This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
An extract, transform, and load (ETL) process using AWS Glue is triggered once a day to extract the required data and transform it into the required format and quality, following the data product principle of data mesh architectures. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. Amazon Athena is used to query, and explore the data.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity. For Add data source , choose Add connection.
Trustworthy data is essential for the energy industry to overcome these challenges and accelerate the transition toward digital transformation and sustainability. Specifically, what the DCF does is capture metadata related to the application and compute stack. Addressing this complex issue requires a multi-pronged approach.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and dataintegrity.
For this, Cargotec built an Amazon Simple Storage Service (Amazon S3) data lake and cataloged the data assets in AWS Glue Data Catalog. They chose AWS Glue as their preferred dataintegration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
In-place data upgrade In an in-place data migration strategy, existing datasets are upgraded to Apache Iceberg format without first reprocessing or restating existing data. In this method, the metadata are recreated in an isolated environment and colocated with the existing data files. Open AWS Glue Studio.
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). The company is expanding its partnership with Collibra to integrate Collibra’s AI Governance platform with SAP data assets to facilitate data governance for non-SAP data assets in customer environments. “We
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless dataintegration engine.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. To address this challenge, organizations can deploy a data mesh using AWS Lake Formation that connects the multiple EMR clusters. An entity can act both as a producer of data assets and as a consumer of data assets.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic.
Data ingestion must be done properly from the start, as mishandling it can lead to a host of new issues. The groundwork of training data in an AI model is comparable to piloting an airplane. The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions.
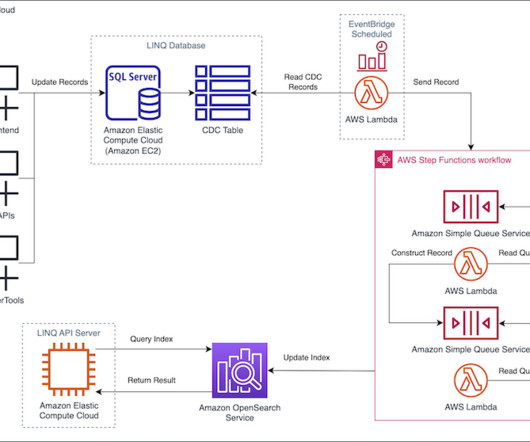
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
Added to this is the increasing demands being made on our data from event-driven and real-time requirements, the rise of business-led use and understanding of data, and the move toward automation of dataintegration, data and service-level management. Knowledge Graphs are the Warp and Weft of a Data Fabric.
It integratesdata across a wide arrange of sources to help optimize the value of ad dollar spending. Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. Along the way, metadata is collected, organized, and maintained to help debug and ensure dataintegrity.
Within each episode, there are actionable insights that data teams can apply in their everyday tasks or projects. The host is Tobias Macey, an engineer with many years of experience. Agile Data. Agile Data. Another podcast we think is worth a listen is Agile Data.
You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. With these insights, teams have the visibility to make dataintegration pipelines more efficient. An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog.
Rise in polyglot data movement because of the explosion in data availability and the increased need for complex data transformations (due to, e.g., different data formats used by different processing frameworks or proprietary applications). As a result, alternative dataintegration technologies (e.g.,
If you want to know why a report from Power BI delivered a particular number, data lineage traces that data point back through your data warehouse or lakehouse, back through your dataintegration tool, back to where the data basis for that report metric first entered your system.
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic dataintegration , and ontology building.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. Over time, workloads start processing more data, tenants start onboarding more workloads, and administrators (admins) start onboarding more tenants.
We offer a seamless integration of the PoolParty Semantic Suite and GraphDB , called the PowerPack bundles. This enables our customers to work with a rich, user-friendly toolset to manage a graph composed of billions of edges hosted in data centers around the world. PowerPack Bundles – What is it and what is included?
All are ideally qualified to help their customers achieve and maintain the highest standards for dataintegrity, including absolute control over data access, transparency and visibility into the provider’s operation, the knowledge that their information is managed appropriately, and access to VMware’s growing ecosystem of sovereign cloud solutions.
It integratesdata across a wide arrange of sources to help optimize the value of ad dollar spending. Its cloud-hosted tool manages customer communications to deliver the right messages at times when they can be absorbed. Along the way, metadata is collected, organized, and maintained to help debug and ensure dataintegrity.
To develop your disaster recovery plan, you should complete the following tasks: Define your recovery objectives for downtime and data loss (RTO and RPO) for data and metadata. Choose your hosted zone. On the Route 53 console, choose Hosted zones in the navigation pane. Choose your hosted zone. Choose Save.
Data governance shows up as the fourth-most-popular kind of solution that enterprise teams were adopting or evaluating during 2019. That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. Those days are long gone if they ever existed.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Then, you transform this data into a concise format.
With the new REST API, you can now invoke DAG runs, manage datasets, or get the status of Airflow’s metadata database, trigger, and scheduler—all without relying on the Airflow web UI or CLI. Args: region (str): AWS region where the MWAA environment is hosted. Args: region (str): AWS region where the MWAA environment is hosted.
Metadata and Governance. The company also recently hosted a webinar on Democratizing the Data Lake with Constellation Research and published 2 whitepapers from Mark Madsen. Ingest and Delivery. Discovery and Preparation. Transformation and Analytics. Scheduling and Workflow.
The system ingests data from various sources such as cloud resources, cloud activity logs, and API access logs, and processes billions of messages, resulting in terabytes of data daily. This data is sent to Apache Kafka, which is hosted on Amazon Managed Streaming for Apache Kafka (Amazon MSK).
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating data lakes, serving as object storage for consumer applications, storing logs, and archiving data. For Report path prefix , enter cur-data/account-cur-daily.
What if, experts asked, you could load raw data into a warehouse, and then empower people to transform it for their own unique needs? Today, dataintegration platforms like Rivery do just that. By pushing the T to the last step in the process, such products have revolutionized how data is understood and analyzed.
On Thursday January 6th I hosted Gartner’s 2022 Leadership Vision for Data and Analytics webinar. Much as the analytics world shifted to augmented analytics, the same is happening in data management. Where these efforts break down is in the data that goes into the connection at one end and comes out the other.
Last week, the Alation team had the privilege of joining IT professionals, business leaders, and data analysts and scientists for the Modern Data Stack Conference in San Francisco.
Data mapping is essential for integration, migration, and transformation of different data sets; it allows you to improve your data quality by preventing duplications and redundancies in your data fields. Data mapping helps standardize, visualize, and understand data across different systems and applications.
Metadata Self-service analysis is made easy with user-friendly naming conventions for tables and columns. That means it should be connected to your data sources, integrated with your security, and be embedded into your app. addresses). Furthermore, it uses techniques that are known for scaling the implementation.
HBase can run on Hadoop Distributed File System (HDFS) or Amazon Simple Storage Service (Amazon S3) , and can host very large tables with billions of rows and millions of columns. Test and verify After incremental data synchronization is complete, you can start testing and verifying the results.
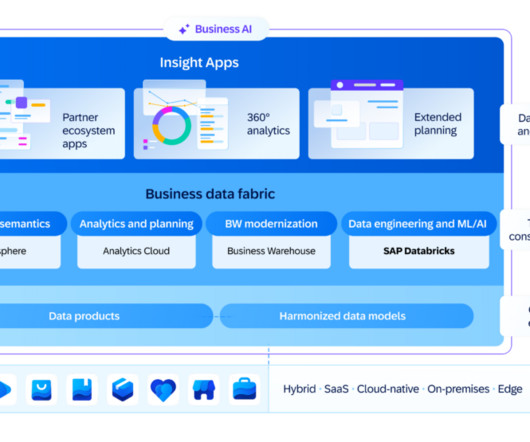
Business Data Cloud (BDC) consists of multiple existing and new services built by SAP and its partners: Object store which is an OEM from Databricks Databricks Data Engineering and AI/ML Tools SAP Datasphere SAP BW 7.5 Instead, the Databricks object store provides an industry-standard and more cost-efficient solution for storing data.
To avoid this situation, Oktank aims to decouple compute from storage, allowing them to scale down compute nodes and repurpose them for other workloads without compromising dataintegrity and accessibility. The Data Catalog is a centralized metadata repository for all your data assets across various data sources.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content