This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional dataintegration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
As a result, many data teams were not as productive as they might be, with time and effort spent on manually troubleshooting data-quality issues and testing data pipelines. With the aim of rectifying that situation, Bigeye’s founders set out to build a business around data observability.
A recent survey investigated how companies are approaching their AI and ML practices, and measured the sophistication of their efforts. In order to have a longstanding AI and ML practice, companies need to have data infrastructure in place to collect, transform, store, and manage data.
It’s also a critical trait for the data assets of your dreams. What is data with integrity? Dataintegrity is the extent to which you can rely on a given set of data for use in decision-making. Where can dataintegrity fall short? Too much or too little access to data systems.
Speaker: Dave Mariani, Co-founder & Chief Technology Officer, AtScale; Bob Kelly, Director of Education and Enablement, AtScale
Given how data changes fast, there’s a clear need for a measuring stick for data and analytics maturity. Workshop video modules include: Breaking down data silos. Integratingdata from third-party sources. Developing a data-sharing culture. Combining dataintegration styles.
Shared data assets, such as product catalogs, fiscal calendar dimensions, and KPI definitions, require a common vocabulary to help avoid disputes during analysis. Curate the data. Invest in core functions that perform data curation such as modeling important relationships, cleansing raw data, and curating key dimensions and measures.
As data ingestion transitions to a continuous flow, the second part of DQ training equips engineers to monitor schema consistency, row counts, and data freshness, ensuring dataintegrity over time. The faster the iteration, the more organizations learn, refine their processes, and elevate their data quality standards.
So from the start, we have a dataintegration problem compounded with a compliance problem. An AI project that doesn’t address dataintegration and governance (including compliance) is bound to fail, regardless of how good your AI technology might be. Decide where data fits in. What data do you have?
While value-based pricing is appealing in theory, it can be extremely difficult to measure and implement in practice. This can not only reduce costs but also simplify your IT landscape and improve dataintegration. This shift is partly driven by economic uncertainty and the need for businesses to justify every expense.
‘Using anomaly alerts and monitoring tools, business team members can quickly establish key performance indicators (KPIs) and personalized alerts and reports to monitor and measure results with powerful, clear, concise results that help users to understand and manage the variables that impact their targets and their results.’
Machine learning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Dataintegration and cleaning.
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
Chris will overview data at rest and in use, with Eric returning to demonstrate the practical steps in data testing for both states. Session 3: Mastering Data Testing in Development and Migration During our third session, the focus will shift towards regression and impact assessment in development cycles. Reserve Your Spot!
But in the four years since it came into force, have companies reached their full potential for dataintegrity? But firstly, we need to look at how we define dataintegrity. What is dataintegrity? Many confuse dataintegrity with data quality. Is integrity a universal truth?
In this paper, I show you how marketers can improve their customer retention efforts by 1) integrating disparate data silos and 2) employing machine learning predictive analytics. Your marketing strategy is only as good as your ability to deliver measurable results. DataIntegration as your Customer Genome Project.
At the recent Strata Data conference we had a series of talks on relevant cultural, organizational, and engineering topics. Here's a list of a few clusters of relevant sessions from the recent conference: DataIntegration and Data Pipelines. Data Platforms. Model lifecycle management.
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG dataintegrity and fostering collaboration with sustainability teams.
We talk about systemic change, and it certainly helps to have the support of management, but data engineers should not underestimate the power of the keyboard. Instead, you’ll focus on managing change in governance policies and implementing the automated systems that enforce, measure, and report governance.
From reactive fixes to embedded data quality Vipin Jain Breaking free from recurring data issues requires more than cleanup sprints it demands an enterprise-wide shift toward proactive, intentional design. Data quality must be embedded into how data is structured, governed, measured and operationalized.
Data lineage, data catalog, and data governance solutions can increase usage of data systems by enhancing trustworthiness of data. Moving forward, tracking data provenance is going to be important for security, compliance, and for auditing and debugging ML systems. Data Platforms.
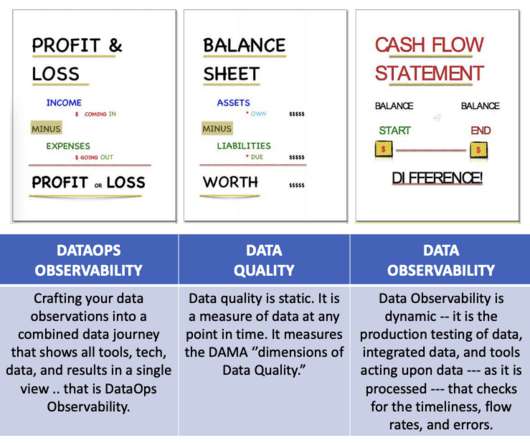
Question: What is the difference between Data Quality and Observability in DataOps? Data Quality is static. It is the measure of data sets at any point in time. A financial analogy: Data Quality is your Balance Sheet, Data Observability is your Cash Flow Statement.
In our previous blog post “ Proven AI solutions for modern planning “, we shared detailed insights from Dr. Rolf Gegenmantel, our Chief Marketing & Product Officer, into data management and dataintegration as a basis for advanced analytics and automated sales forecasts at Mitsui Chemicals Europe.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. To incorporate this third-party data, AWS Data Exchange is the logical choice.
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, DataIntegrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines. Azure DevOps. AWS Code Deploy.
How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising dataintegrity and compliance? While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business.
While real-time data is processed by other applications, this setup maintains high-performance analytics without the expense of continuous processing. This agility accelerates EUROGATEs insight generation, keeping decision-making aligned with current data.
Therefore, loss of data due to a cyber-attack would mean that your company does not value its consumers’ privacy and does not implement the necessary steps to ensure data protection. Usually, we find that the majority of cyber-attack victims are small businesses that are complacent with their data security measures.
Residuals are a numeric measurement of model errors, essentially the difference between the model’s prediction and the known true outcome. There are several known attacks against machine learning models that can lead to altered, harmful model outcomes or to exposure of sensitive training data. [8] Residual analysis.
This includes defining the main stakeholders, assessing the situation, defining the goals, and finding the KPIs that will measure your efforts to achieve these goals. A planned BI strategy will point your business in the right direction to meet its goals by making strategic decisions based on real-time data.
Data doubt compounds tough edge challenges The variety of operational challenges at the edge are compounded by the difficulties of sourcing trustworthy data sets from heterogeneous IT/OT estates. Consequently, implementing continuous monitoring systems in these conditions is often not practical or effective.
An automated process that catches errors early in the process gives the data team the maximum available time to resolve the problem – patch the data, contact data suppliers, and rerun processing steps. The measurement and monitoring of your end-to-end process can serve as an important tool in the battle to eliminate errors.
After navigating the complexity of multiple systems and stages to bring data to its end-use case, the final product’s value becomes the ultimate yardstick for measuring success. By diligently testing and monitoring data in Use, you uphold dataintegrity and provide tangible value to end-users.
These 10 strategies cover every critical aspect, from dataintegrity and development speed, to team expertise and executive buy-in. Data done right Neglect data quality and you’re doomed. It’s simple: your AI is only as good as the data it learns from. Implement stringent security measures from the start.
The development of business intelligence to analyze and extract value from the countless sources of data that we gather at a high scale, brought alongside a bunch of errors and low-quality reports: the disparity of data sources and data types added some more complexity to the dataintegration process.
Dataintegrity constraints: Many databases don’t allow for strange or unrealistic combinations of input variables and this could potentially thwart watermarking attacks. Applying dataintegrity constraints on live, incoming data streams could have the same benefits. Disparate impact analysis: see section 1.
Here, I’ll highlight the where and why of these important “dataintegration points” that are key determinants of success in an organization’s data and analytics strategy. It’s the foundational architecture and dataintegration capability for high-value data products. Data and cloud strategy must align.
Each of that component has its own purpose that we will discuss in more detail while concentrating on data warehousing. A solid BI architecture framework consists of: Collection of data. Dataintegration. Storage of data. Data analysis. Distribution of data. Dataintegration.
Couple this with the results of a study published in the Harvard Business Review which finds that only 3% of companies data meets basic quality standards ! Redman and David Sammon, propose an interesting (and simple) exercise to measuredata quality. Authors, Tadhg Nagle, Thomas C.
In today’s data-powered world with data fueling everything from essential management systems to customer-focused AI solutions , one thing that often gets in the way is data fragmentation. . Why Dataintegration plays a vital role for gaming companies? Naturally, the player journey is segmented into six parts, .
She is a data enthusiast who enjoys problem solving and tackling complex architectural challenges with customers. She is passionate about designing and building end-to-end solutions to address customer dataintegration and analytic needs. Big Data Architect. Zach Mitchell is a Sr.
Verifying data completeness and conformity to predefined standards. Critical Questions for Data Ingestion Monitoring Effective data ingestion anomaly monitoring should address several critical questions to ensure dataintegrity: Are there any unknown anomalies affecting the data?
This furthers the opportunity for hackers to target AI systems, exploiting vulnerabilities that can compromise dataintegrity, operational functionality, and regulatory compliance. The need for robust security measures is underscored by several key factors.
DynamoDB is generally considered to be the more secure of the two — with the full power of AWS’ security measures behind it. DynamoDB integrates with AWS security services so you can use your own encryption keys, which you can do as well on MongoDB using the key management system available on whatever cloud provider you utilize.
By applying machine learning to the data, you can better predict customer behavior. Gartner has identified four main types of CDPs: marketing cloud CDPs, CDP engines and toolkits, marketing data-integration CDPs, and CDP smart hubs. Treasure Data CDP is a data science CDP built for predictive modeling and advanced analytics.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content