This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, DataIntegrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines.
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls. This is where data solutions like Dell AI-Ready Data Platform come in handy.
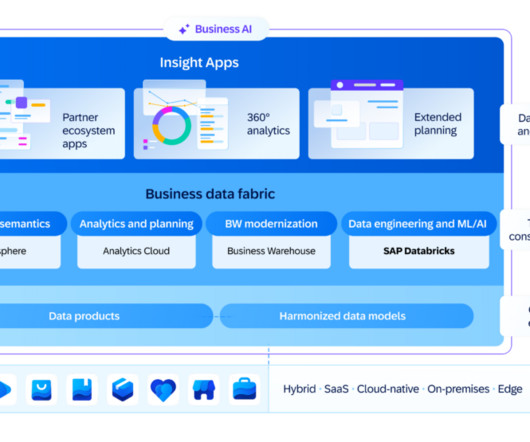
SAP announced today a host of new AI copilot and AI governance features for SAP Datasphere and SAP Analytics Cloud (SAC). Vector embeddings represent data (including unstructureddata like text, images, and videos) as coordinates while capturing their semantic relationships and similarities.
Unstructured. Unstructureddata lacks a specific format or structure. As a result, processing and analyzing unstructureddata is super-difficult and time-consuming. Semi-structured data contains a mixture of both structured and unstructureddata. DataIntegration. Semi-structured.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. . public, private, hybrid cloud)?
IT should be involved to ensure governance, knowledge transfer, dataintegrity, and the actual implementation. Then for knowledge transfer choose the repository, best suited for your organization, to host this information. Ensure data literacy. Because it is that important.
A data lake is a centralized repository that you can use to store all your structured and unstructureddata at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Open AWS Glue Studio. Choose ETL Jobs.
The stringent requirements imposed by regulatory compliance, coupled with the proprietary nature of most legacy systems, make it all but impossible to consolidate these resources onto a data platform hosted in the public cloud. Flexibility.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Introduction.
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic dataintegration , and ontology building.
We offer a seamless integration of the PoolParty Semantic Suite and GraphDB , called the PowerPack bundles. This enables our customers to work with a rich, user-friendly toolset to manage a graph composed of billions of edges hosted in data centers around the world. PowerPack Bundles – What is it and what is included?
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates dataintegration workloads in AWS.
Achieving this advantage is dependent on their ability to capture, connect, integrate, and convert data into insight for business decisions and processes. This is the goal of a “data-driven” organization. We call this the “ Bad Data Tax ”.
AzureDevOps Git integration support – Now allows for connection to AzureDevOps repositories using PAT tokens and enables new content to be amended to existing files from the alter dialog. Improved Data Visibility and Understanding User Interface Enhancements – erwin Data Modeler 14.0
To overcome these issues, Orca decided to build a data lake. A data lake is a centralized data repository that enables organizations to store and manage large volumes of structured and unstructureddata, eliminating data silos and facilitating advanced analytics and ML on the entire data.
Apache Hadoop Apache Hadoop is a Java-based open-source platform used for storing and processing big data. It is based on a cluster system, allowing it to efficiently process data and run it parallelly. It can process structured and unstructureddata from one server to multiple computers and offers cross-platform support to users.
“When I came into the company last November, we went through a data modernization with AWS,” Bostrom says. “We We moved onto the AWS tech stack with both structured and unstructureddata.” Getting data out of legacy systems and into a modern lake house was key to being able to build AI. “If
Business Data Cloud (BDC) consists of multiple existing and new services built by SAP and its partners: Object store which is an OEM from Databricks Databricks Data Engineering and AI/ML Tools SAP Datasphere SAP BW 7.5 Instead, the Databricks object store provides an industry-standard and more cost-efficient solution for storing data.
Assuming the data platform roadmap aligns with required technical capabilities, this may help address downstream issues related to organic competencies versus bigger investments in acquiring competencies. The same would be true for a host of other similar cloud data platforms (Databricks, Azure Data Factory, AWS Redshift).
This configuration allows you to augment your sensitive on-premises data with cloud data while making sure all data processing and compute runs on-premises in AWS Outposts Racks. Additionally, Oktank must comply with data residency requirements, making sure that confidential data is stored and processed strictly on premises.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content