This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
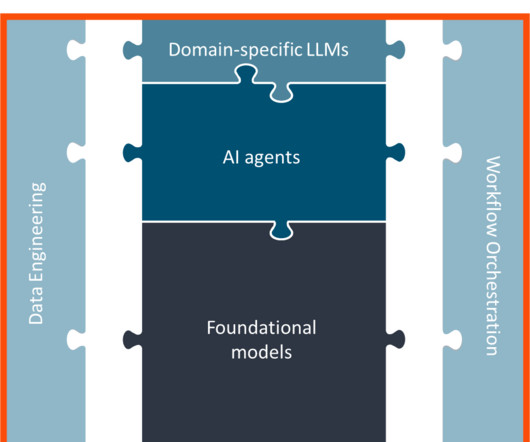
Additionally, as I recently explained , the companys platform addresses a broad range of capabilities that includes data governance and security, dataintegration and application development, as well as the automation and incorporation of artificial intelligence (AI) and machinelearning (ML) models into BI and analytics.
We have also included vendors for the specific use cases of ModelOps, MLOps, DataGovOps and DataSecOps which apply DataOps principles to machinelearning, AI, data governance, and data security operations. . Dagster / ElementL — A data orchestrator for machinelearning, analytics, and ETL. .
Applying customization techniques like prompt engineering, retrieval augmented generation (RAG), and fine-tuning to LLMs involves massive data processing and engineering costs that can quickly spiral out of control depending on the level of specialization needed for a specific task.
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional dataintegration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
At Atlanta’s Hartsfield-Jackson International Airport, an IT pilot has led to a wholesale data journey destined to transform operations at the world’s busiest airport, fueled by machinelearning and generative AI. Dataintegrity presented a major challenge for the team, as there were many instances of duplicate data.
Inflexible schema, poor for unstructured or real-time data. Data lake Raw storage for all types of structured and unstructureddata. Low cost, flexibility, captures diverse data sources. Easy to lose control, risk of becoming a data swamp. Exploratory analytics, raw and diverse data types.
Unstructured. Unstructureddata lacks a specific format or structure. As a result, processing and analyzing unstructureddata is super-difficult and time-consuming. Semi-structured data contains a mixture of both structured and unstructureddata. DataIntegration. Semi-structured.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
My vision is that I can give the keys to my businesses to manage their data and run their data on their own, as opposed to the Data & Tech team being at the center and helping them out,” says Iyengar, director of Data & Tech at Straumann Group North America. The company’s Findability.ai
While the partnership with AWS is focused on providing more data and analytics capabilities for the M&E sector, the Cognizant partnership is aimed at maintaining video quality for customers. The joint solution with Labelbox is targeted toward media companies and is expected to help firms derive more value out of unstructureddata.
They support structured, semi-structured, and unstructureddata, offering a flexible and scalable environment for data ingestion from multiple sources. Data lakes provide a unified repository for organizations to store and use large volumes of data. This ensures consistent and effective responses to all incidents.
Amazon SageMaker Introducing the next generation of Amazon SageMaker AWS announces the next generation of Amazon SageMaker, a unified platform for data, analytics, and AI. enables you to develop, run, and scale your dataintegration workloads and get insights faster. With AWS Glue 5.0, AWS Glue 5.0 AWS Glue 5.0
There are three technological advances driving this data consumption and, in turn, the ability for employees to leverage this data to deliver business value 1) exploding data production 2) scalable big data computation, and 3) the accessibility of advanced analytics, machinelearning (ML) and artificial intelligence (AI).
We know very well that the FAIR principles are influenced by the Linked Data Principles, which play a significant role at the core of knowledge graphs. In particular, in situations where storing personal data in one place would be problematic, knowledge graphs enable easy linking and querying of data, taking a step in this direction.
In all cases the data will eventually be loaded into a different place, so it can be managed, and organized, using a package such as Sisense for Cloud Data Teams. Using data pipelines and dataintegration between data storage tools, engineers perform ETL (Extract, transform and load).
In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machinelearning, data engineering, distributed microservices, and full stack systems. Other sought-after skills include Python, R, JavaScript, C++, Apache Spark, and Hadoop. .
In-demand skills for the role include programming languages such as Scala, Python, open-source RDBMS, NoSQL, as well as skills involving machinelearning, data engineering, distributed microservices, and full stack systems. Other sought-after skills include Python, R, JavaScript, C++, Apache Spark, and Hadoop. .
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic dataintegration , and ontology building.
Some examples include AWS data analytics services such as AWS Glue for dataintegration, Amazon QuickSight for business intelligence (BI), as well as third-party software and services from AWS Marketplace. We create an S3 bucket to store data that exceeds the Lambda function’s response size limits.
We’ve seen a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. With these connectors, you can bring the data from Azure Blob Storage and Azure Data Lake Storage separately to Amazon S3.
IBM, a pioneer in data analytics and AI, offers watsonx.data, among other technologies, that makes possible to seamlessly access and ingest massive sets of structured and unstructureddata. AWS’s secure and scalable environment ensures dataintegrity while providing the computational power needed for advanced analytics.
Ring 3 uses the capabilities of Ring 1 and Ring 2, including the dataintegration capabilities of the platform for terminology standardization and person matching. The introduction of Generative AI offers to take this solution pattern a notch further, particularly with its ability to better handle unstructureddata.
It ensures compliance with regulatory requirements while shifting non-sensitive data and workloads to the cloud. Its built-in intelligence automates common data management and dataintegration tasks, improves the overall effectiveness of data governance, and permits a holistic view of data across the cloud and on-premises environments.
Instead of relying on one-off scripts or unstructured transformation logic, dbt Core structures transformations as models, linking them through a Directed Acyclic Graph (DAG) that automatically handles dependencies. The following categories of transformations pose significant limitations for dbt Cloud and dbtCore : 1.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. .
We’ve seen that there is a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. With this connector, you can bring the data from Google Cloud Storage to Amazon S3.
A data catalog is a central hub for XAI and understanding data and related models. While “operational exhaust” arrived primarily as structured data, today’s corpus of data can include so-called unstructureddata. MachineLearning Technology. Other Technologies. Conclusion.
One key component that plays a central role in modern data architectures is the data lake, which allows organizations to store and analyze large amounts of data in a cost-effective manner and run advanced analytics and machinelearning (ML) at scale. To overcome these issues, Orca decided to build a data lake.
Data within a data fabric is defined using metadata and may be stored in a data lake, a low-cost storage environment that houses large stores of structured, semi-structured and unstructureddata for business analytics, machinelearning and other broad applications.
In today’s data-driven world, businesses are drowning in a sea of information. Traditional dataintegration methods struggle to bridge these gaps, hampered by high costs, data quality concerns, and inconsistencies. This is the power of Zenia Graph’s services and solution powered by Ontotext GraphDB.
Handle increases in data volume gracefully. Support machinelearning (ML) algorithms and data science activities, to help with name matching, risk scoring, link analysis, anomaly detection, and transaction monitoring. Provide audit and data lineage information to facilitate regulatory reviews. Cloudera Enterprise.
This type of flexible, cloud-based data management allows 3M HIS to aggregate different data sets for different purposes, ensuring both dataintegrity and faster processing. This is a dynamic view on data that evolves over time,” said Koll. s legendary culture of innovation.
For efficient drug discovery, linked data is key. The actual process of dataintegration and the subsequent maintenance of knowledge requires a lot of time and effort. It is increasingly the case that AI is making the rote decisions such as Ontotext’s NLP plugins for automating semantic tagging.
From a technological perspective, RED combines a sophisticated knowledge graph with large language models (LLM) for improved natural language processing (NLP), dataintegration, search and information discovery, built on top of the metaphactory platform. Using machinelearning, RED indicates the impact of events on stock prices.
Because Alex can use a data catalog to search all data assets across the company, she has access to the most relevant and up-to-date information. She can search structured or unstructureddata, visualizations and dashboards, machinelearning models, and database connections.
However, the data source for the dashboard still resided in an Aurora MySQL database and only covered a single data domain. The initial data warehouse design in Ruparupa only stored transactional data, and data from other systems including user interaction data wasn’t consolidated yet.
This example combines three types of unrelated data: Legal entity data: Two companies with completely unrelated business lines (coffee and waste management) merged together; Unstructureddata: Fraudulent promotion campaigns took place through press releases and a fake stock-picking robot. Conclusion.
Recently, Spark set a new record by processing 100 terabytes of data in just 23 minutes, surpassing Hadoop’s previous world record of 71 minutes. This is why big tech companies are switching to Spark as it is highly suitable for machinelearning and artificial intelligence.
Let’s discuss what data classification is, the processes for classifying data, data types, and the steps to follow for data classification: What is Data Classification? As your organization collects and uses more data, manual data classification becomes overwhelming for data owners.
According to Gartner , lack of data management practices and rigor around governance can introduce risk and significantly impede data and analytics strategic readiness and ultimately AI readiness. This capability has become increasingly more critical as organizations incorporate more unstructureddata into their data warehouses.
Today transactional data is the largest segment, which includes streaming and data flows. EXTRACTING VALUE FROM DATA. One of the biggest challenges presented by having massive volumes of disparate unstructureddata is extracting useable information and insights. These challenges can be summarised as follows.
Data Migration Pipelines : These pipelines move data from one system to another, often for the purpose of upgrading systems or consolidating data sources. For example, migrating customer data from an on-premises database to a cloud-based CRM system. structured, semi-structured, or unstructureddata).
The companys Data Intelligence Platform is now positioned as providing a lakehouse-based environment for data engineering, data warehousing, stream data processing, data governance, data sharing, business intelligence (BI), data science and AI.
From data masking technologies that ensure unparalleled privacy to cloud-native innovations driving scalability, these trends highlight how enterprises can balance innovation with accountability. AI-driven platforms process vast datasets to identify patterns, automating tasks like metadata tagging, schema creation and data lineage mapping.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content