This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. Meta-Orchestration .
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls.
In this post, I’ll describe some of the key areas of interest and concern highlighted by respondents from Europe, while describing how some of these topics will be covered at the upcoming Strata Data conference in London (April 29 - May 2, 2019). Data Platforms. DataIntegration and Data Pipelines.
When dealing with third-party data sources, AWS Data Exchange simplifies the discovery, subscription, and utilization of third-party data from a diverse range of producers or providers. As a producer, you can also monetize your data through the subscription model using AWS Data Exchange.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account.
The SAP OData connector supports both on-premises and cloud-hosted (native and SAP RISE) deployments. By using the AWS Glue OData connector for SAP, you can work seamlessly with your data on AWS Glue and Apache Spark in a distributed fashion for efficient processing.
Organizations can now streamline digital transformations with Logi Symphony on Google Cloud, utilizing BigQuery, the Vertex AI platform and Gemini models for cutting-edge analytics RALEIGH, N.C. – We believe an actionable business strategy begins and ends with accessible data.
Private cloud providers may be among the key beneficiaries of today’s generative AI gold rush as, once seemingly passé in favor of public cloud, CIOs are giving private clouds — either on-premises or hosted by a partner — a second look. You don’t want a mistake to happen and have it end up ingested or part of someone else’s model.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
ChatGPT is capable of doing many of these tasks, but the custom support chatbot is using another model called text-embedding-ada-002, another generative AI model from OpenAI, specifically designed to work with embeddings—a type of database specifically designed to feed data into large language models (LLM).
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). We have cataloging inside Datasphere: It allows you to catalog, manage metadata, all the SAP data assets we’re seeing,” said JG Chirapurath, chief marketing and solutions officer for SAP. “We
Recent research by McGuide Research Services for Avanade found 91% of organisations in the sector believe they need to shift to an AI-first operating model within the next 12 months, while 87% of employees feel generative AI tools will make them more efficient, and more innovative. This requires skillsets that firms may not have in-house.
Data doubt compounds tough edge challenges The variety of operational challenges at the edge are compounded by the difficulties of sourcing trustworthy data sets from heterogeneous IT/OT estates. Addressing this complex issue requires a multi-pronged approach.
IT leaders expect AI and ML to drive a host of benefits, led by increased productivity, improved collaboration, increased revenue and profits, and talent development and upskilling. A data-driven foundation Of course, a dose of caution is in order, particularly with newer AI offshoots such as generative AI.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
Furthermore, the format of the export and process changes slightly from election to election, making comparing data chronologically almost impossible without substantial data wrangling and ad-hoc cleaning and matching. Easily accessible linked open elections data. The data is publicly available as a SPARQL endpoint at [link].
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into datamodels to ensuring ESG dataintegrity and fostering collaboration with sustainability teams.
Companies still often accept the risk of using internal data when exploring large language models (LLMs) because this contextual data is what enables LLMs to change from general-purpose to domain-specific knowledge. In the generative AI or traditional AI development cycle, data ingestion serves as the entry point.
Continue to conquer data chaos and build your data landscape on a sturdy and standardized foundation with erwin® DataModeler 14.0. The gold standard in datamodeling solutions for more than 30 years continues to evolve with its latest release, highlighted by: PostgreSQL 16.x
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and dataintegrity.
But few organizations have made the strategic shift to managing “data as a product.” ” This data management means applying product development practices to data. Serve: Data products are discoverable and consumed as services, typically via a platform.
After all, 41% of employees acquire, modify, or create technology outside of IT’s visibility , and 52% of respondents to EY’s Global Third-Party Risk Management Survey had an outage — and 38% reported a data breach — caused by third parties over the past two years.
If you’re a long-time erwin ® DataModeler by Quest ® customer, you might be asking yourself, “What happened to the release naming convention of erwin DataModeler?” In 2021 erwin DataModeler released 2021R1. What’s new in erwin DataModeler R12.0? DevOps GitHub integration via Mart.
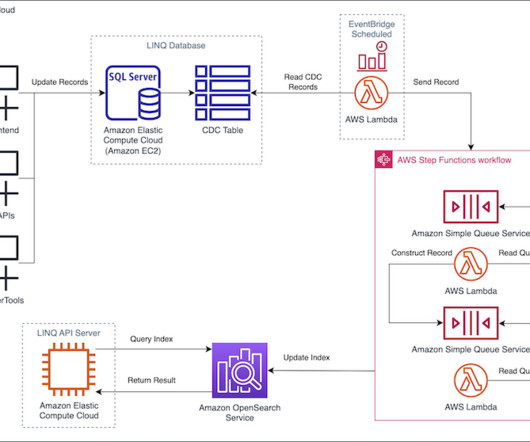
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
The rise of hybrid cloud Before delving into the advantages of hybrid cloud , let’s examine how the hybrid cloud computing model became the essential IT infrastructure model for protecting critical data and running workloads. A private cloud setup is usually hosted in an organization’s on-premises data center.
In legacy analytical systems such as enterprise data warehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. As a result, alternative dataintegration technologies (e.g.,
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled data quality challenges. Data must be combined and harmonized from multiple sources into a unified, coherent format before being used with AI models.
Leverage cloud in the hybrid model. Storage solutions must be agile, and that’s why many organizations are adopting hybrid cloud solutions to accommodate changes in application and data growth. With a multi-cloud strategy, organizations get the flexibility to collect, segregate and store data whether it’s on- or off-premises.
For consumer access, a centralized catalog is necessary where producers can publish their data assets. Cross-producer data access – Consumers may need to access data from multiple producers within the same catalog environment. The producer account will host the EMR cluster and S3 buckets. VPC with the CIDR 10.0.0.0/16.
For enterprises dealing with sensitive information, it is vital to maintain state-of-the-art data security in order to reap the rewards,” says Stuart Winter, Executive Chairman and Co-Founder at Lacero Platform Limited, Jamworks and Guardian.
The protection of data-at-rest and data-in-motion has been a standard practice in the industry for decades; however, with advent of hybrid and decentralized management of infrastructure it has now become imperative to equally protect data-in-use.
Hosting the entire infrastructure on-premise will turn out to be exorbitant,” he says. For instance, in the case of a mobile app built for a company’s sales representatives, the process can be split into three components — the UI/UX component, dataintegration, and integration with other third-party apps.
What’s the business impact of critical data elements being trustworthy… or not? In this step, you connect dataintegrity to business results in shared definitions. This work enables business stewards to prioritize data remediation efforts. Step 4: Data Sources. Step 9: Data Quality Remediation Plans.
The release of ChatGPT pushed the interest in and expectations of Large Language Model based use cases to record heights. Privacy concerns loom large, as many enterprises are cautious about sharing their internal knowledge base with external providers to safeguard dataintegrity. V100, A100, T4 GPUs).
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic dataintegration , and ontology building.
Flexibility is an absolute must for your planning solution to support a Sales Compensation Model, as well as extensive analytic and reporting capabilities. Let’s dive deeper: Dataintegration. Modeling and What-if capabilities. Pre-Packaged Model. No custom code or IT resources required.
Added to this is the increasing demands being made on our data from event-driven and real-time requirements, the rise of business-led use and understanding of data, and the move toward automation of dataintegration, data and service-level management. This provides a solid foundation for efficient dataintegration.
The AWS pay-as-you-go model and the constant pace of innovation in data processing technologies enable CFM to maintain agility and facilitate a steady cadence of trials and experimentation. In this post, we share how we built a well-governed and scalable data engineering platform using Amazon EMR for financial features generation.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. need to integrate multiple “point solutions” used in a data ecosystem) and organization reasons (e.g.,
We offer a seamless integration of the PoolParty Semantic Suite and GraphDB , called the PowerPack bundles. This enables our customers to work with a rich, user-friendly toolset to manage a graph composed of billions of edges hosted in data centers around the world. PowerPack Bundles – What is it and what is included?
With the emergence of new creative AI algorithms like large language models (LLM) fromOpenAI’s ChatGPT, Google’s Bard, Meta’s LLaMa, and Bloomberg’s BloombergGPT—awareness, interest and adoption of AI use cases across industries is at an all time high. The reality of LLMs and other “narrow” AI technologies is that none of them is turn-key.
Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver fast performance for even the most demanding and unpredictable workloads, and you pay only for what you use. For Host , enter the Redshift Serverless endpoint’s host URL. For Port , enter 5349. This is optional.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. Over time, workloads start processing more data, tenants start onboarding more workloads, and administrators (admins) start onboarding more tenants. Cloudera Manager (CM) 6.2
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content