This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
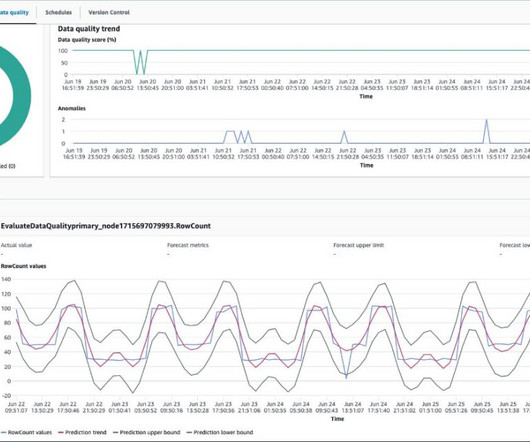
The Race For DataQuality In A Medallion Architecture The Medallion architecture pattern is gaining traction among data teams. It is a layered approach to managing and transforming data. It sounds great, but how do you prove the data is correct at each layer? How do you ensure dataquality in every layer ?
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. What’s the difference between zero-ETL and Glue ETL?
They made us realise that building systems, processes and procedures to ensure quality is built in at the outset is far more cost effective than correcting mistakes once made. How about dataquality? Redman and David Sammon, propose an interesting (and simple) exercise to measure dataquality.
Machine learning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Dataintegration and cleaning. Data unification and integration.
Thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. After a few months, daily sales surpassed 2 million dollars, rendering the threshold obsolete.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate data lakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
Companies are no longer wondering if data visualizations improve analyses but what is the best way to tell each data-story. 2020 will be the year of dataquality management and data discovery: clean and secure data combined with a simple and powerful presentation. 1) DataQuality Management (DQM).
Hundreds of thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. We also show how to take action based on the dataquality results.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s DataQuality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 2: Data Definitions.
Data contracts are a new idea for data and analytic team development to ensure that data is transmitted accurately and consistently between different systems or teams. One of the primary benefits of using data contracts is that they help to ensure dataintegrity and compatibility.
An automated process that catches errors early in the process gives the data team the maximum available time to resolve the problem – patch the data, contact data suppliers, and rerun processing steps. We liken this methodology to the statistical process controls advocated by management guru Dr. Edward Deming.
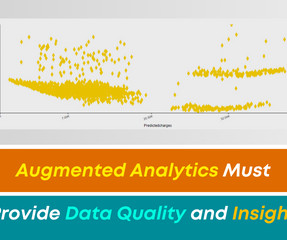
How Can I Ensure DataQuality and Gain Data Insight Using Augmented Analytics? There are many business issues surrounding the use of data to make decisions. One such issue is the inability of an organization to gather and analyze data.
One surprising statistic from the Rand Corporation is that 80% of artificial intelligence (AI). appeared first on Data Management Blog - DataIntegration and Modern Data Management Articles, Analysis and Information. The post How Do You Know When You’re Ready for AI?
Data is the new oil and organizations of all stripes are tapping this resource to fuel growth. However, dataquality and consistency are one of the top barriers faced by organizations in their quest to become more data-driven. Unlock qualitydata with IBM. and its leading data observability offerings.
The Matillion dataintegration and transformation platform enables enterprises to perform advanced analytics and business intelligence using cross-cloud platform-as-a-service offerings such as Snowflake. DataOps recommends that tests monitor data continuously in addition to checks performed when pipelines are run on demand.
Many large organizations, in their desire to modernize with technology, have acquired several different systems with various data entry points and transformation rules for data as it moves into and across the organization. The CEO also makes decisions based on performance and growth statistics. DataQuality.
Residual plots place input data and predictions into a two-dimensional visualization where influential outliers, data-quality problems, and other types of bugs often become plainly visible. Small residuals usually mean a model is right, and large residuals usually mean a model is wrong.
High variance in a model may indicate the model works with training data but be inadequate for real-world industry use cases. Limited data scope and non-representative answers: When data sources are restrictive, homogeneous or contain mistaken duplicates, statistical errors like sampling bias can skew all results.
Dataintegration If your organization’s idea of dataintegration is printing out multiple reports and manually cross-referencing them, you might not be ready for a knowledge graph. As a statistical model, LLM inherently is random. So, we’ve learned our lesson. How do you do that?
Dataquality for account and customer data – Altron wanted to enable dataquality and data governance best practices. Goals – Lay the foundation for a data platform that can be used in the future by internal and external stakeholders.
This ensures that each change is tracked and reversible, enhancing data governance and auditability. History and versioning : Iceberg’s versioning feature captures every change in table metadata as immutable snapshots, facilitating dataintegrity, historical views, and rollbacks.
Business users cannot even hope to prepare data for analytics – at least not without the right tools. Gartner predicts that, ‘data preparation will be utilized in more than 70% of new dataintegration projects for analytics and data science.’ So, why is there so much attention paid to the task of data preparation?
Can the current state of our data operations deliver the results we seek? Another tough topic that CIOs are having to surface to their colleagues: how problems with enterprise dataquality stymie their AI ambitions. 1 among the top three risks — followed by statistical validity and model accuracy.
Whether you work remotely all the time or just occasionally, data encryption helps you stop information from falling into the wrong hands. It Supports DataIntegrity. Something else to keep in mind about encryption technology for data protection is that it helps increase the integrity of the information alone.
We also go into exploratory data analysis and statistical methodologies for discovering problems that simpler checks overlook and end-to-end or regression testing with production-like data to ensure real-world reliability. Key Tools & Processes Data profiling tools (e.g., Statistical tests (e.g.,
Businesses of all sizes, in all industries are facing a dataquality problem. 73% of business executives are unhappy with dataquality and 61% of organizations are unable to harness data to create a sustained competitive advantage 1. The data observability difference .
While many tools exist for basic data validationssuch as null checks, referential integrity, and common schema compliancemany advanced or domain-specific transformation scenarios remain insufficiently served by commercial and open-source testing solutions. Real-time data qualitychecks 2.
The Billie BI team has decided to share the code for their testing project to help other data teams using Sisense for Cloud Data Teams. “We We believe this can help teams be more proactive and increase the dataquality in their companies,” said Ivan. He works on reporting, analysis, and data modeling.
All Machine Learning uses “algorithms,” many of which are no different from those used by statisticians and data scientists. The difference between traditional statistical, probabilistic, and stochastic modeling and ML is mainly in computation. Recently, Judea Pearl said, “All ML is just curve fitting.” Conclusion.
The value of an AI-focused analytics solution can only be fully realized when a business has ensured dataquality and integration of data sources, so it will be important for businesses to choose an analytics solution and service provider that can help them achieve these goals.
Key features: As a professional data analysis tool, FineBI successfully meets business people’s flexible and changeable data processing requirements through self-service datasets. FineBI is supported by a high-performance Spider engine to extract, calculate and analyze a large volume of data with lightweight architecture.
Creating a single view of any data, however, requires the integration of data from disparate sources. Dataintegration is valuable for businesses of all sizes due to the many benefits of analyzing data from different sources. But dataintegration is not trivial. Establishes Trust in Data.
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into data validation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
If you add in IBM data governance solutions, the top left will look a bit more like this: The data governance solution powered by IBM Knowledge Catalog offers several capabilities to help facilitate advanced data discovery, automated dataquality and data protection. and watsonx.data.
It’s only when companies take their first stab at manually cataloging and documenting operational systems, processes and the associated data, both at rest and in motion, that they realize how time-consuming the entire data prepping and mapping effort is, and why that work is sure to be compounded by human error and dataquality issues.
Data cleansing is the process of identifying and correcting errors, inconsistencies, and inaccuracies in a dataset to ensure its quality, accuracy, and reliability. This process is crucial for businesses that rely on data-driven decision-making, as poor dataquality can lead to costly mistakes and inefficiencies.
This “analysis” is made possible in large part through machine learning (ML); the patterns and connections ML detects are then served to the data catalog (and other tools), which these tools leverage to make people- and machine-facing recommendations about data management and dataintegrations. Simply put?
Data Classification. Data Consistency. Data Controls. Data Curation (contributor: Tenny Thomas Soman ). Data Democratisation. Data Dictionary. Data Engineering. Data Ethics. DataIntegrity. Data Lineage. Data Platform. Data Strategy. Information Governance.
We found anecdotal data that suggested things such as a) CDO’s with a business, more than a technical, background tend to be more effective or successful, and b) CDOs most often came from a business background, and c) those that were successful had a good chance at becoming CEO or CEO or some other CXO (but not really CIO).
If we dig deeper, we find that two factors are really at work: Causal data versus correlated dataData maturity as it relates to business outcomes. One of the most fundamental tenets of statistical methods in the last century has focused on correlation to determine causation.
If you have multiple databases from different touchpoints, you should look for a tool that will allow dataintegration no matter the amount of information you want to include. Besides connecting the data, the discovery tool you choose should also support working with big amounts of data. Why are they important?
Batch processing pipelines are designed to decrease workloads by handling large volumes of data efficiently and can be useful for tasks such as data transformation, data aggregation, dataintegration , and data loading into a destination system. How is ELT different from ETL?
Data Cleansing Imperative: The same report revealed that organizations recognized the importance of dataquality, with 71% expressing concerns about dataquality issues. This underscores the need for robust data cleansing solutions.
DataOps Observability includes monitoring and testing the data pipeline, dataquality, data testing, and alerting. Data testing is an essential aspect of DataOps Observability; it helps to ensure that data is accurate, complete, and consistent with its specifications, documentation, and end-user requirements.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content