This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
Uncomfortable truth incoming: Most people in your organization don’t think about the quality of their data from intake to production of insights. However, as a data team member, you know how important dataintegrity (and a whole host of other aspects of data management) is. What is dataintegrity?
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. This data platform is managed by Amazon Data Zone.
It covers the essential steps for taking snapshots of your data, implementing safe transfer across different AWS Regions and accounts, and restoring them in a new domain. This guide is designed to help you maintain dataintegrity and continuity while navigating complex multi-Region and multi-account environments in OpenSearch Service.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity. For Add data source , choose Add connection.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region. We refer to this role as TheSnapshotRole in this post. For instructions, refer to the earlier section in this post.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
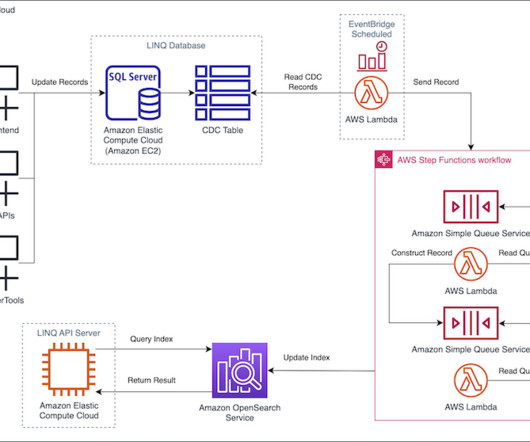
Initially, searches from Hub queried LINQ’s Microsoft SQL Server database hosted on Amazon Elastic Compute Cloud (Amazon EC2), with search times averaging 3 seconds, leading to reduced adoption and negative feedback. The LINQ team exposes access to the OpenSearch Service index through a search API hosted on Amazon EC2.
In this article, we are going to look at how software development can leverage on Big Data. We will also briefly have a sneak preview of the connection between AI and Big Data. Software development simply refers to a set of computer science-related activities purely dedicated to building, designing, and deploying software.
In this post, we provide a step-by-step guide for installing and configuring Oracle GoldenGate for streaming data from relational databases to Amazon Simple Storage Service (Amazon S3) for real-time analytics using the Oracle GoldenGate S3 handler. For more details, refer to Operating System Requirements.
For additional details, refer to Automated snapshots. For additional details, refer to Manual snapshots. Amazon Redshift integrates with AWS Backup to help you centralize and automate data protection across all your AWS services, in the cloud, and on premises. This can result in recovery times between 10–60 minutes.
Data lakes are not transactional by default; however, there are multiple open-source frameworks that enhance data lakes with ACID properties, providing a best of both worlds solution between transactional and non-transactional storage mechanisms. The referencedata is continuously replicated from MySQL to DynamoDB through AWS DMS.
Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc. The gigantic evolution of structured, unstructured, and semi-structured data is referred to as Big data. Videos, pictures etc.
Refer to the following cloudera blog to understand the full potential of Cloudera Data Engineering. . Precisely DataIntegration, Change Data Capture and Data Quality tools support CDP Public Cloud as well as CDP Private Cloud. For further details on the API, please refer to the following doc link here. .
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.
Additionally, by managing the data product as an isolated unit it can have location flexibility and portability — private or public cloud — depending on the established sensitivity and privacy controls for the data. Doing so can increase the quality of dataintegrated into data products.
Rise in polyglot data movement because of the explosion in data availability and the increased need for complex data transformations (due to, e.g., different data formats used by different processing frameworks or proprietary applications). As a result, alternative dataintegration technologies (e.g.,
Using Amazon MSK, we securely stream data with a fully managed, highly available Apache Kafka service. Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, dataintegration, and mission-critical applications.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Introduction.
dataintegrity. Pushing FE scripts to a Git repository involves: Connecting erwin Data Modeler to Mart Server. Connecting erwin Data Modeler to a Git repository. Connecting erwin Data Modeler to Git Repositories. A Git repository may be hosted on GitLab or GitHub. Git Hosting Service. version control.
Refer to Creating an Apache Airflow web login token for more details. Args: region (str): AWS region where the MWAA environment is hosted. Args: region (str): AWS region where the MWAA environment is hosted. To learn more about the Airflow REST API and its various endpoints, refer to the Airflow documentation.
A business intelligence strategy refers to the process of implementing a BI system in your company. IT should be involved to ensure governance, knowledge transfer, dataintegrity, and the actual implementation. Then for knowledge transfer choose the repository, best suited for your organization, to host this information.
About Talend Talend is an AWS ISV Partner with the Amazon Redshift Ready Product designation and AWS Competencies in both Data and Analytics and Migration. Talend Cloud combines dataintegration, dataintegrity, and data governance in a single, unified platform that makes it easy to collect, transform, clean, govern, and share your data.
They can access the models via APIs, augment them with embeddings, or develop a new custom model by fine-tuning an existing model via training it on new data, which is the most complex approach, according to Chandrasekaran. You have to get your data and annotate it,” he says. “So Use cases include dataintegration in the enterprise.
More specifically, confidential computing uses hardware-based security-rich enclaves to allow a tenant to host workloads and data on untrusted infrastructure while ensuring that their workloads and data cannot be read or modified by anyone with privileged access to that infrastructure.
Let’s start with some commonly used terms: Disaster recovery (DR): Disaster recovery (DR) refers to an enterprise’s ability to recover from an unplanned event that impacts normal business operations. Strong DR planning helps businesses protect critical data and restore normal processes in a matter of days, hours and even minutes.
Change data capture (CDC) is one of the most common design patterns to capture the changes made in the source database and reflect them to other data stores. a new version of AWS Glue that accelerates dataintegration workloads in AWS. For more information, refer to Signing up for an Amazon QuickSight subscription.
Privacy concerns loom large, as many enterprises are cautious about sharing their internal knowledge base with external providers to safeguard dataintegrity. This delicate balance between outsourcing and data protection remains a pivotal concern. In the next few sections we will go through the main steps in this process.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. Over time, workloads start processing more data, tenants start onboarding more workloads, and administrators (admins) start onboarding more tenants.
Kafka plays a central role in the Stitch Fix efforts to overhaul its event delivery infrastructure and build a self-service dataintegration platform. This post includes much more information on business use cases, architecture diagrams, and technical infrastructure.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Data exploration Data exploration helps unearth inconsistencies, outliers, or errors.
Disaster recovery (DR) is a combination of IT technologies and best practices designed to prevent data loss and minimize business disruption caused by an unexpected event. What is a cyberattack? Threat actors launch cyberattacks for all sorts of reasons, from petty theft to acts of war. But what about cyberattacks?
Customers often use many SQL scripts to select and transform the data in relational databases hosted either in an on-premises environment or on AWS and use custom workflows to manage their ETL. AWS Glue is a serverless dataintegration and ETL service with the ability to scale on demand. Select s3_crawler and choose Run.
The longer answer is that in the context of machine learning use cases, strong assumptions about dataintegrity lead to brittle solutions overall. Flashpoint” (2018) – GDPR went into effect, plus major data blunders happened seemingly everywhere. Apache Atlas is a Hadoop-ish native reference implementation for Egeria.
Achieving this advantage is dependent on their ability to capture, connect, integrate, and convert data into insight for business decisions and processes. This is the goal of a “data-driven” organization. We call this the “ Bad Data Tax ”. This includes the referencedata about business entities, agents, and people.
You can connect to the existing database, upload a data file, anonymize columns and generate as much data as needed to address data gaps or train classical AI models. Will it be implemented on-premises or hosted using a cloud platform? Is it intended for internal team use or to be accessible to external customers?
As the world becomes increasingly digitized, the amount of data being generated on a daily basis is growing at an unprecedented rate. This has led to the emergence of the field of Big Data, which refers to the collection, processing, and analysis of vast amounts of data.
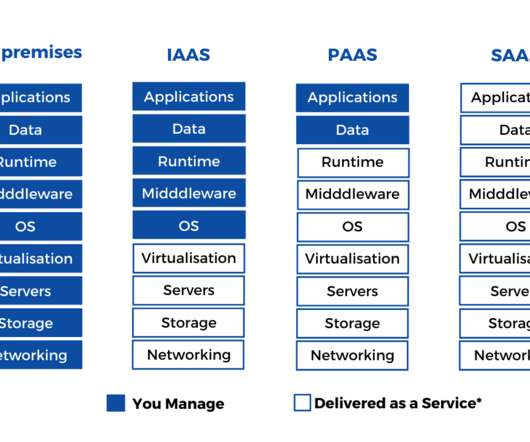
IaaS provides a platform for compute, data storage and networking capabilities. IaaS is mainly used for developing softwares (testing and development, batch processing), hosting web applications and data analysis. This is done to gain better visibility of the operations, and capture data points of interest for the clients.
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating data lakes, serving as object storage for consumer applications, storing logs, and archiving data. Going forward, we refer to this bucket as the primary object bucket.
Protect data at the source. Put data into action to optimize the patient experience and adapt to changing business models. What is Data Governance in Healthcare? Data governance in healthcare refers to how data is collected and used by hospitals, pharmaceutical companies, and other healthcare organizations and service providers.
For this, Cargotec built an Amazon Simple Storage Service (Amazon S3) data lake and cataloged the data assets in AWS Glue Data Catalog. They chose AWS Glue as their preferred dataintegration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
This might be sufficient for information retrieval purposes and simple fact-checking, but if you want to get deeper insights, you need to have normalized data that allows analytics or machine interaction with it. Although there are already established reference datasets in some domains (e.g. Semantic DataIntegration With GraphDB.
On Thursday January 6th I hosted Gartner’s 2022 Leadership Vision for Data and Analytics webinar. Much as the analytics world shifted to augmented analytics, the same is happening in data management. Here is a suggested note: Use Gartner’s Reference Model to Deliver Intelligent Composable Business Applications.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content