This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the age of big data, where information is generated at an unprecedented rate, the ability to integrate and manage diverse data sources has become a critical business imperative. Traditional dataintegration methods are often cumbersome, time-consuming, and unable to keep up with the rapidly evolving data landscape.
From reactive fixes to embedded data quality Vipin Jain Breaking free from recurring data issues requires more than cleanup sprints it demands an enterprise-wide shift toward proactive, intentional design. Data quality must be embedded into how data is structured, governed, measured and operationalized.
How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising dataintegrity and compliance? While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business.
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, DataIntegrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines. Azure DevOps. AWS Code Deploy.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
This includes defining the main stakeholders, assessing the situation, defining the goals, and finding the KPIs that will measure your efforts to achieve these goals. IT should be involved to ensure governance, knowledge transfer, dataintegrity, and the actual implementation. Because it is that important.
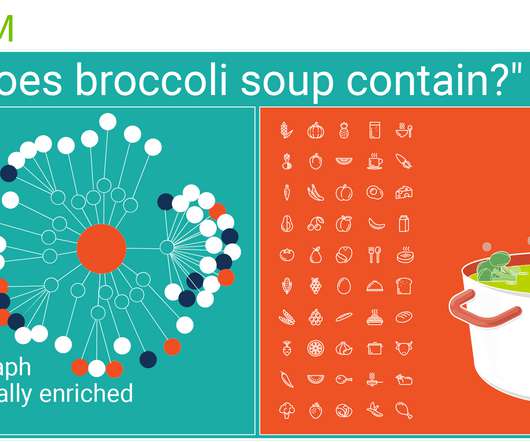
What lies behind building a “nest” from irregularly shaped, ambiguous and dynamic “strings” of human knowledge, in other words of unstructureddata? To do that Edamam, together with Ontotext, worked to develop a knowledge graph with semantically enriched nutrition data. 450 g chicken broth, or more for thinning.
Your LLM Needs a Data Journey: A Comprehensive Guide for Data Engineers The rise of Large Language Models (LLMs) such as GPT-4 marks a transformative era in artificial intelligence, heralding new possibilities and challenges in equal measure.
From stringent data protection measures to complex risk management protocols, institutions must not only adapt to regulatory shifts but also proactively anticipate emerging requirements, as well as predict negative outcomes.
The power of BI insight enables any group or organization’s processes, initiatives, and projects to be well shown and measured. Data Dashboard Tool. Why Data Dashboard? Undoubtedly, a data dashboard tool helps you answer a barrage of business-related questions in order to cater to your own strategies. KPI Data Dashboard.
In the era of big data, data lakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructureddata, offering a flexible and scalable environment for data ingestion from multiple sources.
When combined with artificial intelligence (AI), an interoperable healthcare data platform has the potential to bring about one of the most transformational changes in history to US healthcare, moving from a system in which events are currently understood and measured in days, weeks, or months into a real-time inter-connected ecosystem.
IBM, a pioneer in data analytics and AI, offers watsonx.data, among other technologies, that makes possible to seamlessly access and ingest massive sets of structured and unstructureddata. Real-world Business Solutions The real value of any technology is measured by its impact on real-world problems.
It ensures compliance with regulatory requirements while shifting non-sensitive data and workloads to the cloud. Its built-in intelligence automates common data management and dataintegration tasks, improves the overall effectiveness of data governance, and permits a holistic view of data across the cloud and on-premises environments.
Back-end software engineers are responsible for maintaining the structure of server-side information by optimizing servers, implementing security measures, and developing data storage solutions. Back-end software engineer.
Back-end software engineers are responsible for maintaining the structure of server-side information by optimizing servers, implementing security measures, and developing data storage solutions. Back-end software engineer.
For example, IDP uses native AI to quickly and accurately extract data from business documents of all types, for both structured and unstructureddata,” Reis says. This is especially important for us because our work spans many forms of content — from more traditional form-based documents to unstructured email communications.”
We’ve seen that there is a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. With this connector, you can bring the data from Google Cloud Storage to Amazon S3.
In today’s data-driven world, businesses are drowning in a sea of information. Traditional dataintegration methods struggle to bridge these gaps, hampered by high costs, data quality concerns, and inconsistencies. This is the power of Zenia Graph’s services and solution powered by Ontotext GraphDB.
Institutional memory loss creates significant and measurable inefficiencies. For efficient drug discovery, linked data is key. The actual process of dataintegration and the subsequent maintenance of knowledge requires a lot of time and effort. The Cost of Memory Loss.
Both approaches were typically monolithic and centralized architectures organized around mechanical functions of data ingestion, processing, cleansing, aggregation, and serving. Deciding on KPIs to gauge a data architecture’s effectiveness. Creating a data architecture roadmap.
Achieving this advantage is dependent on their ability to capture, connect, integrate, and convert data into insight for business decisions and processes. This is the goal of a “data-driven” organization. We call this the “ Bad Data Tax ”.
From a technological perspective, RED combines a sophisticated knowledge graph with large language models (LLM) for improved natural language processing (NLP), dataintegration, search and information discovery, built on top of the metaphactory platform. Let’s have a quick look under the bonnet.
Here are some key factors to keep in mind: Understanding business objectives : It is important to identify and understand the business objectives before selecting a big data tool. These objectives should be broken down into measurable analytical goals, and the chosen tool should be able to meet those goals. Top 10 Big Data Tools 1.
However, the data source for the dashboard still resided in an Aurora MySQL database and only covered a single data domain. The initial data warehouse design in Ruparupa only stored transactional data, and data from other systems including user interaction data wasn’t consolidated yet.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content