This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
In addition to various deployment options, Oracle offers several database services, including Oracle Exadata optimized infrastructure, Oracle Autonomous Database, Oracle Autonomous DataWarehouse and Heatwave MySQL service. Exadata is Oracles engineered system for data and now artificial intelligence (AI) operations.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, data quality and master data management. Its code generation architecture uses a visual interface to create Java or SQL code.
Additionally, as I recently explained , the companys platform addresses a broad range of capabilities that includes data governance and security, dataintegration and application development, as well as the automation and incorporation of artificial intelligence (AI) and machinelearning (ML) models into BI and analytics.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
But what are the right measures to make the datawarehouse and BI fit for the future? Can the basic nature of the data be proactively improved? The following insights came from a global BARC survey into the current status of datawarehouse modernization. They are opting for cloud data services more frequently.
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machinelearning, AI, data governance, and data security operations. . Dagster / ElementL — A data orchestrator for machinelearning, analytics, and ETL. .
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. This innovation drives an important change: you’ll no longer have to copy or move data between data lake and datawarehouses.
At AWS re:Invent 2024, we announced the next generation of Amazon SageMaker , the center for all your data, analytics, and AI. Unified access to your data is provided by Amazon SageMaker Lakehouse , a unified, open, and secure data lakehouse built on Apache Iceberg open standards.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from datawarehouses, data lakes, and data marts, and interfaces must make it easy for users to consume that data.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. He has worked with building datawarehouses and big data solutions for over 13 years.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud datawarehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
To run analytics on their operational data, customers often build solutions that are a combination of a database, a datawarehouse, and an extract, transform, and load (ETL) pipeline. ETL is the process data engineers use to combine data from different sources.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
A point of data entry in a given pipeline. Examples of an origin include storage systems like data lakes, datawarehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
As data volumes and use cases scale especially with AI and real-time analytics trust must be an architectural principle, not an afterthought. Comparison of modern data architectures : Architecture Definition Strengths Weaknesses Best used when Datawarehouse Centralized, structured and curated data repository.
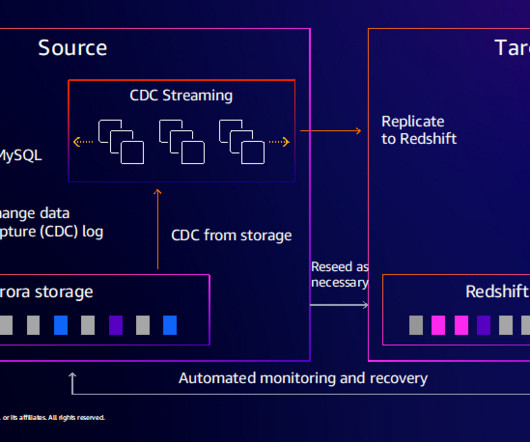
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. Its also serverless, which means theres no infrastructure to manage.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a datawarehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Investment in datawarehouses is rapidly rising, projected to reach $51.18 billion by 2028 as the technology becomes a vital cog for enterprises seeking to be more data-driven by using advanced analytics. Datawarehouses are, of course, no new concept. More data, more demanding. “As
Centralized reporting boosts data value For more than a decade, pediatric health system Phoenix Children’s has operated a datawarehouse containing more than 120 separate data systems, providing the ability to connect data from disparate systems. Companies should also incorporate data discovery, Higginson says.
In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow , a fully managed dataintegration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery.
Many companies identify and label PII through manual, time-consuming, and error-prone reviews of their databases, datawarehouses and data lakes, thereby rendering their sensitive data unprotected and vulnerable to regulatory penalties and breach incidents. For our solution, we use Amazon Redshift to store the data.
CIOs who use low-code/no-code platforms and new governance models to create self-service data capabilities are turning shadow IT into citizen developers who can fish for their own data. The challenge for CIOs who want to improve their company’s analytics capabilities is a familiar one: dataintegrity versus innovation. “In
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
The Matillion dataintegration and transformation platform enables enterprises to perform advanced analytics and business intelligence using cross-cloud platform-as-a-service offerings such as Snowflake. DataKitchen acts as a process hub that unifies tools and pipelines across teams, tools and data centers. Stronger Together.
In today’s data-driven business landscape, organizations collect a wealth of data across various touch points and unify it in a central datawarehouse or a data lake to deliver business insights. It provides secure, real-time access to Redshift data without copying, keeping enterprise data in place.
Organizations run millions of Apache Spark applications each month on AWS, moving, processing, and preparing data for analytics and machinelearning. Data practitioners need to upgrade to the latest Spark releases to benefit from performance improvements, new features, bug fixes, and security enhancements.
The data lakehouse is a relatively new data architecture concept, first championed by Cloudera, which offers both storage and analytics capabilities as part of the same solution, in contrast to the concepts for data lake and datawarehouse which, respectively, store data in native format, and structured data, often in SQL format.
Data also needs to be sorted, annotated and labelled in order to meet the requirements of generative AI. No wonder CIO’s 2023 AI Priorities study found that dataintegration was the number one concern for IT leaders around generative AI integration, above security and privacy and the user experience.
Let’s go through the ten Azure data pipeline tools Azure Data Factory : This cloud-based dataintegration service allows you to create data-driven workflows for orchestrating and automating data movement and transformation. You can use it for big data analytics and machinelearning workloads.
Here, I’ll highlight the where and why of these important “dataintegration points” that are key determinants of success in an organization’s data and analytics strategy. For datawarehouses, it can be a wide column analytical table. Data and cloud strategy must align.
Business Intelligence uses methods and tools like machinelearning to take massive, unstructured swaths of data and turn them into easy-to-use reports. Set Up DataIntegration. In order to make good business decisions, leaders need accurate insights into both the market and day-to-day operations.
In today’s data-driven business environment, organizations face the challenge of efficiently preparing and transforming large amounts of data for analytics and data science purposes. Businesses need to build datawarehouses and data lakes based on operational data.
Amazon Redshift offers seamless integration with Apache Spark, allowing you to easily access your Redshift data on both Amazon Redshift provisioned clusters and Amazon Redshift Serverless. These tables are then joined with tables from the Enterprise Data Lake (EDL) at runtime. In his spare time, he enjoys reading and traveling.
This data is usually saved in different databases, external applications, or in an indefinite number of Excel sheets which makes it almost impossible to combine different data sets and update every source promptly. BI tools aim to make dataintegration a simple task by providing the following features: a) Data Connectors.
Data management consultancy, BitBang, says CDPs offer five key benefits : As a central hub for all your customer data, they help you build unified customer profiles. They eliminate data silos, and, unlike a traditional datawarehouse, CDPs don’t require technical expertise to set up or maintain. Types of CDPs.
Data in Place refers to the organized structuring and storage of data within a specific storage medium, be it a database, bucket store, files, or other storage platforms. In the contemporary data landscape, data teams commonly utilize datawarehouses or lakes to arrange their data into L1, L2, and L3 layers.
The UK’s National Health Service (NHS) will be legally organized into Integrated Care Systems from April 1, 2022, and this convergence sets a mandate for an acceleration of dataintegration, intelligence creation, and forecasting across regions.
One option is a data lake—on-premises or in the cloud—that stores unprocessed data in any type of format, structured or unstructured, and can be queried in aggregate. Another option is a datawarehouse, which stores processed and refined data. Set up unified data governance rules and processes.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
He highlights innovations in data, infrastructure, and artificial intelligence and machinelearning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. KEY003 | Swami Sivasubramanian (Vice President, Data and AI at AWS) | Nov.
In case the data sources change, data engineers have to manually make changes in their code and deploy it again. Furthermore, the time required to build or change pipelines makes the data unfit for near-real-time use cases such as detecting fraudulent transactions, placing online ads, and tracking passenger train schedules.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content