This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Race For DataQuality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer? How do you ensure dataquality in every layer ?
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. Zero-ETL is a set of fully managed integrations by AWS that minimizes the need to build ETL data pipelines.
So its not surprising that 70% of developers say that theyre having problems integrating AI agents with their existing systems. The problem is that, before AI agents can be integrated into a companys infrastructure, that infrastructure must be brought up to modern standards. Not all of that is gen AI, though.
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Maintaining quality and trust is a perennial data management challenge, the importance of which has come into sharper focus in recent years thanks to the rise of artificial intelligence (AI). With the aim of rectifying that situation, Bigeye’s founders set out to build a business around data observability.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, dataquality and master data management. Its code generation architecture uses a visual interface to create Java or SQL code.
Originally applied to manufacturing, this principle holds profound relevance in today’s data-driven world. The idea is simple yet powerful – investing in quality upfront provides a significant saving because it eliminates the need to fix problems after they occur. How about dataquality?
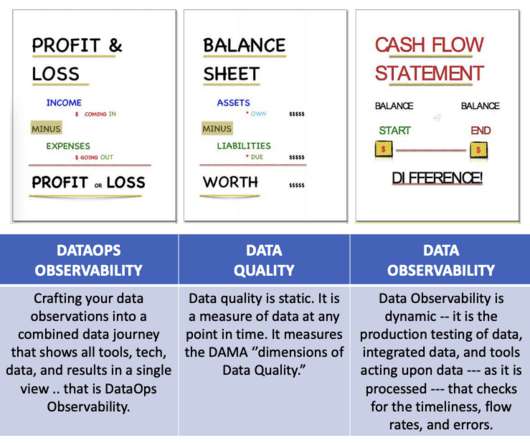
Question: What is the difference between DataQuality and Observability in DataOps? DataQuality is static. It is the measure of data sets at any point in time. A financial analogy: DataQuality is your Balance Sheet, Data Observability is your Cash Flow Statement.
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional dataintegration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
Thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. After a few months, daily sales surpassed 2 million dollars, rendering the threshold obsolete.
Machine learning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Dataintegration and cleaning. Data unification and integration.
On top of that, they are storing data in IT environments that are increasingly complex, including in the cloud and on mainframes, sometimes simultaneously, all while needing to ensure proper security and compliance. How do companies ensure their data landscape is ready for the future? All of this complexity creates a challenge.
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. What is dataintegrity?
However, your dataintegrity practices are just as vital. But what exactly is dataintegrity? How can dataintegrity be damaged? And why does dataintegrity matter? What is dataintegrity? Indeed, without dataintegrity, decision-making can be as good as guesswork.
Companies are no longer wondering if data visualizations improve analyses but what is the best way to tell each data-story. 2020 will be the year of dataquality management and data discovery: clean and secure data combined with a simple and powerful presentation. 1) DataQuality Management (DQM).
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate data lakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. OwlDQ — Predictive dataquality.
Hundreds of thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions.
When internal resources fall short, companies outsource data engineering and analytics. Large enterprises integrate hundreds or thousands of asynchronous data sources into a web of pipelines that flow into visualizations and purpose-built databases that support self-service analysis. Here is where the loss of control begins.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. Data teams struggle to find a unified approach that enables effortless discovery, understanding, and assurance of dataquality and security across various sources.
It’s also a critical trait for the data assets of your dreams. What is data with integrity? Dataintegrity is the extent to which you can rely on a given set of data for use in decision-making. Where can dataintegrity fall short? Too much or too little access to data systems.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s DataQuality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 2: Data Definitions.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Hundreds of thousands of customers use data lakes for analytics and ML to make data-driven business decisions.
This would be straightforward task were it not for the fact that, during the digital-era, there has been an explosion of data – collected and stored everywhere – much of it poorly governed, ill-understood, and irrelevant. Data Centricity. There is evidence to suggest that there is a blind spot when it comes to data in the AI context.
A data catalog serves the same purpose. By using metadata (or short descriptions), data catalogs help companies gather, organize, retrieve, and manage information. You can think of a data catalog as an enhanced Access database or library card catalog system. It helps you locate and discover data that fit your search criteria.
Have you ever experienced that sinking feeling, where you sense if you don’t find dataquality, then dataquality will find you? I hope that you enjoy reading this blog post, but most important, I hope you always remember: “Data are friends, not food.” Data Silos. Good feeling’s gone—AHH!”
Our firm’s leaders] wanted to make sure there were guidelines in place to protect the company, its data, and its people.” “The CIO is at the nexus of those conversations,” says Tim Crawford, CIO strategic adviser at Los Angeles-based IT advisory firm AVOA. Which business cases actually need AI?
Today, data is more valuable to a company than it’s ever been. It can help you make data-driven decisions which can improve business performance, boost revenue, and improve efficiencies. But in the four years since it came into force, have companies reached their full potential for dataintegrity? What is dataintegrity?
This is where the true power of complete data observability comes into play, and it’s time to get acquainted with its two critical parts: ‘Data in Place’ and ‘Data in Use.’ What is Data in Place? There are multiple locations where problems can happen in a data and analytic system.
What is DataQuality? Dataquality is defined as: the degree to which data meets a company’s expectations of accuracy, validity, completeness, and consistency. By tracking dataquality , a business can pinpoint potential issues harming quality, and ensure that shared data is fit to be used for a given purpose.
Extrinsic Control Deficit: Many of these changes stem from tools and processes beyond the immediate control of the data team. Unregulated ETL/ELT Processes: The absence of stringent dataquality tests in ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes further exacerbates the problem.
Collibra was founded in 2008 by Chief Executive Officer Felix Van de Maele and Chief Data Citizen Stijn Christiaens. Removing barriers that prevent or delay users from gaining access to data enables it to be treated as a product that is generated and consumed internally by workers or externally by partners and customers.
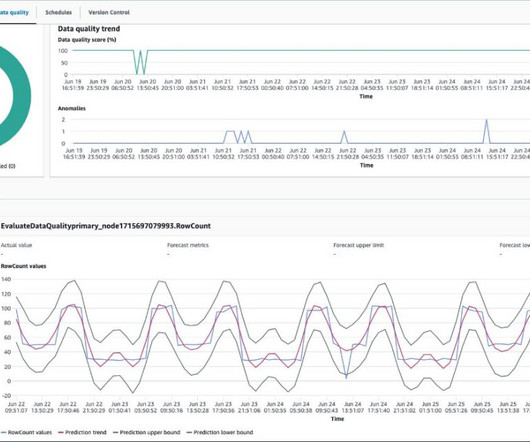
Data errors also affect careers. If you have been in the data profession for any length of time, you probably know what it means to face a mob of stakeholders who are angry about inaccurate or late analytics. Some of the DataOps best practices and industry discussion around errors have coalesced around the term “data observability.”
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
Data contracts are a new idea for data and analytic team development to ensure that data is transmitted accurately and consistently between different systems or teams. One of the primary benefits of using data contracts is that they help to ensure dataintegrity and compatibility.
The Second of Five Use Cases in Data Observability Data Evaluation: This involves evaluating and cleansing new datasets before being added to production. This process is critical as it ensures dataquality from the onset. Examples include regular loading of CRM data and anomaly detection.
When implementing automated validation, AI-driven regression testing, real-time canary pipelines, synthetic data generation, freshness enforcement, KPI tracking, and CI/CD automation, organizations can shift from reactive data observability to proactive dataquality assurance.
Now, picture doing that with a mountain of data. Infused with the magic of artificial intelligence (AI), DataLark revolutionizes data migration, making it faster, more efficient, and surprisingly painless. It involves shifting massive amounts of data from outdated legacy systems to a sleek, modern ERP platform.
Salesforce closes acquisition of Mulesoft – May 2018 (business app vendor acquires dataintegration). But the recent spate of acquisitions just prove the point: the work of data and analytics governance remains an after-thought, even for these large vendors (just as it does for many of their prospects).
In a sea of questionable data, how do you know what to trust? Dataquality tells you the answer. It signals what data is trustworthy, reliable, and safe to use. It empowers engineers to oversee data pipelines that deliver trusted data to the wider organization. Today, as part of its 2022.2
are only starting to exist; one big task over the next two years is developing the IDEs for machine learning, plus other tools for data management, pipeline management, data cleaning, data provenance, and data lineage. GitHub is an excellent tool for managing code, but we need to think about [code+data].
As the pioneer in the DataOps category, we are proud to have laid the groundwork for what has become an essential approach to managing data operations in today’s fast-paced business environment. At DataKitchen, we think of this is a ‘meta-orchestration’ of the code and tools acting upon the data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content