This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
The growing volume of data is a concern, as 20% of enterprises surveyed by IDG are drawing from 1000 or more sources to feed their analytics systems. Dataintegration needs an overhaul, which can only be achieved by considering the following gaps. Heterogeneous sources produce data sets of different formats and structures.
Currently, a handful of startups offer “reverse” extract, transform, and load (ETL), in which they copy data from a customer’s datawarehouse or data platform back into systems of engagement where business users do their work. Sharing Customer 360 insights back without data replication.
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data from software as a service (SaaS) applications, such as Google BigQuery, Salesforce, SAP, HubSpot, and ServiceNow, to Amazon Web Services (AWS) services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, in just a few clicks.
This week SnapLogic posted a presentation of the 10 Modern DataIntegration Platform Requirements on the company’s blog. They are: Application integration is done primarily through REST & SOAP services. Large-volume dataintegration is available to Hadoop-based data lakes or cloud-based datawarehouses.
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. The following Diagram 4 shows this workflow.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools.
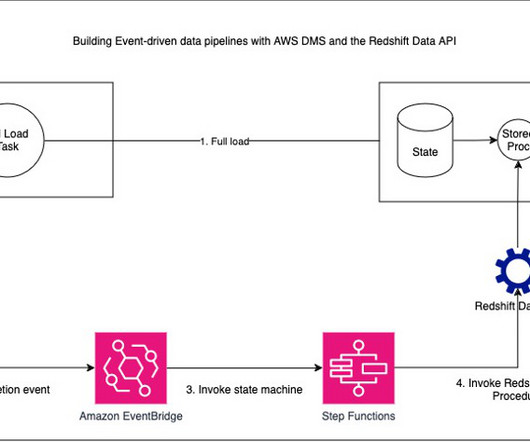
AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster. The data in the central datawarehouse in Amazon Redshift is then processed for analytical needs and the metadata is shared to the consumers through Amazon DataZone.
Investment in datawarehouses is rapidly rising, projected to reach $51.18 billion by 2028 as the technology becomes a vital cog for enterprises seeking to be more data-driven by using advanced analytics. Datawarehouses are, of course, no new concept. More data, more demanding. “As
As data volumes and use cases scale especially with AI and real-time analytics trust must be an architectural principle, not an afterthought. Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Datawarehouse Centralized, structured and curated data repository.
Users today are asking ever more from their datawarehouse. As an example of this, in this post we look at Real Time Data Warehousing (RTDW), which is a category of use cases customers are building on Cloudera and which is becoming more and more common amongst our customers. Ingest 100s of TB of network eventdata per day .
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
Agile BI and Reporting, Single Customer View, Data Services, Web and Cloud Computing Integration are scenarios where Data Virtualization offers feasible and more efficient alternatives to traditional solutions. Does Data Virtualization support web dataintegration? In forecasting future events.
In today’s data-driven world, seamless integration and transformation of data across diverse sources into actionable insights is paramount. You will load the eventdata from the SFTP site, join it to the venue data stored on Amazon S3, apply transformations, and store the data in Amazon S3.
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
This premier event showcased groundbreaking advancements, keynotes from AWS leadership, hands-on technical sessions, and exciting product launches. Analytics remained one of the key focus areas this year, with significant updates and innovations aimed at helping businesses harness their data more efficiently and accelerate insights.
Top Big Data CRM Integration Tools in 2021: #1 MuleSoft: Mulesoft is a dataintegration platform owned by Salesforce to accelerate digital customer transformations. This tool is designed to connect various data sources, enterprise applications and perform analytics and ETL processes.
Here, I’ll highlight the where and why of these important “dataintegration points” that are key determinants of success in an organization’s data and analytics strategy. For datawarehouses, it can be a wide column analytical table. Data and cloud strategy must align.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Document the entire disaster recovery process.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
You also need services to store data for analysis and machine learning (ML) like Amazon Simple Storage Service (Amazon S3). Customers have created hundreds of thousands of data lakes on Amazon S3. Within seconds of data being written into Aurora, you can use Amazon Redshift to do near-real-time analytics and ML on petabytes of data.
Visit us at the AWS Analytics Kiosk in the AWS Village at the Expo to discover the AWS Analytics Superhero in you, participate in a playful quiz and AWS book signing events. 11:30 AM – 12:30 PM (PDT) Ceasars Forum ANT318 | Accelerate innovation with end-to-end serverless data architecture. Watch this space for additional details.
Data management consultancy, BitBang, says CDPs offer five key benefits : As a central hub for all your customer data, they help you build unified customer profiles. They eliminate data silos, and, unlike a traditional datawarehouse, CDPs don’t require technical expertise to set up or maintain. Types of CDPs.
In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow , a fully managed dataintegration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery.
Source systems Aruba’s source repository includes data from three different operating regions in AMER, EMEA, and APJ, along with one worldwide (WW) data pipeline from varied sources like SAP S/4 HANA, Salesforce, Enterprise DataWarehouse (EDW), Enterprise Analytics Platform (EAP) SharePoint, and more.
Enterprises and organizations across the globe want to harness the power of data to make better decisions by putting data at the center of every decision-making process. However, throughout history, data services have held dominion over their customers’ data. They decided to focus on four runtime engines.
Datawarehouses play a vital role in healthcare decision-making and serve as a repository of historical data. A healthcare datawarehouse can be a single source of truth for clinical quality control systems. What is a dimensional data model? What is a dimensional data model?
What is less frequently mentioned is that during this same time we have also seen a rapid increase of cloud services where data needs to be delivered (data lakes, lakehouses, cloud warehouses, cloud streaming systems, cloud business processes, etc.).
In a modern data architecture, unified analytics enable you to access the data you need, whether it’s stored in a data lake or a datawarehouse. One of the most common use cases for data preparation on Amazon Redshift is to ingest and transform data from different data stores into an Amazon Redshift datawarehouse.
AWS’s secure and scalable environment ensures dataintegrity while providing the computational power needed for advanced analytics. Thus, DB2 PureScale on AWS equips this insurance company to innovate and make data-driven decisions rapidly, maintaining a competitive edge in a saturated market.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Data processing Raw data is often cluttered with duplicates and irregular formats.
Amazon Redshift is a fully managed and petabyte-scale cloud datawarehouse that is used by tens of thousands of customers to process exabytes of data every day to power their analytics workload. You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model.
To achieve this, they combine their CRM data with a wealth of information already available in their datawarehouse, enterprise systems, or other software as a service (SaaS) applications. One widely used approach is getting the CRM data into your datawarehouse and keeping it up to date through frequent data synchronization.
Manage your Iceberg table with AWS Glue You can use AWS Glue to ingest, catalog, transform, and manage the data on Amazon Simple Storage Service (Amazon S3). With AWS Glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog. Nidhi Gupta is a Sr.
What is less frequently mentioned is that during this same time we have also seen a rapid increase of cloud services where data needs to be delivered (data lakes, lakehouses, cloud warehouses, cloud streaming systems, cloud business processes, etc.). bridging protocols, data formats, routing, filtering, error handling, retries).
Reading Time: 3 minutes We are naturally inclined to think that our relationship with data develops solely in the world > data > use direction, in which data captures what happens in the world, and we use data to understand events in the world.
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, dataintegrity is of paramount importance.
Performance and scalability of both the data pipeline and API endpoint were key success criteria. The data pipeline needed to have sufficient performance to allow for fast turnaround in the event that data issues needed to be corrected. The following diagram illustrates this architecture.
Coming up, Cloudera will be featured at Informatica World (global customer event) in Las Vegas. The conference provides a useful opportunity to reflect on the rapid evolution we’ve seen in the DataIntegration and Management space, much of it driven by the innovations that Cloudera and the open source community have been delivering.
To process batch data effectively, we use AWS Glue , a serverless dataintegration service that uses the Spark framework to process the data from S3 and copies the data to the open table format layer. Debezium is built on top of Apache Kafka and provides a set of Kafka Connect compatible connectors.
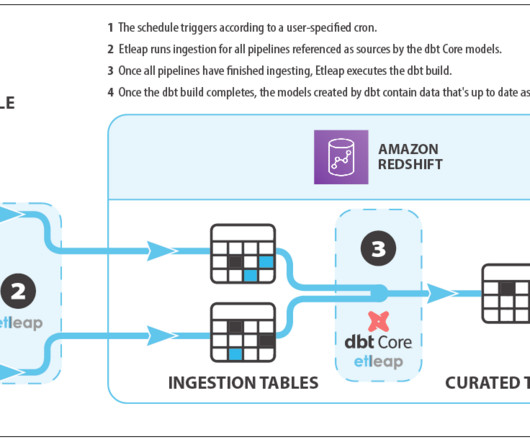
Organizations use their data to extract valuable insights and drive informed business decisions. Introduction to Amazon Redshift Amazon Redshift is a fast, fully-managed, self-learning, self-tuning, petabyte-scale, ANSI-SQL compatible, and secure cloud datawarehouse. Etleap simplifies the data pipeline building experience.
Remember when you began your career and the prospect of retirement was an event in the distant future? This may involve integrating different technologies, like cloud sources, on-premise databases, datawarehouses and even spreadsheets. Add the predictive logic to the data model.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content