This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, dataquality and master data management. Its code generation architecture uses a visual interface to create Java or SQL code.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. What’s the difference between zero-ETL and Glue ETL?
Data exploded and became big. Spreadsheets finally took a backseat to actionable and insightful datavisualizations and interactive business dashboards. The rise of self-service analytics democratized the data product chain. 1) DataQuality Management (DQM). We all gained access to the cloud.
Thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. After a few months, daily sales surpassed 2 million dollars, rendering the threshold obsolete.
Dependency mapping can uncover where companies are generating incorrect, incomplete, or unnecessary data that only detract from sound decision-making. It can also be helpful to conduct a root cause analysis to identify why dataquality may be slipping in certain areas.
There are countless examples of big data transforming many different industries. It can be used for something as visual as reducing traffic jams, to personalizing products and services, to improving the experience in multiplayer video games. We would like to talk about datavisualization and its role in the big data movement.
We are excited to announce the General Availability of AWS Glue DataQuality. Our journey started by working backward from our customers who create, manage, and operate data lakes and data warehouses for analytics and machine learning. It takes days for data engineers to identify and implement dataquality rules.
There’s no shortage of consultants who will promise to manage the end-to-end lifecycle of data from integration to transformation to visualization. . The challenge is that data engineering and analytics are incredibly complex. For example, DataOps can be used to automate dataintegration.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. OwlDQ — Predictive dataquality.
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
Hundreds of thousands of organizations build dataintegration pipelines to extract and transform data. They establish dataquality rules to ensure the extracted data is of high quality for accurate business decisions. We also show how to take action based on the dataquality results.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. Having confidence in your data is key.
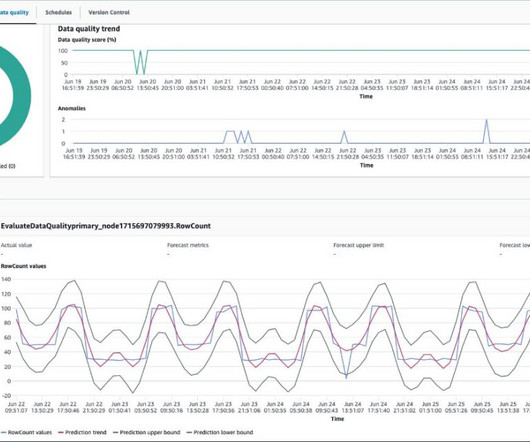
How Can I Ensure DataQuality and Gain Data Insight Using Augmented Analytics? There are many business issues surrounding the use of data to make decisions. One such issue is the inability of an organization to gather and analyze data.
These layers help teams delineate different stages of data processing, storage, and access, offering a structured approach to data management. In the context of Data in Place, validating dataquality automatically with Business Domain Tests is imperative for ensuring the trustworthiness of your data assets.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. The data science and AI teams are able to explore and use new data sources as they become available through Amazon DataZone.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Hundreds of thousands of customers use data lakes for analytics and ML to make data-driven business decisions.
Collibra was founded in 2008 by Chief Executive Officer Felix Van de Maele and Chief Data Citizen Stijn Christiaens. Self-service access to data is only truly valuable if users can trust the data they have access to, however. Collibra also announced the acquisition of Husprey in 2023 for its SQL data notebook functionality.
A robust process checks source data and work-in-progress at each processing step along the way to polished visualizations, charts, and graphs. Figure 1: The process of transforming raw data into actionable business intelligence is a manufacturing process. It’s not about dataquality . It’s not only about the data.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. Informatica Axon Informatica Axon is a collection hub and data marketplace for supporting programs.
Partial dependence, accumulated local effect (ALE), and individual conditional expectation (ICE) plots : this involves systematically visualizing the effects of changing one or more variables in your model. There are a ton of packages for these techniques: ALEPlot , DALEX , ICEbox , iml , and pdp in R; and PDPbox and PyCEbox in Python.
And if it isnt changing, its likely not being used within our organizations, so why would we use stagnant data to facilitate our use of AI? The key is understanding not IF, but HOW, our data fluctuates, and data observability can help us do just that. And lets not forget about the controls.
Challenges in Achieving Data-Driven Decision-Making While the benefits are clear, many organizations struggle to become fully data-driven. Challenges such as data silos, inconsistent dataquality, and a lack of skilled personnel can create significant barriers.
Many large organizations, in their desire to modernize with technology, have acquired several different systems with various data entry points and transformation rules for data as it moves into and across the organization. Seeing data pipelines and information flows further supports compliance efforts. DataQuality.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless dataintegration engine.
IT should be involved to ensure governance, knowledge transfer, dataintegrity, and the actual implementation. Clean data in, clean analytics out. Cleaning your data may not be quite as simple, but it will ensure the success of your BI. Indeed, every year low-qualitydata is estimated to cost over $9.7
This ensures that each change is tracked and reversible, enhancing data governance and auditability. History and versioning : Iceberg’s versioning feature captures every change in table metadata as immutable snapshots, facilitating dataintegrity, historical views, and rollbacks.
Movement of data across data lakes, data warehouses, and purpose-built stores is achieved by extract, transform, and load (ETL) processes using dataintegration services such as AWS Glue. AWS Glue provides both visual and code-based interfaces to make dataintegration effortless.
Another way to look at the five pillars is to see them in the context of a typical complex data estate. Using automated data validation tests, you can ensure that the data stored within your systems is accurate, complete, consistent, and relevant to the problem at hand. Data engineers are unable to make these business judgments.
And it exists across these hybrid architectures in different formats: big and unstructured and traditional structured business data may physically sit in different places. What’s desperately needed is a way to understand the relationships and interconnections between so many entities in data sets in detail.
Migrating workloads to AWS Glue AWS Glue is a serverless dataintegration service that helps analytics users to discover, prepare, move, and integratedata from multiple sources. With AWS Glue, you can discover and connect to hundreds of different data sources and manage your data in a centralized data catalog.
Paradoxically, even without a shared definition and common methodology, the knowledge graph (and its discourse) has steadily settled in the discussion about data management, dataintegration and enterprise digital transformation. Clean your data to ensure dataquality. Maximize the usability of your data.
Business users cannot even hope to prepare data for analytics – at least not without the right tools. Gartner predicts that, ‘data preparation will be utilized in more than 70% of new dataintegration projects for analytics and data science.’ So, why is there so much attention paid to the task of data preparation?
Data and its various uses is increasingly evident in companies, and each professional has their preferences about which technologies to use to visualizedata, which isn’t necessarily in line with the technological needs and infrastructure of a company. In this post, we discuss why we chose QuickSight and how we implemented it.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Implement data privacy policies. Implement dataquality by data type and source.
While compliance is the major driver for data governance, it bears the risk of reducing it to a very restrictive procedure. Dataquality is the top challenge when it comes to using data, closely followed by organizational issues. Inadequate dataquality remains the foremost challenge users face when using data.
The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. Read: The first capability of a data fabric is a semantic knowledge data catalog, but what are the other 5 core capabilities of a data fabric? What’s a data mesh?
A Gartner Marketing survey found only 14% of organizations have successfully implemented a C360 solution, due to lack of consensus on what a 360-degree view means, challenges with dataquality, and lack of cross-functional governance structure for customer data.
MuleSoft’s historic strength is in dataintegration and API management: enterprises such as Decathlon and REA Group use its Anypoint Platform to build modular systems and automate critical business processes. We’re improving dataquality and accessibility and enabling our business to use the data strategically and at scale,” she said.
Another podcast we think is worth a listen is Agile Data. Throughout each episode, hosts Shane and Nigel discuss how to incorporate agile techniques when teams deliver analytics, data, and visualizations. Topics they chat about include: going serverless, data layers, and how to adapt for a “BI Lifecycle.”
By analyzing this information, organizations can optimize their infrastructure and storage strategies, avoiding unnecessary storage costs and efficiently allocating resources based on data usage patterns. Dataintegration and ETL costs: Large organizations often deal with complex dataintegration and Extract, Transform, Load (ETL) processes.
Data governance tools are available to help ensure availability, usability, consistency, dataintegrity and data security. This helps establish clear processes for effective data management throughout the enterprise. The data journey governed.
The power of artificial intelligence (AI) lies within its ability to make sense of large amounts of data. For the increasing support of planning, budgeting and controlling processes through advanced analytics and AI solutions, powerful data management and dataintegration are an indispensable prerequisite.
These use cases provide a foundation that delivers a rich and intuitive data shopping experience. This data marketplace capability will enable organizations to efficiently deliver high quality governed data products at scale across the enterprise. Multicloud dataintegration. million each year [1] and $1.2
Data Pipeline Use Cases Here are just a few examples of the goals you can achieve with a robust data pipeline: Data Prep for VisualizationData pipelines can facilitate easier datavisualization by gathering and transforming the necessary data into a usable state.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content