This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is accomplished through tags, annotations, and metadata (TAM). So, there must be a strategy regarding who, what, when, where, why, and how is the organization’s content to be indexed, stored, accessed, delivered, used, and documented. Smart content includes labeled (tagged, annotated) metadata (TAM).
Metadata management is key to wringing all the value possible from data assets. However, most organizations don’t use all the data at their disposal to reach deeper conclusions about how to drive revenue, achieve regulatory compliance or accomplish other strategic objectives. What Is Metadata? Harvest data.
It addresses many of the shortcomings of traditional data lakes by providing features such as ACID transactions, schema evolution, row-level updates and deletes, and time travel. In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient.
Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. To be able to automate these operations and maintain sufficient data quality, enterprises have started implementing the so-called data fabrics , that employ diverse metadata sourced from different systems. Such examples are provenance (e.g.
In most companies, an incredible amount of data flows from multiple sources in a variety of formats and is constantly being moved and federated across a changing system landscape. And this time, you guessed it – we’re focusing on data automation and how it could impact metadata management and data governance.
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documentingmetadata. But are these rampant and often uncontrolled projects to collect metadata properly motivated? What Is Metadata?
If you’re a mystery lover, I’m sure you’ve read that classic tale: Sherlock Holmes and the Case of the Deceptive Data, and you know how a metadata catalog was a key plot element. In The Case of the Deceptive Data, Holmes is approached by B.I. He goes on to explain: Reasons for inaccurate data. Big data is BIG.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
Dataintegrity constraints: Many databases don’t allow for strange or unrealistic combinations of input variables and this could potentially thwart watermarking attacks. Applying dataintegrity constraints on live, incoming data streams could have the same benefits. Disparate impact analysis: see section 1.
The results of our new research show that organizations are still trying to master data governance, including adjusting their strategies to address changing priorities and overcoming challenges related to data discovery, preparation, quality and traceability. And close to 50 percent have deployed data catalogs and business glossaries.
But even with the “need for speed” to market, new applications must be modeled and documented for compliance, transparency and stakeholder literacy. With all these diverse metadata sources, it is difficult to understand the complicated web they form much less get a simple visual flow of data lineage and impact analysis.
It must be clear to all participants and auditors how and when data-related decisions and controls were introduced into the processes. Data-related decisions, processes, and controls subject to data governance must be auditable. The program must introduce and support standardization of enterprise data.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and dataintegrity.
If you suddenly see unexpected patterns in your social data, that may mean adversaries are attempting to poison your data sources. Anomaly detection may have originated in finance, but it is becoming a part of every data scientist’s toolkit. Tim Kraska on “How machine learning will accelerate data management systems”.
Ontotext’s GraphDB is an enterprise-ready semantic graph database (also called RDF triplestore as it stores data in RDF triples). It provides the core infrastructure for solutions where modeling agility, dataintegration, relationship exploration, cross-enterprise data publishing and consumption are critical.
A data catalog serves the same purpose. By using metadata (or short descriptions), data catalogs help companies gather, organize, retrieve, and manage information. You can think of a data catalog as an enhanced Access database or library card catalog system. What Does a Data Catalog Consist Of?
Metadata is an important part of data governance, and as a result, most nascent data governance programs are rife with project plans for assessing and documentingmetadata. But are these rampant and often uncontrolled projects to collect metadata properly motivated? What Is Metadata?
Data modeling is a process that enables organizations to discover, design, visualize, standardize and deploy high-quality data assets through an intuitive, graphical interface. Data models provide visualization, create additional metadata and standardize data design across the enterprise. What is Data Modeling?
Here are our eight recommendations for how to transition from manual to automated data management: 1) Put Data Quality First: Automating and matching business terms with data assets and documenting lineage down to the column level are critical to good decision making.
What, then, should users look for in a data modeling product to support their governance/intelligence requirements in the data-driven enterprise? Nine Steps to Data Modeling. Provide metadata and schema visualization regardless of where data is stored. naming and database standards, formatting options, and so on.
Many large organizations, in their desire to modernize with technology, have acquired several different systems with various data entry points and transformation rules for data as it moves into and across the organization. Who are the data owners? Data lineage offers proof that the data provided is reflected accurately.
Your organization won’t be able to take complete advantage of analytics tools to become data-driven unless you establish a foundation for agile and complete data management. You need automated data mapping and cataloging through the integration lifecycle process, inclusive of data at rest and data in motion.
We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless dataintegration service, to generate a catalog for access logs and create dashboards for insights. Both the user data and logs buckets must be in the same AWS Region and owned by the same account.
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. With AWS Glue 5.0, With AWS Glue 5.0,
To better explain our vision for automating data governance, let’s look at some of the different aspects of how the erwin Data Intelligence Suite (erwin DI) incorporates automation. Data Cataloging: Catalog and sync metadata with data management and governance artifacts according to business requirements in real time.
And each of these gains requires dataintegration across business lines and divisions. Limiting growth by (dataintegration) complexity Most operational IT systems in an enterprise have been developed to serve a single business function and they use the simplest possible model for this. We call this the Bad Data Tax.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
The role of data modeling (DM) has expanded to support enterprise data management, including data governance and intelligence efforts. Metadata management is the key to managing and governing your data and drawing intelligence from it. Types of Data Models: Conceptual, Logical and Physical.
In most companies, an incredible amount of data flows from multiple sources in a variety of formats and is constantly being moved and federated across a changing system landscape. With an automation framework, data professionals can meet these needs at a fraction of the cost of the traditional manual way. Governing metadata.
KGs bring the Semantic Web paradigm to the enterprises, by introducing semantic metadata to drive data management and content management to new levels of efficiency and breaking silos to let them synergize with various forms of knowledge management. Take this restaurant, for example. Enterprise Knowledge Graphs and the Semantic Web.
With data privacy and security becoming an increased concern, Sovereign cloud is turning from an optional, like-to-have, to an essential requirement, especially for highly protected markets like Government, Healthcare, Financial Services, Legal, etc. This local presence is crucial for maintaining dataintegrity and security.
“SAP is executing on a roadmap that brings an important semantic layer to enterprise data, and creates the critical foundation for implementing AI-based use cases,” said analyst Robert Parker, SVP of industry, software, and services research at IDC. We are also seeing customers bringing in other data assets from other apps or data sources.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic.
It uncovered a number of obstacles that organizations have to overcome to improve their data operations. 1 bottleneck, according to 62 percent of respondents, was documenting complete data lineage. Automate code generation : Alleviate the need for developers to hand code connections from data sources to target schema.
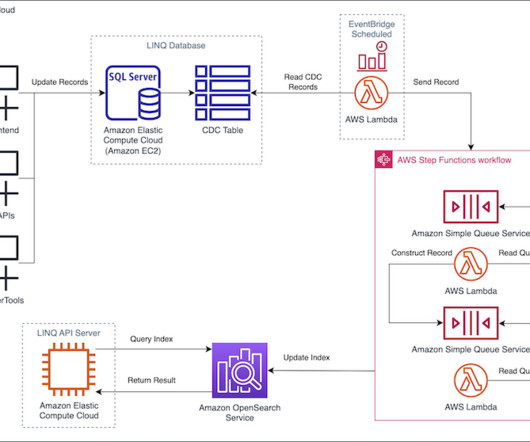
Following the best practices section of the OpenSearch Service Developer Guide, AVB selected an optimal cluster configuration with three dedicated cluster manager nodes and six data nodes, across three Availability Zones , while keeping shard size between 10–30 GiB.
AWS Transfer Family seamlessly integrates with other AWS services, automates transfer, and makes sure data is protected with encryption and access controls. Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. 2 GB into the landing zone daily.
Ontotext’s GraphDB is an enterprise-ready semantic graph database (also called RDF triplestore because it stores data in RDF triples). It provides the core infrastructure for solutions where modelling agility, dataintegration, relationship exploration, cross-enterprise data publishing and consumption are critical. .
It assists in successfully meeting increasingly strict compliance requirements, such as those in the General Data Protection Regulation (GDPR). A mature and sustainable data governance initiative must include dataintegration. Data Governance and the System Development Lifecycle. Governing metadata.
Knowledge graph technology can walk us out of the lack of context (which is basically absence of proper interlinking) and towards enriching digital representation of collection with semantic data and further interlinking it into a meaningful constellation of items.
The entire generative AI pipeline hinges on the data pipelines that empower it, making it imperative to take the correct precautions. 4 key components to ensure reliable data ingestion Data quality and governance: Data quality means ensuring the security of data sources, maintaining holistic data and providing clear metadata.
It enables data engineers, data scientists, and analytics engineers to define the business logic with SQL select statements and eliminates the need to write boilerplate data manipulation language (DML) and data definition language (DDL) expressions. 11:41:51 Registered adapter: glue=1.7.1
We offer two different PowerPacks – Agile DataIntegration and High-Performance Tagging. The High-Performance Tagging PowerPack bundle The High-Performance Tagging PowerPack is designed to satisfy taxonomy and metadata management needs by allowing enterprise tagging at a scale.
Running on CDW is fully integrated with streaming, data engineering, and machine learning analytics. It has a consistent framework that secures and provides governance for all data and metadata on private clouds, multiple public clouds, or hybrid clouds. Consideration of both data & metadata in the migration.
All are ideally qualified to help their customers achieve and maintain the highest standards for dataintegrity, including absolute control over data access, transparency and visibility into the provider’s operation, the knowledge that their information is managed appropriately, and access to VMware’s growing ecosystem of sovereign cloud solutions.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content