This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Industry-leading price-performance Amazon Redshift offers up to three times better price-performance than alternative cloud datawarehouses.
The growing volume of data is a concern, as 20% of enterprises surveyed by IDG are drawing from 1000 or more sources to feed their analytics systems. Dataintegration needs an overhaul, which can only be achieved by considering the following gaps. Heterogeneous sources produce data sets of different formats and structures.
Currently, a handful of startups offer “reverse” extract, transform, and load (ETL), in which they copy data from a customer’s datawarehouse or data platform back into systems of engagement where business users do their work. Sharing Customer 360 insights back without data replication.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. He has worked with building datawarehouses and big data solutions for over 13 years.
AWS Database Migration Service (AWS DMS) is used to securely transfer the relevant data to a central Amazon Redshift cluster. The data in the central datawarehouse in Amazon Redshift is then processed for analytical needs and the metadata is shared to the consumers through Amazon DataZone.
The data lakehouse is a relatively new data architecture concept, first championed by Cloudera, which offers both storage and analytics capabilities as part of the same solution, in contrast to the concepts for data lake and datawarehouse which, respectively, store data in native format, and structureddata, often in SQL format.
Many companies identify and label PII through manual, time-consuming, and error-prone reviews of their databases, datawarehouses and data lakes, thereby rendering their sensitive data unprotected and vulnerable to regulatory penalties and breach incidents. For our solution, we use Amazon Redshift to store the data.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your datawarehouse. These upstream data sources constitute the data producer components.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data discoverability Unlike structureddata, which is managed in well-defined rows and columns, unstructured data is stored as objects.
Customer data platform defined. A customer data platform (CDP) is a prepackaged, unified customer database that pulls data from multiple sources to create customer profiles of structureddata available to other marketing systems. By applying machine learning to the data, you can better predict customer behavior.
In all cases the data will eventually be loaded into a different place, so it can be managed, and organized, using a package such as Sisense for Cloud Data Teams. Using data pipelines and dataintegration between data storage tools, engineers perform ETL (Extract, transform and load). Connect tables.
AWS has invested in a zero-ETL (extract, transform, and load) future so that builders can focus more on creating value from data, instead of having to spend time preparing data for analysis. You can send data from your streaming source to this resource for ingesting the data into a Redshift datawarehouse.
Amazon SageMaker Lakehouse provides an open data architecture that reduces data silos and unifies data across Amazon Simple Storage Service (Amazon S3) data lakes, Redshift datawarehouses, and third-party and federated data sources. With AWS Glue 5.0, AWS Glue 5.0 AWS Glue 5.0 Apache Iceberg 1.6.1,
Selling the value of data transformation Iyengar and his team are 18 months into a three- to five-year journey that started by building out the data layer — corralling data sources such as ERP, CRM, and legacy databases into datawarehouses for structureddata and data lakes for unstructured data.
We’ve seen a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. With these connectors, you can bring the data from Azure Blob Storage and Azure Data Lake Storage separately to Amazon S3.
Data Pipeline Use Cases Here are just a few examples of the goals you can achieve with a robust data pipeline: Data Prep for Visualization Data pipelines can facilitate easier data visualization by gathering and transforming the necessary data into a usable state.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Data exploration Data exploration helps unearth inconsistencies, outliers, or errors.
First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making.
Introduction to Amazon Redshift Amazon Redshift is a fast, fully-managed, self-learning, self-tuning, petabyte-scale, ANSI-SQL compatible, and secure cloud datawarehouse. Thousands of customers use Amazon Redshift to analyze exabytes of data and run complex analytical queries.
Data analytic challenges As an ecommerce company, Ruparupa produces a lot of data from their ecommerce website, their inventory systems, and distribution and finance applications. The data can be structureddata from existing systems, and can also be unstructured or semi-structureddata from their customer interactions.
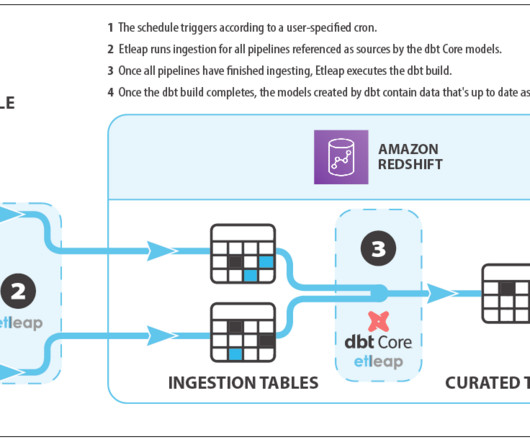
Instead of relying on one-off scripts or unstructured transformation logic, dbt Core structures transformations as models, linking them through a Directed Acyclic Graph (DAG) that automatically handles dependencies. Workaround: Use Git branches, tagging, and commit messages to trackchanges.
Data Pipeline Use Cases Here are just a few examples of the goals you can achieve with a robust data pipeline: Data Prep for Visualization Data pipelines can facilitate easier data visualization by gathering and transforming the necessary data into a usable state.
Customers often use many SQL scripts to select and transform the data in relational databases hosted either in an on-premises environment or on AWS and use custom workflows to manage their ETL. AWS Glue is a serverless dataintegration and ETL service with the ability to scale on demand.
Specifically, the increasing amount of data being generated and collected, and the need to make sense of it, and its use in artificial intelligence and machine learning, which can benefit from the structureddata and context provided by knowledge graphs. We get this question regularly.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, data lake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
The answer depends on your specific business needs and the nature of the data you are working with. Both methods have advantages and disadvantages: Replication involves periodically copying data from a source system to a datawarehouse or reporting database. Empower your team to add new data sources on the fly.
While Microsoft Dynamics is a powerful platform for managing business processes and data, Dynamics AX users and Dynamics 365 Finance & Supply Chain Management (D365 F&SCM) users are only too aware of how difficult it can be to blend data across multiple sources in the Dynamics environment.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content