This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Race For DataQuality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer? How do you ensure dataquality in every layer ?
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. What’s the difference between zero-ETL and Glue ETL?
As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor dataquality.
Dependency mapping can uncover where companies are generating incorrect, incomplete, or unnecessary data that only detract from sound decision-making. It can also be helpful to conduct a root cause analysis to identify why dataquality may be slipping in certain areas.
Thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. After a few months, daily sales surpassed 2 million dollars, rendering the threshold obsolete.
Machine learning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Dataintegration and cleaning. Data unification and integration.
Companies are no longer wondering if data visualizations improve analyses but what is the best way to tell each data-story. 2020 will be the year of dataquality management and data discovery: clean and secure data combined with a simple and powerful presentation. 1) DataQuality Management (DQM).
RightData – A self-service suite of applications that help you achieve DataQuality Assurance, DataIntegrity Audit and Continuous DataQuality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines. Data breaks.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate data lakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
Hundreds of thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. We also show how to take action based on the dataquality results.
It’s also a critical trait for the data assets of your dreams. What is data with integrity? Dataintegrity is the extent to which you can rely on a given set of data for use in decision-making. Where can dataintegrity fall short? Too much or too little access to data systems.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Hundreds of thousands of customers use data lakes for analytics and ML to make data-driven business decisions.
How Can I Ensure DataQuality and Gain Data Insight Using Augmented Analytics? There are many business issues surrounding the use of data to make decisions. One such issue is the inability of an organization to gather and analyze data.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. The data science and AI teams are able to explore and use new data sources as they become available through Amazon DataZone.
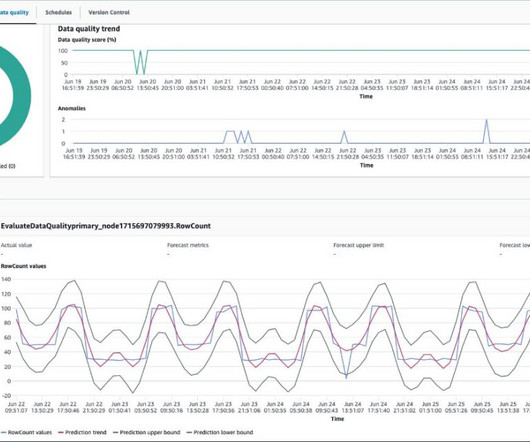
At DataKitchen, we think of this is a ‘meta-orchestration’ of the code and tools acting upon the data. Data Pipeline Observability: Optimizes pipelines by monitoring dataquality, detecting issues, tracing data lineage, and identifying anomalies using live and historical metadata.
L1 is usually the raw, unprocessed data ingested directly from various sources; L2 is an intermediate layer featuring data that has undergone some form of transformation or cleaning; and L3 contains highly processed, optimized, and typically ready for analytics and decision-making processes. What is Data in Use?
This also includes building an industry standard integrateddata repository as a single source of truth, operational reporting through real time metrics, dataquality monitoring, 24/7 helpdesk, and revenue forecasting through financial projections and supply availability projections. 2 GB into the landing zone daily.
Dataquality for account and customer data – Altron wanted to enable dataquality and data governance best practices. Goals – Lay the foundation for a data platform that can be used in the future by internal and external stakeholders.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
We won’t be writing code to optimize scheduling in a manufacturing plant; we’ll be training ML algorithms to find optimum performance based on historical data. With machine learning, the challenge isn’t writing the code; the algorithms are implemented in a number of well-known and highly optimized libraries.
Using data fabric also provides advanced analytics for market forecasting, product development, sale and marketing. Moreover, it is important to note that data fabric is not a one-time solution to fix dataintegration and management issues. Other important advantages of data fabric are as follows.
Make sure the data and the artifacts that you create from data are correct before your customer sees them. It’s not about dataquality . In governance, people sometimes perform manual dataquality assessments. It’s not only about the data. DataQuality. Location Balance Tests.
However, the foundation of their success rests not just on sophisticated algorithms or computational power but on the quality and integrity of the data they are trained on and interact with. The Role of Data Journeys in RAG The underlying data must be meticulously managed throughout its journey for RAG to function optimally.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. Informatica Axon Informatica Axon is a collection hub and data marketplace for supporting programs.
Agile BI and Reporting, Single Customer View, Data Services, Web and Cloud Computing Integration are scenarios where Data Virtualization offers feasible and more efficient alternatives to traditional solutions. Does Data Virtualization support web dataintegration? In improving operational processes.
Here, I’ll highlight the where and why of these important “dataintegration points” that are key determinants of success in an organization’s data and analytics strategy. Layering technology on the overall data architecture introduces more complexity. Data and cloud strategy must align.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables. It is essential for optimizing read and write performance.
By providing real-time visibility into the performance and behavior of data-related systems, DataOps observability enables organizations to identify and address issues before they become critical, and to optimize their data-related workflows for maximum efficiency and effectiveness.
Challenges in Achieving Data-Driven Decision-Making While the benefits are clear, many organizations struggle to become fully data-driven. Challenges such as data silos, inconsistent dataquality, and a lack of skilled personnel can create significant barriers.
Side benefits include improved dataquality, the ability to develop a centralized data retention policy, and improved security across data assets, Rudy says. Tips for success Those who’ve successfully broken down data silos suggest a few best practices for undertaking such initiatives.
However, if we’ve learned anything, isn’t it that data governance is an ever-evolving, ever-changing tenet of modern business? We explored the bottlenecks and issues causing delays across the entire data value chain. Data governance provides visibility, automation, governance and collaboration for data democratization.
Despite soundings on this from leading thinkers such as Andrew Ng , the AI community remains largely oblivious to the important data management capabilities, practices, and – importantly – the tools that ensure the success of AI development and deployment. Further, data management activities don’t end once the AI model has been developed.
My advice to leaders is to identify areas with the largest potential and impact, assess the readiness of data, build or deploy existing solutions that leverage AI, and make sure you are rethinking how people will work differently with these new capabilities right from the beginning of your initiative.
At Vanguard, “data and analytics enable us to fulfill on our mission to provide investors with the best chance for investment success by enabling us to glean actionable insights to drive personalized client experiences, scale advice, optimize investment and business operations, and reduce risk,” Swann says.
With the growing interconnectedness of people, companies and devices, we are now accumulating increasing amounts of data from a growing variety of channels. New data (or combinations of data) enable innovative use cases and assist in optimizing internal processes. However, effectively using data needs to be learned.
Prior to the creation of the data lake, Orca’s data was distributed among various data silos, each owned by a different team with its own data pipelines and technology stack. Moreover, running advanced analytics and ML on disparate data sources proved challenging.
Points of integration. Without an accurate, high-quality, real-time enterprise data pipeline, it will be difficult to uncover the necessary intelligence to make optimal business decisions. So what’s holding organizations back from fully using their data to make better, smarter business decisions? Regulations.
This introduces the need for both polling and pushing the data to access and analyze in near-real time. From an operational standpoint, we designed a new shared responsibility model for data ingestion using AWS Glue instead of internal services (REST APIs) designed on Amazon EC2 to extract the data.
A market in need of more interoperability Systems integrators and cloud services teams have stepped in to remedy some of multicloud’s interoperability hurdles, but the optimal solution is for public cloud providers to build APIs directly into the cloud stack layer, Gartner’s Nag says.
Here are some common cost areas where data lineage can be beneficial: Infrastructure and storage costs: Data lineage allows organizations to understand data usage patterns, access frequencies, and data dependencies. Dataquality costs: Poor dataquality can result in significant costs for organizations.
Then virtualize your data to allow business users to conduct aggregated searches and analyses using the business intelligence or data analytics tools of their choice. . Set up unified data governance rules and processes. With dataintegration comes a requirement for centralized, unified data governance and security.
The data is feeding AI predictions around everything from the optimal batting lineup against a starting pitcher, and optimal defensive positioning against a given batter facing a given pitcher, to injury prediction.
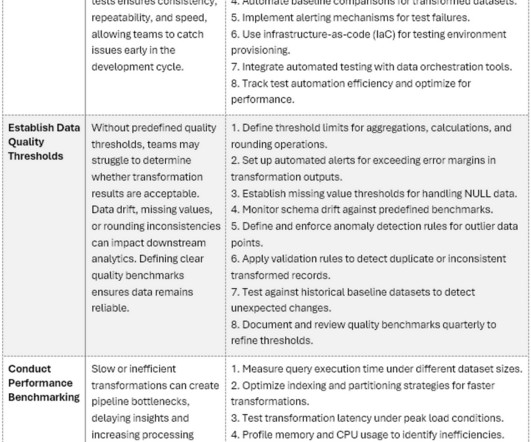
However, errors in transformations and conversions can propagate through entire data ecosystems, leading to inaccurate reports, flawed analytics, and broken downstream processes. This article presents two essential frameworks that guide teams in testing and validating data transformations and conversions.
Another way to look at the five pillars is to see them in the context of a typical complex data estate. Using automated data validation tests, you can ensure that the data stored within your systems is accurate, complete, consistent, and relevant to the problem at hand. Data engineers are unable to make these business judgments.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content