This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In today’s data-driven landscape, businesses must integratedata from various sources to derive actionable insights and make informed decisions. With data volumes growing at an […] The post DataIntegration: Strategies for Efficient ETL Processes appeared first on Analytics Vidhya.
Amazon Q dataintegration , introduced in January 2024, allows you to use natural language to author extract, transform, load (ETL) jobs and operations in AWS Glue specific data abstraction DynamicFrame. In this post, we discuss how Amazon Q dataintegration transforms ETL workflow development.
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. In addition, organizations rely on an increasingly diverse array of digital systems, data fragmentation has become a significant challenge.
For decades, dataintegration was a rigid process. Data was processed in batches once a month, once a week or once a day. Organizations needed to make sure those processes were completed successfully—and reliably—so they had the data necessary to make informed business decisions.
Summit 2019, Information Builders' annual user conference, drew about 1000 attendees this year, including customers, partners and prospects all working with Information Builders' technologies. Under new leadership, Summit 2019 showcased the direction Information Builders is moving in the next couple of years.
The dataintegration landscape is under a constant metamorphosis. In the current disruptive times, businesses depend heavily on information in real-time and data analysis techniques to make better business decisions, raising the bar for dataintegration. Why is DataIntegration a Challenge for Enterprises?
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional dataintegration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
IT teams hold a lot of innovation power, as effective use of emerging technologies is crucial for informed decision-making and is key to staying a beat ahead of the competition. But adopting modern-day, cutting-edge technology is only as good as the data that feeds it. Innovation is crucial for business growth.
Introduction The dataintegration techniques ETL (Extract, Transform, Load) and ELT pipelines (Extract, Load, Transform) are both used to transfer data from one system to another.
Discovering data across a hybrid infrastructure Harnessing the full potential of data in a hybrid environment starts with a thorough discovery process. Teams must first identify the information thats crucial to the business and any associated regulatory requirements.
The growing volume of data is a concern, as 20% of enterprises surveyed by IDG are drawing from 1000 or more sources to feed their analytics systems. Dataintegration needs an overhaul, which can only be achieved by considering the following gaps. Heterogeneous sources produce data sets of different formats and structures.
A security breach could compromise these data, leading to severe financial and reputational damage. Moreover, compromised dataintegrity—when the content is tampered with or altered—can lead to erroneous decisions based on inaccurate information. Backup your data, too. So, how can you guarantee this?
Reading Time: 3 minutes Dataintegration is an important part of Denodo’s broader logical data management capabilities, which include data governance, a universal semantic layer, and a full-featured, business-friendly data catalog that not only lists all available data but also enables immediate access directly.
New drivers simplify Workday dataintegration for enhanced analytics and reporting RALEIGH, N.C. – The Simba Workday drivers provide secure access to Workday data for analytics, ETL (extract, transform, load) processes, and custom application development using both ODBC and JDBC technologies.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, data quality and master data management.
It’s possible to augment this basic process with OCR so the application can find data on paper forms, or to use natural language processing to gather information through a chat server. So from the start, we have a dataintegration problem compounded with a compliance problem. That’s the bad news.
Effective data analytics relies on seamlessly integratingdata from disparate systems through identifying, gathering, cleansing, and combining relevant data into a unified format. Depending on the size of the data in your account object in Salesforce, the job will take a few minutes to complete.
According to a study from Rocket Software and Foundry , 76% of IT decision-makers say challenges around accessing mainframe data and contextual metadata are a barrier to mainframe data usage, while 64% view integrating mainframe data with cloud data sources as the primary challenge.
With the exponential growth of data, companies are handling huge volumes and a wide variety of data including personally identifiable information (PII). PII is a legal term pertaining to information that can identify, contact, or locate a single person. For our solution, we use Amazon Redshift to store the data.
Business Data Cloud, released in February , is designed to integrate and manage SAP data and external data not stored in SAP to enhance AI and advanced analytics. SAP has established a partnership with Databricks for third-party dataintegration. This is an unprecedented level of customer interest.
Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. In this scenario, you’re a data analyst in this company.
This failure can cascade to the Silver and Gold layers, where downstream dependencies on the raw data prevent those layers from updating accurately. Such issues often go unnoticed until a user or analyst reports missing information in a dashboard or report, by which point the delay has already impacted business decision-making.
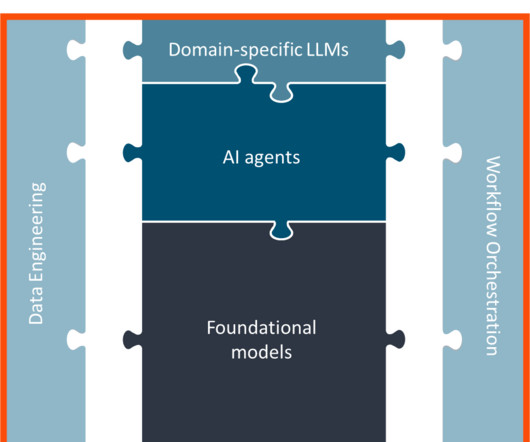
Applying customization techniques like prompt engineering, retrieval augmented generation (RAG), and fine-tuning to LLMs involves massive data processing and engineering costs that can quickly spiral out of control depending on the level of specialization needed for a specific task.
This is handled by Bigeye’s data observability platform via what it calls autometrics, which perform automated data quality checks as well as freshness, volume, and schema monitoring.
The problem is that, before AI agents can be integrated into a companys infrastructure, that infrastructure must be brought up to modern standards. In addition, because they require access to multiple data sources, there are dataintegration hurdles and added complexities of ensuring security and compliance.
Citizens expect efficient services, The post Empowering the Public Sector with Data: A New Model for a Modern Age appeared first on Data Management Blog - DataIntegration and Modern Data Management Articles, Analysis and Information.
Machine learning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Dataintegration and cleaning.
NLP also enables companies to analyze customer feedback and sentiment, leading to more informed strategic decisions. Integrating with various data sources is crucial for enhancing the capabilities of automation platforms , allowing enterprises to derive actionable insights from all available datasets.
Data is essential for businesses to make informed decisions, improve operations, and innovate. Integratingdata from different sources can be a complex and time-consuming process. AWS Glue provides different authoring experiences for you to build dataintegration jobs.
As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant. Data lives across siloed systems ERP, CRM, cloud platforms, spreadsheets with little integration or consistency.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. The curated data is cataloged, governed and managed using Amazon DataZone.
Reject on Negative Impact (RONI) : RONI is a technique that removes rows of data from the training data set that decrease prediction accuracy. See “ The Security of Machine Learning ” in section 8 for more information on RONI. Applying dataintegrity constraints on live, incoming data streams could have the same benefits.
Additionally, storage continued to grow in capacity, epitomized by an optical disk designed to store a petabyte of data, and the global Internet population. The post Denodos Predictions for 2025 appeared first on Data Management Blog - DataIntegration and Modern Data Management Articles, Analysis and Information.
If you are looking to enter the BI software world but don’t know which features you should look for before investing in one, this post will cover the top business intelligence features and benefits to help you make an informed decision. Your Chance: Want to take your data analysis to the next level? b) Flexible DataIntegration.
Some challenges include data infrastructure that allows scaling and optimizing for AI; data management to inform AI workflows where data lives and how it can be used; and associated data services that help data scientists protect AI workflows and keep their models clean. Seamless dataintegration.
The development of business intelligence to analyze and extract value from the countless sources of data that we gather at a high scale, brought alongside a bunch of errors and low-quality reports: the disparity of data sources and data types added some more complexity to the dataintegration process.
appeared first on Data Management Blog - DataIntegration and Modern Data Management Articles, Analysis and Information. One surprising statistic from the Rand Corporation is that 80% of artificial intelligence (AI). The post How Do You Know When You’re Ready for AI?
introduces features to enhance developer productivity and streamline data pipeline development: Parameter Groups: Simplify flow management and promote reusability by grouping parameters and applying them across multiple flows. empowers data engineers to build and deploy data pipelines faster, accelerating time-to-value for the business.
Amazon AppFlow bridges the gap between Google applications and Amazon Redshift, empowering organizations to unlock deeper insights and drive data-informed decisions. In this post, we show you how to establish the data ingestion pipeline between Google Analytics 4, Google Sheets, and an Amazon Redshift Serverless workgroup.
Hackers have advanced tools and equipment to get into the company servers and extract crucial information. Such information is openly traded in the black market leading to a huge loss of profit. In this article, we will try to decipher the reasons behind organizations’ newfound obsession with data security.
Organizations of all sizes are dealing with exponentially increasing data volume and data sources, which creates challenges such as siloed information, increased technical complexities across various systems and slow reporting of important business metrics.
Simplified data corrections and updates Iceberg enhances data management for quants in capital markets through its robust insert, delete, and update capabilities. These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising dataintegrity.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content