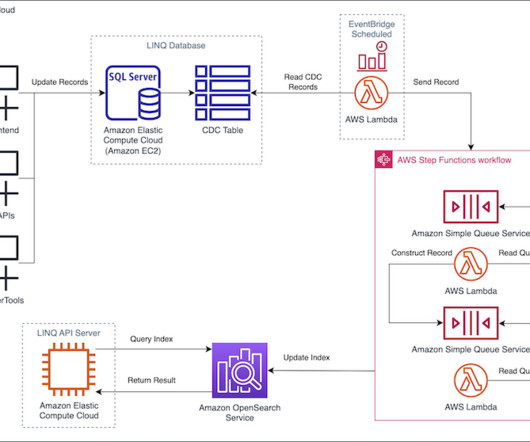
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
This podcast centers around data management and investigates a different aspect of this field each week. Within each episode, there are actionable insights that data teams can apply in their everyday tasks or projects. The host is Tobias Macey, an engineer with many years of experience. Agile Data.
Set up a custom domain with Amazon Redshift in the primary Region In the hosted zone that Route 53 created when you registered the domain, create records to tell Route 53 how you want to route traffic to Redshift endpoint by completing the following steps: On the Route 53 console, choose Hosted zones in the navigation pane.
“The introduction of the General Data Protection Regulation (GDPR) also prompted companies to think carefully about where their data is stored and the sovereignty issues that must be considered to be compliant.”. Notably, Fundaments has worked extensively with VMware for years while serving its customers. “We
With the advent of enterprise-level cloud computing, organizations could embark on cloud migration journeys and outsource IT storage space and processing power needs to public clouds hosted by third-party cloud service providers like Amazon Web Services (AWS), IBM Cloud, Google Cloud and Microsoft Azure.
In this post, we provide a step-by-step guide for installing and configuring Oracle GoldenGate for streaming data from relational databases to Amazon Simple Storage Service (Amazon S3) for real-time analytics using the Oracle GoldenGate S3 handler.
Reading Time: 5 minutes Opening the specific data view within Power BI is as simple as clicking on and opening the downloaded connection file. All the server host, ports, and database connection settings are automatically made for you so you can get on with.
It integratesdata across a wide arrange of sources to help optimize the value of ad dollar spending. Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. Along the way, metadata is collected, organized, and maintained to help debug and ensure dataintegrity.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content