This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. SageMaker Lakehouse gives you the flexibility to access and query your data in-place with all Apache Iceberg compatible tools and engines.
Data lakes and datawarehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure. Various data stores are supported in AWS Glue; for example, AWS Glue 4.0
It’s costly and time-consuming to manage on-premises datawarehouses — and modern cloud data architectures can deliver business agility and innovation. However, CIOs declare that agility, innovation, security, adopting new capabilities, and time to value — never cost — are the top drivers for cloud data warehousing.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. For additional details, refer to Automated snapshots.
Manage your Iceberg table with AWS Glue You can use AWS Glue to ingest, catalog, transform, and manage the data on Amazon Simple Storage Service (Amazon S3). With AWS Glue, you can discover and connect to more than 70 diverse data sources and manage your data in a centralized data catalog.
Cost effectively maintaining Apache Iceberg tables Maintaining Apache Iceberg tables is crucial for optimizing performance, reducing storage costs, and ensuring dataintegrity. Expire snapshots Each write to an Iceberg table creates a new snapshot , or version, of a table. They decided to focus on four runtime engines.
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
This integration expands the possibilities for AWS analytics and machine learning (ML) solutions, making the datawarehouse accessible to a broader range of applications. These tables are then joined with tables from the Enterprise Data Lake (EDL) at runtime.
Apache Hudi is an open table format that brings database and datawarehouse capabilities to data lakes. Apache Hudi helps data engineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
Amazon Redshift is a fully managed and petabyte-scale cloud datawarehouse that is used by tens of thousands of customers to process exabytes of data every day to power their analytics workload. You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model.
To achieve this, they combine their CRM data with a wealth of information already available in their datawarehouse, enterprise systems, or other software as a service (SaaS) applications. One widely used approach is getting the CRM data into your datawarehouse and keeping it up to date through frequent data synchronization.
A data fabric answers perhaps the biggest question of all: what data do we have to work with? Managing and making individual data sources available through traditional enterprise dataintegration, and when end users request them, simply does not scale — especially in light of a growing number of sources and volume.
Additionally, the scale is significant because the multi-tenant data sources provide a continuous stream of testing activity, and our users require quick data refreshes as well as historical context for up to a decade due to compliance and regulatory demands. Finally, dataintegrity is of paramount importance.
AWS Glue for ETL To meet customer demand while supporting the scale of new businesses’ data sources, it was critical for us to have a high degree of agility, scalability, and responsiveness in querying various data sources. Every dataset in our system is uniquely identified by snapshot ID, which we can search from our metadata store.
Users can apply built-in schema tests (such as not null, unique, or accepted values) or define custom SQL-based validation rules to enforce dataintegrity. dbt Core allows for data freshness monitoring and timeliness assessments, ensuring tables are updated within anticipated intervals in addition to standard schema validations.
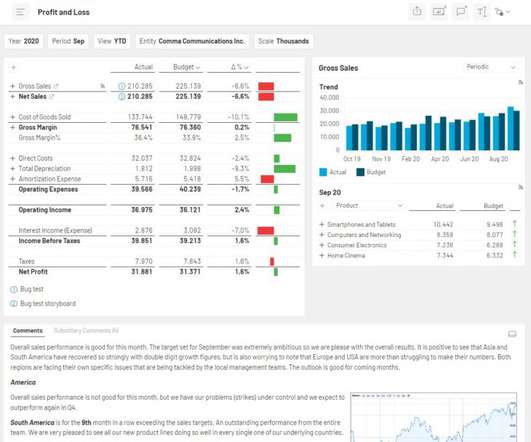
The financial KPI dashboard presents a comprehensive snapshot of key indicators, enabling businesses to make informed decisions, identify areas for improvement, and align their strategies for sustained success. Ensuring seamless dataintegration and accuracy across these sources can be complex and time-consuming.
The importance of publishing only high-quality data cant be overstatedits the foundation for accurate analytics, reliable machine learning (ML) models, and sound decision-making. AWS Glue is a serverless dataintegration service that you can use to effectively monitor and manage data quality through AWS Glue Data Quality.
Organizations across all industries have complex data processing requirements for their analytical use cases across different analytics systems, such as data lakes on AWS , datawarehouses ( Amazon Redshift ), search ( Amazon OpenSearch Service ), NoSQL ( Amazon DynamoDB ), machine learning ( Amazon SageMaker ), and more.
The answer depends on your specific business needs and the nature of the data you are working with. Both methods have advantages and disadvantages: Replication involves periodically copying data from a source system to a datawarehouse or reporting database. Empower your team to add new data sources on the fly.
That might be a sales performance dashboard for your Chief Revenue Officer, a snapshot of “days sales outstanding” (DSO) for the A/R collections team, or an item sales trend analysis for product management. With the CXO DataWarehouse Adapter, you can access ERP data, planning and budgeting numbers, or external information.
Every time you do an export from your ERP system, you’re taking a snapshot of the data that only reflects a single moment in time. A static (therefore outdated) view of the business : Another major problem with manual processes is that they don’t reflect what’s happening in the business in real time.
All of that in-between work–the export, the consolidation, and the cleanup–means that analysts are stuck using a snapshot of the data. Perhaps just as importantly, they lead to a time delay between the moment something happens in the business and the time it shows up on a report. Manual Processes Are Prone to Errors.
There is yet another problem with manual processes: the resulting reports only reflect a snapshot in time. As soon as you export data from your ERP software or other business systems, it’s obsolete.
The source data in this scenario represents a snapshot of the information in your ERP system. Researching that question requires substantial additional effort if your organization uses manual planning and budgeting processes. It’s not updated when someone records new transactions, and you can’t drill down to the details.
Microsoft Excel offers flexibility, but it’s missing so many of the elements required to assemble data quickly and easily for powerful (and accurate) financial narratives. The reports created within static spreadsheets are based on a snapshot of reality, taken the moment the data was exported from ERP.
And that is only a snapshot of the benefits your finance users will enjoy with Angles for Deltek. Angles has been effective to providing us real-time financial and operational data that otherwise we would have to manually parse together. Tools to configure custom views for the remaining 20% of your team’s operational reporting needs.
Because core data has resided in LeeSar’s legacy system for more than a decade, “a fair amount of effort was required to ensure we were bringing clean data into the Oracle platform, so it has required an IT and functional team partnership to ensure the data is accurate as it is migrated.”
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content