This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional dataintegration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
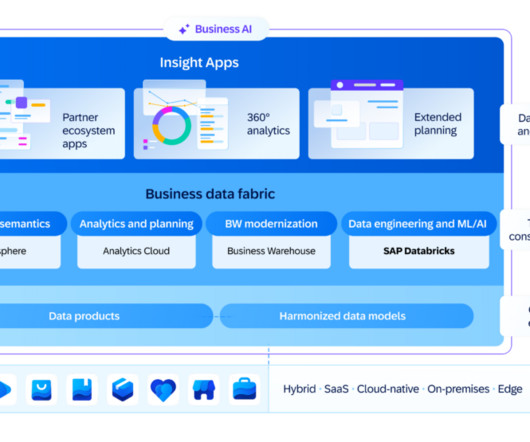
“SAP is executing on a roadmap that brings an important semantic layer to enterprise data, and creates the critical foundation for implementing AI-based use cases,” said analyst Robert Parker, SVP of industry, software, and services research at IDC.
Unstructured. Unstructureddata lacks a specific format or structure. As a result, processing and analyzing unstructureddata is super-difficult and time-consuming. Semi-structured data contains a mixture of both structured and unstructureddata. Role of Software Development in Big Data.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
Your LLM Needs a Data Journey: A Comprehensive Guide for Data Engineers The rise of Large Language Models (LLMs) such as GPT-4 marks a transformative era in artificial intelligence, heralding new possibilities and challenges in equal measure.
As it transforms your business into data-driven one, data could thus exploit their intrinsic value to the fullest by visualizations. I am sure no staff is willing to endure colossal, unstructureddata processing as it is time-consuming and boring. Business Data Dashboard(made by FineReport). FineReport?.
enables you to develop, run, and scale your dataintegration workloads and get insights faster. With data stories in Amazon Q in QuickSight, you can upload documents, or connect to unstructureddata sources from Amazon Q Business, to create richer narratives or presentations explaining your data with additional context.
In all cases the data will eventually be loaded into a different place, so it can be managed, and organized, using a package such as Sisense for Cloud Data Teams. Using data pipelines and dataintegration between data storage tools, engineers perform ETL (Extract, transform and load).
IT should be involved to ensure governance, knowledge transfer, dataintegrity, and the actual implementation. Rely on interactivedata visualizations. For instance, BI dashboard software such as datapine offers the possibility to generate interactive dashboards in real-time without the need for any technical knowledge.
A data lake is a centralized repository that you can use to store all your structured and unstructureddata at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. to complete the processes.
Through the AI-Human interaction module that we will develop in the project, we aim to make it easier for the user to understand the questions asked and define interactions suitable for it, thus obtaining curation with less time and effort without compromising the quality of health records.
In the era of big data, data lakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructureddata, offering a flexible and scalable environment for data ingestion from multiple sources.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Introduction.
In the current industry landscape, data lakes have become a cornerstone of modern data architecture, serving as repositories for vast amounts of structured and unstructureddata. It adds functionalities like ACID transactions and versioning to improve data reliability and manageability.
Athena provides the connectivity and query interface and can easily be plugged into other AWS services for downstream use cases such as interactive analysis and visualizations. We use the following AWS services in this solution: Amazon Athena – A serverless interactive analytics service.
Instead of relying on one-off scripts or unstructured transformation logic, dbt Core structures transformations as models, linking them through a Directed Acyclic Graph (DAG) that automatically handles dependencies. A key attribute of dbt Core is its comprehensive documentation functionalities.
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic dataintegration , and ontology building.
In today’s data-driven world, businesses are drowning in a sea of information. Traditional dataintegration methods struggle to bridge these gaps, hampered by high costs, data quality concerns, and inconsistencies. This is the power of Zenia Graph’s services and solution powered by Ontotext GraphDB.
The huge amount of content produced by Euromoney is now semantically analyzed, enriched and integrated into a streamlined production environment with complete visibility across the various business units. For efficient drug discovery, linked data is key. Knowledges Graphs for Memory Recall.
Loading complex multi-point datasets into a dimensional model, identifying issues, and validating dataintegrity of the aggregated and merged data points are the biggest challenges that clinical quality management systems face. Build a data vault schema for the raw vault and create materialized views for the business vault.
Architecture for data democratization Data democratization requires a move away from traditional “data at rest” architecture, which is meant for storing static data. Traditionally, data was seen as information to be put on reserve, only called upon during customer interactions or executing a program.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. a new version of AWS Glue that accelerates dataintegration workloads in AWS.
From a technological perspective, RED combines a sophisticated knowledge graph with large language models (LLM) for improved natural language processing (NLP), dataintegration, search and information discovery, built on top of the metaphactory platform. It compares actual price changes to expected changes based on historical data.
Data analytic challenges As an ecommerce company, Ruparupa produces a lot of data from their ecommerce website, their inventory systems, and distribution and finance applications. The data can be structured data from existing systems, and can also be unstructured or semi-structured data from their customer interactions.
This example combines three types of unrelated data: Legal entity data: Two companies with completely unrelated business lines (coffee and waste management) merged together; Unstructureddata: Fraudulent promotion campaigns took place through press releases and a fake stock-picking robot.
Apache Hadoop Apache Hadoop is a Java-based open-source platform used for storing and processing big data. It is based on a cluster system, allowing it to efficiently process data and run it parallelly. It can process structured and unstructureddata from one server to multiple computers and offers cross-platform support to users.
This capability has become increasingly more critical as organizations incorporate more unstructureddata into their data warehouses. These conversational systems of interaction with data provide the context to answer questions based not only on what is being asked but by whom.
Batch processing pipelines are designed to decrease workloads by handling large volumes of data efficiently and can be useful for tasks such as data transformation, data aggregation, dataintegration , and data loading into a destination system. structured, semi-structured, or unstructureddata).
Instead, the Databricks object store provides an industry-standard and more cost-efficient solution for storing data. Customers using analytics outside of SAP systems faced the challenge of extracting SAP data and transferring it to their target environments. Moreover, users can build their own agents.
Consider a simple use case example like email marketing where an agent can devise a plan that executes tasks across enterprise systems to access structured and unstructureddata, transactional systems, APIs and document management systems. edge compute data distribution that connect broad, deep PLM eco-systems.
Amazon EMR has long been the leading solution for processing big data in the cloud. Amazon EMR is the industry-leading big data solution for petabyte-scale data processing, interactive analytics, and machine learning using over 20 open source frameworks such as Apache Hadoop , Hive, and Apache Spark.
Data is everywhere. Every click, every transaction, every customer interaction generates a massive amount of information. And while Big Data is often seen as a buzzword, for many businesses, it’s a real challenge—how do you sift through mountains of data and make sense of it all? What Exactly is Big Data?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content