This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As the data community begins to deploy more machinelearning (ML) models, I wanted to review some important considerations. We recently conducted a survey which garnered more than 11,000 respondents—our main goal was to ascertain how enterprises were using machinelearning. Data Platforms.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machinelearning (ML) to software development, which included a tour through sample tools in data science and for managing data infrastructure.
In a recent survey , we explored how companies were adjusting to the growing importance of machinelearning and analytics, while also preparing for the explosion in the number of data sources. You can find full results from the survey in the free report “Evolving Data Infrastructure”.). Data Platforms.
Companies successfully adopt machinelearning either by building on existing data products and services, or by modernizing existing models and algorithms. In this post, I share slides and notes from a keynote I gave at the Strata Data Conference in London earlier this year. Use ML to unlock new data types—e.g.,
For all the excitement about machinelearning (ML), there are serious impediments to its widespread adoption. There are several known attacks against machinelearning models that can lead to altered, harmful model outcomes or to exposure of sensitive training data. [8] 2] The Security of MachineLearning. [3]
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
This year's conference focused on Alteryx's evolution from data preparation to AI and machinelearning, and both were front and center. The strong attendance was a reflection of the strong growth Alteryx has experienced over the last year; roughly 50% growth year-over-year.
The dataintegration landscape is under a constant metamorphosis. In the current disruptive times, businesses depend heavily on information in real-time and data analysis techniques to make better business decisions, raising the bar for dataintegration. Why is DataIntegration a Challenge for Enterprises?
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional dataintegration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
Machinelearning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Dataintegration and cleaning.
In 2017, we published “ How Companies Are Putting AI to Work Through Deep Learning ,” a report based on a survey we ran aiming to help leaders better understand how organizations are applying AI through deep learning. We found companies were planning to use deep learning over the next 12-18 months.
A security breach could compromise these data, leading to severe financial and reputational damage. Moreover, compromised dataintegrity—when the content is tampered with or altered—can lead to erroneous decisions based on inaccurate information. You wouldn’t want to make a business decision on flawed data, would you?
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machinelearning models from malicious actors. Like many others, I’ve known for some time that machinelearning models themselves could pose security risks. Data poisoning attacks. Inversion by surrogate models.
Highlights and use cases from companies that are building the technologies needed to sustain their use of analytics and machinelearning. In a forthcoming survey, “Evolving Data Infrastructure,” we found strong interest in machinelearning (ML) among respondents across geographic regions. Deep Learning.
We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machinelearning, AI, data governance, and data security operations. . Dagster / ElementL — A data orchestrator for machinelearning, analytics, and ETL. .
Bigeye’s anomaly detection capabilities rely on the automated generation of data quality thresholds based on machinelearning (ML) models fueled by historical data.
My favorite approach to TAM creation and to modern data management in general is AI and machinelearning (ML). That is, use AI and machinelearning techniques on digital content (databases, documents, images, videos, press releases, forms, web content, social network posts, etc.)
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
Talend is a dataintegration and management software company that offers applications for cloud computing, big dataintegration, application integration, data quality and master data management.
In turn, enterprises are increasingly looking for machine-learning-powered integration tools to synchronize data for analytics, improve employee productivity, and prepare data for analytics. Yet traditional ETL tools support only a limited number of delivery styles and involve a significant amount of hand-coding.
This article was published as a part of the Data Science Blogathon. Introduction Azure Synapse Analytics is a cloud-based service that combines the capabilities of enterprise data warehousing, big data, dataintegration, data visualization and dashboarding.
The Global Banking Benchmark Study 2024 , which surveyed more than 1,000 executives from the banking sector worldwide, found that almost a third (32%) of banks’ budgets for customer experience transformation is now spent on AI, machinelearning, and generative AI.
10 Most Used Tableau Functions • Is Domain Knowledge Important for MachineLearning? • ETL vs ELT: DataIntegration Showdown • Free MLOps Crash Course for Beginners • 90% of Today’s Code is Written to Prevent Failure, and That’s a Problem.
Introduction The dataintegration techniques ETL (Extract, Transform, Load) and ELT pipelines (Extract, Load, Transform) are both used to transfer data from one system to another.
In addition to using cloud for storage, many modern data architectures make use of cloud computing to analyze and manage data. Modern data architectures use APIs to make it easy to expose and share data. AI and machinelearning models. Dataintegrity. Scalable data pipelines.
destination fields may contain no more than 10 characters) Frequency of transfer for dataintegration cases (e.g. transfer data from source to target every 12 hours). If you’re aiming for uninterrupted data flow and accurate data, thorough data mapping is a critical piece of the puzzle.
Introduction Data is, somewhat, everything in the business world. To state the least, it is hard to imagine the world without data analysis, predictions, and well-tailored planning! 95% of C-level executives deem dataintegral to business strategies.
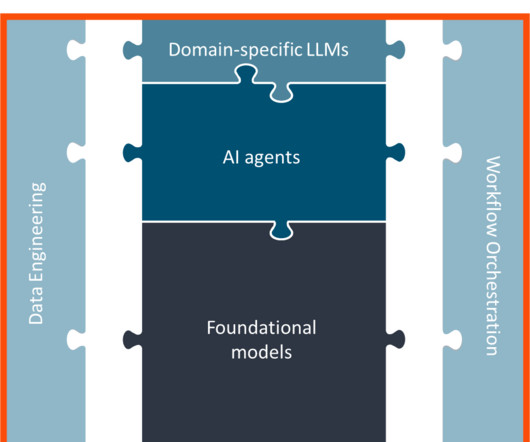
Applying customization techniques like prompt engineering, retrieval augmented generation (RAG), and fine-tuning to LLMs involves massive data processing and engineering costs that can quickly spiral out of control depending on the level of specialization needed for a specific task.
As data volumes grow and sources diversify, manual quality checks become increasingly impractical and error-prone. This is where automated data quality checks come into play, offering a scalable solution to maintain dataintegrity and reliability.
The development of business intelligence to analyze and extract value from the countless sources of data that we gather at a high scale, brought alongside a bunch of errors and low-quality reports: the disparity of data sources and data types added some more complexity to the dataintegration process.
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
Finally, the Gold laye r represents the pinnacle of the Medallion architecture, housing fully refined, aggregated, and analysis-ready data. Data is typically organized into project-specific schemas optimized for business intelligence (BI) applications, advanced analytics, and machinelearning.
Recognizing and rewarding data-centric achievements reinforces the value placed on analytical ability. Establishing clear accountability ensures dataintegrity. Implementing Service Level Agreements (SLAs) for data quality and availability sets measurable standards, promoting responsibility and trust in data assets.
AI (Artificial Intelligence) and ML (MachineLearning) will bring improvement in Fintech in 2021 as the accuracy and personalization of payment, lending, and insurance services while also assisting in the discovery of new client pools. For saving time and resources in Fintech Business on the need to involve Automation in it.
AWS offers AWS Glue to help you integrate your data from multiple sources on serverless infrastructure for analysis, machinelearning (ML), and application development. AWS Glue provides different authoring experiences for you to build dataintegration jobs. This integration is available today in US East (N.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machinelearning and generative AI. Dataintegrity presented a major challenge for the team, as there were many instances of duplicate data.
ChatGPT> DataOps is a term that refers to the set of practices and tools that organizations use to improve the quality and speed of data analytics and machinelearning. It involves bringing together people, processes, and technology to enable data-driven decision making and improve the efficiency of data-related workflows.
From the Unified Studio, you can collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics. This experience includes visual ETL, a new visual interface that makes it simple for data engineers to author, run, and monitor extract, transform, load (ETL) dataintegration flow.
Our customers are telling us that they are seeing their analytics and AI workloads increasingly converge around a lot of the same data, and this is changing how they are using analytics tools with their data. They aren’t using analytics and AI tools in isolation.
In this edition of GraphDB In Action, we present to you the work of three bright researchers who have set out to find solutions that allow meaningful analysis and interpretation of data, supported by Ontotext GraphDB. The study discusses the key concepts and technologies related to semantic dataintegration in the field of brain diseases.
With thousands in attendance and growing fast, this year's conference focused on five key areas: digitization, real time connectivity, driving insight based actions, applying AI & machinelearning, and building applications. All of these announcements are aimed at broadening the workloads supported by Domo.
Validations and tests are key elements to building machinelearning pipelines you can trust. We've also talked about incorporating tests in your pipeline, which many data scientists find problematic. Enter Deepchecks - an open source Python package for testing and validating machinelearning models and data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content