This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegrationtransforms ETL workflow development.
The dataintegration landscape is under a constant metamorphosis. In the current disruptive times, businesses depend heavily on information in real-time and data analysis techniques to make better business decisions, raising the bar for dataintegration. Why is DataIntegration a Challenge for Enterprises?
Today, we’re excited to announce general availability of Amazon Q dataintegration in AWS Glue. Amazon Q dataintegration, a new generative AI-powered capability of Amazon Q Developer , enables you to build dataintegration pipelines using natural language.
We live in a world of data: There’s more of it than ever before, in a ceaselessly expanding array of forms and locations. Dealing with Data is your window into the ways data teams are tackling the challenges of this new world to help their companies and their customers thrive. What is dataintegrity?
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machine learning and generative AI. Dataintegrity presented a major challenge for the team, as there were many instances of duplicate data.
A high hurdle many enterprises have yet to overcome is accessing mainframe data via the cloud. Data professionals need to access and work with this information for businesses to run efficiently, and to make strategic forecasting decisions through AI-powered data models.
Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. In this scenario, you’re a data analyst in this company.
This project represents a transformative initiative designed to address the evolving landscape of cyber threats,” says Kunal Krushev, head of cybersecurity automation and intelligence with the firm’s Corporate IT — Digital Infrastructure Services. “We The initiative brought multiple capabilities to the firm’s security operations.
How dbt Core aids data teams test, validate, and monitor complex datatransformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based datatransformations, has become a must-have tool for modern data teams as the complexity of data pipelines grows.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
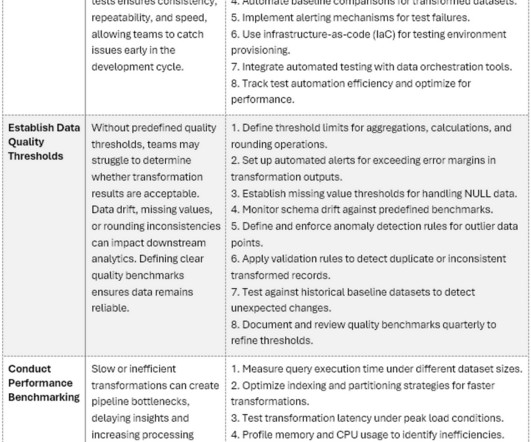
Complex Data TransformationsTest Planning Best Practices Ensuring data accuracy with structured testing and best practices Photo by Taylor Vick on Unsplash Introduction Datatransformations and conversions are crucial for data pipelines, enabling organizations to process, integrate, and refine raw data into meaningful insights.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
Movement of data across data lakes, data warehouses, and purpose-built stores is achieved by extract, transform, and load (ETL) processes using dataintegration services such as AWS Glue. AWS Glue provides both visual and code-based interfaces to make dataintegration effortless.
Common challenges and practical mitigation strategies for reliable datatransformations. Photo by Mika Baumeister on Unsplash Introduction Datatransformations are important processes in data engineering, enabling organizations to structure, enrich, and integratedata for analytics , reporting, and operational decision-making.
Managing tests of complex datatransformations when automated data testing tools lack important features? Photo by Marvin Meyer on Unsplash Introduction Datatransformations are at the core of modern business intelligence, blending and converting disparate datasets into coherent, reliable outputs.
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-quality data as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage.
AI is transforming how senior data engineers and data scientists validate datatransformations and conversions. Artificial intelligence-based verification approaches aid in the detection of anomalies, the enforcement of dataintegrity, and the optimization of pipelines for improved efficiency.
Implement a communication protocol that swiftly informs stakeholders, allowing them to brace for or address the potential impacts of the data change. Building a Culture of Accountability: Encourage a culture where dataintegrity is everyone’s responsibility.
To deal with this issue, GraphDB implements a smart Graph Replace optimization that helps you calculate the internal data and only shows you the newly added and removed statements. The Soft Deletes and Versioning has the benefit of keeping track of the full history of your data, but your repository will become extremely big.
Data-driven companies sense change through data analytics. Companies turn to their data organization to provide the analytics that stimulates creative problem-solving. Companies turn to their data organization to provide the analytics that stimulates creative problem-solving. – Leon C. Adapt or face decline.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity. Choose Add data. Choose Save changes.
These issues dont just hinder next-gen analytics and AI; they erode trust, delay transformation and diminish business value. Data quality is no longer a back-office concern. In this article, I am drawing from firsthand experience working with CIOs, CDOs, CTOs and transformation leaders across industries.
We counted ten ‘standard’ ways to transform and set up batch data pipelines in Microsoft Azure. Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based dataintegration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation.
Hundreds of thousands of customers use AWS Glue , a serverless dataintegration service, to discover, prepare, and combine data for analytics, machine learning (ML), and application development. AWS Glue for Apache Spark jobs work with your code and configuration of the number of data processing units (DPU). Generally, G.2X
AWS Glue A dataintegration service, AWS Glue consolidates major dataintegration capabilities into a single service. These include data discovery, modern ETL, cleansing, transforming, and centralized cataloging. We used it for executing long-running scripts, such as for ingesting data from an external API.
There are countless examples of big datatransforming many different industries. There is no disputing the fact that the collection and analysis of massive amounts of unstructured data has been a huge breakthrough. We would like to talk about data visualization and its role in the big data movement.
The emergence of generative AI prompted several prominent companies to restrict its use because of the mishandling of sensitive internal data. Currently, no standardized process exists for overcoming data ingestion’s challenges, but the model’s accuracy depends on it. A popular method is extract, load, transform (ELT).
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose datatransformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless dataintegration engine.
Dataintegration is the foundation of robust data analytics. It encompasses the discovery, preparation, and composition of data from diverse sources. In the modern data landscape, accessing, integrating, and transformingdata from diverse sources is a vital process for data-driven decision-making.
For years, IT and business leaders have been talking about breaking down the data silos that exist within their organizations. Given the importance of sharing information among diverse disciplines in the era of digital transformation, this concept is arguably as important as ever.
With Amazon AppFlow, you can run data flows at nearly any scale and at the frequency you chooseon a schedule, in response to a business event, or on demand. You can configure datatransformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps.
The company’s orthodontics business, for instance, makes heavy use of image processing to the point that unstructured data is growing at a pace of roughly 20% to 25% per month. For example, imaging data can be used to show patients how an aligner will change their appearance over time. “It
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
What is data analytics? Data analytics is a discipline focused on extracting insights from data. It comprises the processes, tools and techniques of data analysis and management, including the collection, organization, and storage of data. What are the four types of data analytics? Data analytics tools.
Customers are increasingly demanding access to real-time data, and freight transportation provider Estes Express Lines is among the rising tide of enterprises overhauling their data operations to deliver it. While the company had a data warehouse, it was primarily used for analysis.
Data lineage is the journey data takes from its creation through its transformations over time. Tracing the source of data is an arduous task. With all these diverse data sources, and if systems are integrated, it is difficult to understand the complicated data web they form much less get a simple visual flow.
Unfortunately, the road to data strategy success is fraught with challenges, so CIOs and other technology leaders need to plan and execute carefully. Here are some data strategy mistakes IT leaders would be wise to avoid. Overlooking these data resources is a big mistake. It will not be something they can ignore.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. These query patterns and concurrency were unpredictable in nature.
ChatGPT> DataOps, or data operations, is a set of practices and technologies that organizations use to improve the speed, quality, and reliability of their data analytics processes. One of the key benefits of DataOps automation is the ability to speed up the development and deployment of data-driven solutions.
In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow , a fully managed dataintegration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery.
.” The Data Strategy HealthCo, like many forward-thinking organizations, recognized early on that data is not just a valuable asset but a strategic imperative. They put data at the forefront of their business, integrating it into decision-making processes, products, and services.
Observability is a methodology for providing visibility of every journey that data takes from source to customer value across every tool, environment, data store, team, and customer so that problems are detected and addressed immediately. Data journey observability is the first step in implementing DataOps.
This means we can double down on our strategy – continuing to win the Hybrid Data Cloud battle in the IT department AND building new, easy-to-use cloud solutions for the line of business. It also means we can complete our business transformation with the systems, processes and people that support a new operating model. .
AWS Glue is a serverless dataintegration service that helps analytics users to discover, prepare, move, and integratedata from multiple sources for analytics, machine learning (ML), and application development. The data will be in the target S3 bucket. The event and venue files are from the TICKIT dataset.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content