This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
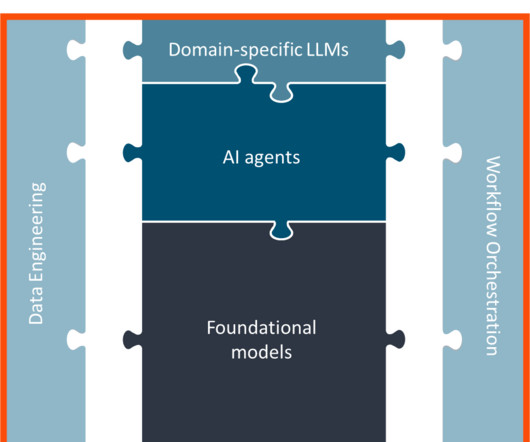
Applying customization techniques like prompt engineering, retrieval augmented generation (RAG), and fine-tuning to LLMs involves massive data processing and engineering costs that can quickly spiral out of control depending on the level of specialization needed for a specific task.
Zero-copy integration eliminates the need for manual data movement, preserving data lineage and enabling centralized control fat the data source. Currently, Data Cloud leverages live SQL queries to access data from external data platforms via zero copy. Ground generative AI.
While there are clear reasons SVB collapsed, which can be reviewed here , my purpose in this post isn’t to rehash the past but to present some of the regulatory and compliance challenges financial (and to some degree insurance) institutions face and how data plays a role in mitigating and managing risk. Well, sort of.
IBM, a pioneer in data analytics and AI, offers watsonx.data, among other technologies, that makes possible to seamlessly access and ingest massive sets of structured and unstructureddata. A leading insurance player in Japan leverages this technology to infuse AI into their operations.
The rule laid out an interoperability journey that supports seamless data exchange between payers and providers alike — enabling future functionalities and technically incremental use cases. These requirements enable the exchange of important data between healthcare payers and providers.
Physician notes from visits and procedures, test results, and prescriptions are captured and added to the patient’s chart and reviewed by medical coding specialists, who work with tens of thousands of codes used by insurance companies to authorize billing and reimbursement. This is a dynamic view on data that evolves over time,” said Koll.
Healthcare industries including pharma, biotech, agrochemical and insurance have been using knowledge graphs to improve discoverability in a number of new and innovative ways. By maintaining a referential knowledge bases, health insurance agencies have been able to automatically discover inconsistencies within insurance claims.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates dataintegration workloads in AWS.
Loading complex multi-point datasets into a dimensional model, identifying issues, and validating dataintegrity of the aggregated and merged data points are the biggest challenges that clinical quality management systems face. Build a data vault schema for the raw vault and create materialized views for the business vault.
Let’s discuss what data classification is, the processes for classifying data, data types, and the steps to follow for data classification: What is Data Classification? Either completed manually or using automation, the data classification process is based on the data’s context, content, and user discretion.
Today transactional data is the largest segment, which includes streaming and data flows. EXTRACTING VALUE FROM DATA. One of the biggest challenges presented by having massive volumes of disparate unstructureddata is extracting useable information and insights. Insurance.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content