This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
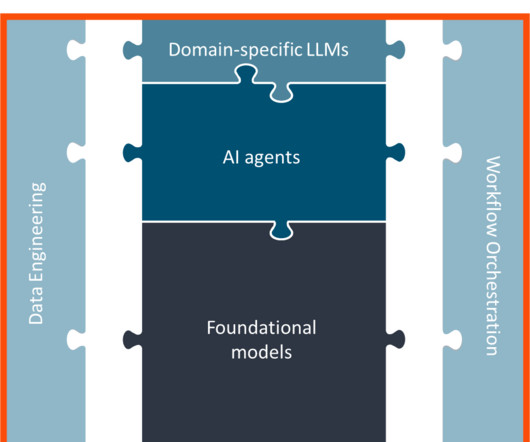
Applying customization techniques like prompt engineering, retrieval augmented generation (RAG), and fine-tuning to LLMs involves massive data processing and engineering costs that can quickly spiral out of control depending on the level of specialization needed for a specific task. In fact, business spending on AI rose to $13.8
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, DataIntegrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines.
Achieving this advantage is dependent on their ability to capture, connect, integrate, and convert data into insight for business decisions and processes. This is the goal of a “data-driven” organization. We call this the “ Bad Data Tax ”.
To overcome these issues, Orca decided to build a data lake. A data lake is a centralized data repository that enables organizations to store and manage large volumes of structured and unstructureddata, eliminating data silos and facilitating advanced analytics and ML on the entire data.
This capability has become increasingly more critical as organizations incorporate more unstructureddata into their data warehouses. This democratization is driving a seismic shift in data literacy throughout organizations, significantly changing how data is valued across every part of the enterprise.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content