This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
However, as a data team member, you know how important dataintegrity (and a whole host of other aspects of data management) is. In this article, we’ll dig into the core aspects of dataintegrity, what processes ensure it, and how to deal with data that doesn’t meet your standards.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. To incorporate this third-party data, AWS Data Exchange is the logical choice.
The SAP OData connector supports both on-premises and cloud-hosted (native and SAP RISE) deployments. By using the AWS Glue OData connector for SAP, you can work seamlessly with your data on AWS Glue and Apache Spark in a distributed fashion for efficient processing. For more information see AWS Glue.
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, DataIntegrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines. Telm.ai — Telm.ai
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications.
20, 2024 – insightsoftware , a leader in data & analytics, today announced the availability of Logi Symphony, its flagship embedded business intelligence (BI) solution, on Google Cloud Marketplace. This enables organizations to augment their products with real-time actionable intelligence, helping end users make swift, informed decisions.
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls.
For these reasons, publishing the data related to elections is obligatory for all EU member states under Directive 2003/98/EC on the re-use of public sector information and the Bulgarian Central Elections Committee (CEC) has released a complete export of every election database since 2011. Easily accessible linked open elections data.
It covers the essential steps for taking snapshots of your data, implementing safe transfer across different AWS Regions and accounts, and restoring them in a new domain. This guide is designed to help you maintain dataintegrity and continuity while navigating complex multi-Region and multi-account environments in OpenSearch Service.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
Dataintegrity issues are a bigger problem than many people realize, mostly because they can’t see the scale of the problem. Errors and omissions are going to end up in large, complex data sets whenever humans handle the data. Prevention is the only real cure for dataintegrity issues.
IT leaders expect AI and ML to drive a host of benefits, led by increased productivity, improved collaboration, increased revenue and profits, and talent development and upskilling. A data-driven foundation Of course, a dose of caution is in order, particularly with newer AI offshoots such as generative AI.
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters. Choose Create database.
Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, data lakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein. It integratesdata across a wide arrange of sources to help optimize the value of ad dollar spending.
To select a single software solution for digital twins, ConocoPhillips partnered with Global Supply Chain to conduct a request for information/request for proposal (RFI/P) process. Once the company selected its preferred technology, Mathur and her team developed a common dataintegration layer.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. Access to an SFTP server with permissions to upload and download data. Big Data and ETL Solutions Architect, MWAA and AWS Glue ETL expert. Choose Store a new secret.
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). Nearly every customer has an information architecture that expands beyond SAP. That hasn’t always been the case,” Menninger said. Customers should be encouraged.
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region. For more information, see Unleash the power of Snapshot Management to take automated snapshots using Amazon OpenSearch Service.
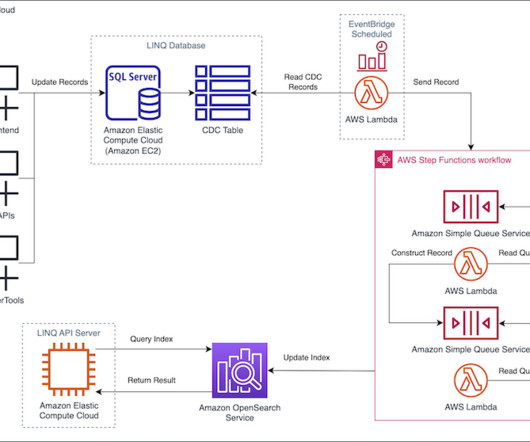
LINQ , AVB’s proprietary product information management system, empowers their appliance, consumer electronics, and furniture retailer members to streamline the management of their product catalog. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2. million record updates daily.
Think of your strategy just as that: defining the steps on your BI roadmap, following your goals as a compass to stay in the right direction, and investing and using the right tools to get a deep view of your information and understand it. It may be tempting to place the Chief Information Officer (CIO) or Chief Technical Officer (CTO).
Data ingestion must be done properly from the start, as mishandling it can lead to a host of new issues. The groundwork of training data in an AI model is comparable to piloting an airplane. This may also entail working with new data through methods like web scraping or uploading.
Through the use of data lineage, companies can better understand their data and its journey. Incorporating data lineage into an organization’s strategy can make a huge difference when it comes to making accurate business decisions and having a handle on the information they already possess. Agile Data. Dataversity.
Some of the areas that seem to be at the forefront of adopting Big Data is software and web development industries. As a result, processing and analyzing unstructured data is super-difficult and time-consuming. Semi-structured data contains a mixture of both structured and unstructured data. Characteristics of Big Data.
The 4Vs of Big data inhibits the speed and quality of processing. This leads to application failures and breakdown of enterprise data flows that further result in incomprehensible information losses and painful delays in mission-critical business operations. Data Storage Layer: In this layer, the processed data is stored.
“The introduction of the General Data Protection Regulation (GDPR) also prompted companies to think carefully about where their data is stored and the sovereignty issues that must be considered to be compliant.”. Notably, Fundaments has worked extensively with VMware for years while serving its customers. “We
Cybersecurity, often known as information security or IT security, keeps information on the internet and within computer systems and networks secure against unauthorized users. Cybersecurity is the practice of taking precautions to protect data privacy, security, and reliability from being compromised online.
A snapshot contains data from all databases that are running on your cluster. It also contains information about your cluster, including the number of nodes, node type, and admin user name. If you restore your cluster from a snapshot, Amazon Redshift uses the cluster information to create a new cluster. Choose your hosted zone.
Streaming ingestion from Amazon MSK into Amazon Redshift, represents a cutting-edge approach to real-time data processing and analysis. Amazon MSK serves as a highly scalable, and fully managed service for Apache Kafka, allowing for seamless collection and processing of vast streams of data.
For enterprises dealing with sensitive information, it is vital to maintain state-of-the-art data security in order to reap the rewards,” says Stuart Winter, Executive Chairman and Co-Founder at Lacero Platform Limited, Jamworks and Guardian. This ensures that students can trust the output in front of them.
Hybrid cloud continues to help organizations gain cost-effectiveness and increase data mobility between on-premises, public cloud, and private cloud without compromising dataintegrity. With a multi-cloud strategy, organizations get the flexibility to collect, segregate and store data whether it’s on- or off-premises.
All are ideally qualified to help their customers achieve and maintain the highest standards for dataintegrity, including absolute control over data access, transparency and visibility into the provider’s operation, the knowledge that their information is managed appropriately, and access to VMware’s growing ecosystem of sovereign cloud solutions.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s Data Quality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 4: Data Sources. steps 4, 5 and 6).
Internal data monetization initiatives measure improvement in process design, task guidance and optimization of data used in the organization’s product or service offerings. Creating value from data involves taking some action on the data. Doing so can increase the quality of dataintegrated into data products.
Reading Time: 5 minutes Opening the specific data view within Power BI is as simple as clicking on and opening the downloaded connection file. All the server host, ports, and database connection settings are automatically made for you so you can get on with.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. DMPs excel at negotiating with a wide array of databases, data lakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Cloudera on Private Cloud with the Private Cloud Base (CDP PvC Base) stands as a beacon of innovation in the realm of data security, offering a holistic suite of features that work in concert to safeguard sensitive information. With the latest 7.1.9 and 7.9.
After all, 41% of employees acquire, modify, or create technology outside of IT’s visibility , and 52% of respondents to EY’s Global Third-Party Risk Management Survey had an outage — and 38% reported a data breach — caused by third parties over the past two years. There may be times when department-specific data needs and tools are required.
With the advent of enterprise-level cloud computing, organizations could embark on cloud migration journeys and outsource IT storage space and processing power needs to public clouds hosted by third-party cloud service providers like Amazon Web Services (AWS), IBM Cloud, Google Cloud and Microsoft Azure.
In this post, we provide a step-by-step guide for installing and configuring Oracle GoldenGate for streaming data from relational databases to Amazon Simple Storage Service (Amazon S3) for real-time analytics using the Oracle GoldenGate S3 handler. Refer to Amazon EBS-optimized instance types for more information.
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic dataintegration , and ontology building.
The protection of data-at-rest and data-in-motion has been a standard practice in the industry for decades; however, with advent of hybrid and decentralized management of infrastructure it has now become imperative to equally protect data-in-use.
For organizations to work optimally, “information technology must be aligned with business vision and mission,” says Shuvankar Pramanick, deputy CIO at Manipal Health Enterprises. Hosting the entire infrastructure on-premise will turn out to be exorbitant,” he says. Adopt the agile methodology.
Using Amazon MSK, we securely stream data with a fully managed, highly available Apache Kafka service. Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, dataintegration, and mission-critical applications.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content