This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Given the importance of data in the world today, organizations face the dual challenges of managing large-scale, continuously incoming data while vetting its quality and reliability. AWS Glue is a serverless dataintegration service that you can use to effectively monitor and manage data quality through AWS Glue Data Quality.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
This article was published as a part of the Data Science Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective dataintegration. Building an ETL pipeline using Apache […].
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
Amazon SageMaker Lakehouse , now generally available, unifies all your data across Amazon Simple Storage Service (Amazon S3) data lakes and Amazon Redshift datawarehouses, helping you build powerful analytics and AI/ML applications on a single copy of data. Having confidence in your data is key.
Plug-and-play integration : A seamless, plug-and-play integration between data producers and consumers should facilitate rapid use of new data sets and enable quick proof of concepts, such as in the data science teams. As part of the required data, CHE data is shared using Amazon DataZone.
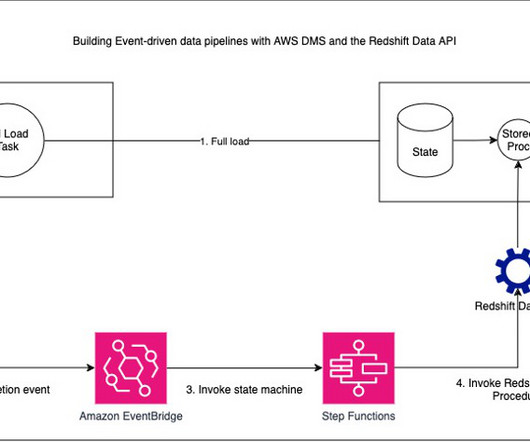
Diagram 1: Overall architecture of the solution, using AWS Step Functions, Amazon Redshift and Amazon S3 The following AWS services were used to shape our new ETL architecture: Amazon Redshift A fully managed, petabyte-scale datawarehouse service in the cloud. Its also serverless, which means theres no infrastructure to manage.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, data lakes, or datawarehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools.
Source systems Aruba’s source repository includes data from three different operating regions in AMER, EMEA, and APJ, along with one worldwide (WW) data pipeline from varied sources like SAP S/4 HANA, Salesforce, Enterprise DataWarehouse (EDW), Enterprise Analytics Platform (EAP) SharePoint, and more.
Here, I’ll highlight the where and why of these important “dataintegration points” that are key determinants of success in an organization’s data and analytics strategy. For datawarehouses, it can be a wide column analytical table. Data and cloud strategy must align.
Multi-channel publishing of data services. Agile BI and Reporting, Single Customer View, Data Services, Web and Cloud Computing Integration are scenarios where Data Virtualization offers feasible and more efficient alternatives to traditional solutions. Does Data Virtualization support web dataintegration?
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. Test access using SageMaker Studio in the consumer account.
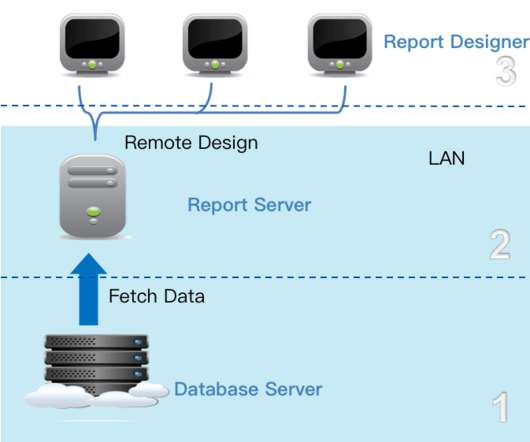
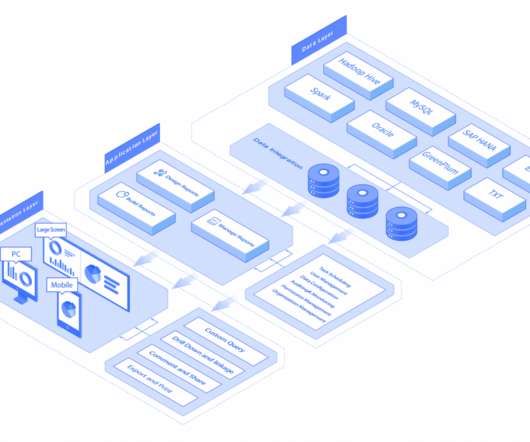
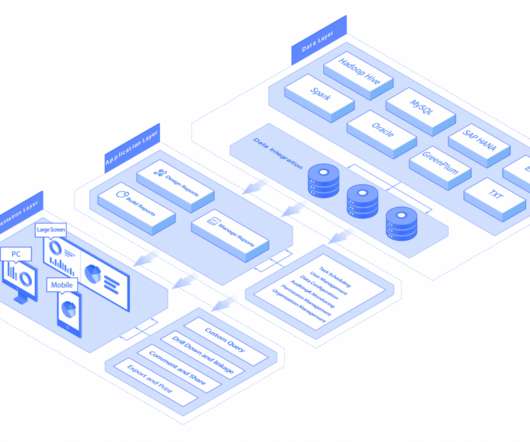
It is composed of three functional parts: the underlying data, data analysis, and data presentation. The underlying data is in charge of data management, covering data collection, ETL, building a datawarehouse, etc. You can design, generate, and manage reports in this part.
Amazon SageMaker Lakehouse provides an open data architecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift datawarehouses, and third-party and federated data sources. With AWS Glue 5.0, AWS Glue 5.0 AWS Glue 5.0 Apache Iceberg 1.6.1,
You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. With these insights, teams have the visibility to make dataintegration pipelines more efficient. Select Publish new dashboard as , and enter GlueObservabilityDashboard. Choose Publish dashboard.
The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. Read: The first capability of a data fabric is a semantic knowledge data catalog, but what are the other 5 core capabilities of a data fabric? 11 May 2021. .
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. DMPs excel at negotiating with a wide array of databases, data lakes, or datawarehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Then the reporting engine publishes these reports to the reporting portal to allow non-technical end-users access. In this way, users can gain insights from the data and make data-driven decisions. . The underlying data is responsible for data management, including data collection, ETL, building a datawarehouse, etc.
If I am moved to write research about a vendor, I’ll write it and publish it behind our pay wall, in the assumption the advice is valuable. This acquisition followed another with Mulesoft, a dataintegration vendor. Analytics offerings are valuable; dataintegration tools are too.
Reading Time: 3 minutes While cleaning up our archive recently, I found an old article published in 1976 about data dictionary/directory systems (DD/DS). Nowadays, we no longer use the term DD/DS, but “data catalog” or simply “metadata system”. It was written by L.
Amazon Redshift is a fully managed and petabyte-scale cloud datawarehouse that is used by tens of thousands of customers to process exabytes of data every day to power their analytics workload. You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. Hundreds of thousands of customers use data lakes for analytics and ML to make data-driven business decisions. Choose Save ruleset.
It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release 7 times fewer defects. Finally, dataintegrity is of paramount importance.
Lakehouse (datawarehouse and data lake working together) 8. Data Literacy, training, coordination, collaboration 8. Data Management Infrastructure/Data Fabric 5. DataIntegration tactics 4. Figure 3: The Data and Analytics (infrastructure) Continuum. Business Innovation with D&A 6.
The Magic Quadrant (MQ) is an established, widely-referenced series of research reports published by the analyst firm Gartner, Inc. The January 2019 “Magic Quadrant for Data Management Solutions for Analytics” provides valuable insights into the status, direction, and players in the DMSA market.
Data Cleaning The terms data cleansing and data cleaning are often used interchangeably, but they have subtle differences: Data cleaning refers to the broader process of preparing data for analysis by removing errors and inconsistencies. Lets take a closer look at just how expensive dirty data can be.
The data layer of FineReport is responsible for data management, including data collection, ETL, building a datawarehouse, etc. It supports multiple data sources and dataintegration. . FineReport is reporting software adopted the 3-tier architecture. .
The longer answer is that in the context of machine learning use cases, strong assumptions about dataintegrity lead to brittle solutions overall. Most of the data management moved to back-end servers, e.g., databases. So we had three tiers providing a separation of concerns: presentation, logic, data.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
Satori integrates natively with both Amazon Redshift provisioned clusters and Amazon Redshift Serverless for easy setup of your Amazon Redshift datawarehouse in the secure Satori portal. In part 2, we will explore how to set up self-service data access with Satori to data stored in Amazon Redshift.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, data lake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
This inefficiency highlights the need to streamline processes and improve data management, including automated dataintegration. Our findings echo this insight, with the overwhelming majority of Oracle ERP finance teams (98%) experiencing dataintegration challenges.
Data mapping is essential for integration, migration, and transformation of different data sets; it allows you to improve your data quality by preventing duplications and redundancies in your data fields. Data mapping helps standardize, visualize, and understand data across different systems and applications.
These sit on top of datawarehouses that are strictly governed by IT departments. The role of traditional BI platforms is to collect data from various business systems. If the app has simple requirements, basic security, and no plans to modernize its capabilities at a future date, this can be a good 1.0.
Maintain a Single Source of Truth Ensuring dataintegrity is of utmost importance during migration. Centralizing your data into a single source of truth helps maintain accurate, up-to-date information accessible to all stakeholders.
These are valid fears, as companies that have already completed their cloud migrations reported integration challenges and user skills gaps as their largest hurdles during implementation, but with careful planning and team training, companies can expect a smooth transition from on-premises to cloud systems.
Managing DataIntegrity. Before rolling the new process out, the company needed to address dataintegrity, a normal stage in any new software implementation project. Following the dataintegrity phase, the company focused on setting up the correct processes and on rightsizing the project.
Additionally, fostering a culture of data literacy by training teams on data standards and best practices ensures that everyone contributes to maintaining a high standard of dataintegrity, positioning the organization for long-term success. The Simba Story: Advancing Leadership in Data Connectivity Download Now 4.
It then creates insights into what is happening at an operational level right now and in the foreseeable future by enriching the data with pre-built supply chain and finance calculations, on a transaction level (execution status, order bottlenecks) and in the form of operational KPIs (delivery reliability, stock level). Clean data is here.
The answer depends on your specific business needs and the nature of the data you are working with. Both methods have advantages and disadvantages: Replication involves periodically copying data from a source system to a datawarehouse or reporting database. The alternative to BICC is BI Publisher (BIP).
It streamlines dataintegration, ensures real-time access to accurate information, enhances collaboration, and provides the flexibility needed to adapt to evolving ERP systems and business requirements. Our Webinar Breaks it all Down Watch our on-demand webinar here to see if Angles for Oracle is right for your cloud journey.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content