This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale data lakes without requiring complex custom code.
As artificial intelligence (AI) and machine learning (ML) continue to reshape industries, robust data management has become essential for organizations of all sizes. This means organizations must cover their bases in all areas surrounding data management including security, regulations, efficiency, and architecture.
Despite their advantages, traditional data lake architectures often grapple with challenges such as understanding deviations from the most optimal state of the table over time, identifying issues in data pipelines, and monitoring a large number of tables. It is essential for optimizing read and write performance.
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability.
With graph databases the representation of relationships as data make it possible to better represent data in real time, addressing newly discovered types of data and relationships. Relational databases benefit from decades of tweaks and optimizations to deliver performance. Metadata about Relationships Come in Handy.
Some challenges include data infrastructure that allows scaling and optimizing for AI; data management to inform AI workflows where data lives and how it can be used; and associated data services that help data scientists protect AI workflows and keep their models clean. Seamless dataintegration.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog. This process is shown in the following figure.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimaldata layout recommendations for distribution and sort keys, further optimizing performance.
Then there’s unstructured data with no contextual framework to govern data flows across the enterprise not to mention time-consuming manual data preparation and limited views of data lineage. So here’s why data modeling is so critical to data governance. erwin Data Modeler: Where the Magic Happens.
The only question is, how do you ensure effective ways of breaking down data silos and bringing data together for self-service access? It starts by modernizing your dataintegration capabilities – ensuring disparate data sources and cloud environments can come together to deliver data in real time and fuel AI initiatives.
We won’t be writing code to optimize scheduling in a manufacturing plant; we’ll be training ML algorithms to find optimum performance based on historical data. With machine learning, the challenge isn’t writing the code; the algorithms are implemented in a number of well-known and highly optimized libraries.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, move, and integratedata from multiple sources for analytics, machine learning (ML), and application development. MongoDB Atlas is a developer data service from AWS technology partner MongoDB, Inc.
S3 Tables are specifically optimized for analytics workloads, resulting in up to 3 times faster query throughput and up to 10 times higher transactions per second compared to self-managed tables. These metadata tables are stored in S3 Tables, the new S3 storage offering optimized for tabular data. With AWS Glue 5.0,
These tools range from enterprise service bus (ESB) products, dataintegration tools; extract, transform and load (ETL) tools, procedural code, application program interfaces (APIs), file transfer protocol (FTP) processes, and even business intelligence (BI) reports that further aggregate and transform data.
Cloudinary is a cloud-based media management platform that provides a comprehensive set of tools and services for managing, optimizing, and delivering images, videos, and other media assets on websites and mobile applications. This concept makes Iceberg extremely versatile.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. As stated earlier, the first step involves data ingestion.
AWS Transfer Family seamlessly integrates with other AWS services, automates transfer, and makes sure data is protected with encryption and access controls. Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. 2 GB into the landing zone daily.
Not surprisingly, dataintegration and ETL were among the top responses, with 60% currently building or evaluating solutions in this area. In an age of data-hungry algorithms, everything really begins with collecting and aggregating data. Metadata and artifacts needed for audits. and managed services in the cloud.
At DataKitchen, we think of this is a ‘meta-orchestration’ of the code and tools acting upon the data. Data Pipeline Observability: Optimizes pipelines by monitoring data quality, detecting issues, tracing data lineage, and identifying anomalies using live and historical metadata.
Data governance principles According to the Data Governance Institute, eight principles are at the center of all successful data governance and stewardship programs: All participants must have integrity in their dealings with each other. The program must introduce and support standardization of enterprise data.
Denodo also offers query optimization and acceleration capabilities to deliver high-performance analytics, as well as support for business semantics and security and access controls. The breadth and depth of Denodo Platform’s functionality is illustrated by its designation as a Leader in Capability in our 2024 DataIntegration Buyers Guide.
Through their unique position in ports, at sea, and on roads, they optimize global cargo flows and create sustainable customer value. Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. An AWS Glue job (metadata exporter) runs daily on the source account.
Agile BI and Reporting, Single Customer View, Data Services, Web and Cloud Computing Integration are scenarios where Data Virtualization offers feasible and more efficient alternatives to traditional solutions. Does Data Virtualization support web dataintegration? In improving operational processes.
A recipe for trustworthy data As the compute stack becomes more distributed across constrained environments, companies need the ability to prove dataintegrity through a trust fabric to unlock data insights they can rely on. Specifically, what the DCF does is capture metadata related to the application and compute stack.
What, then, should users look for in a data modeling product to support their governance/intelligence requirements in the data-driven enterprise? Nine Steps to Data Modeling. Provide metadata and schema visualization regardless of where data is stored. naming and database standards, formatting options, and so on.
KGs bring the Semantic Web paradigm to the enterprises, by introducing semantic metadata to drive data management and content management to new levels of efficiency and breaking silos to let them synergize with various forms of knowledge management. Take this restaurant, for example. Enterprise Knowledge Graphs and the Semantic Web.
We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless dataintegration service, to generate a catalog for access logs and create dashboards for insights. Both the user data and logs buckets must be in the same AWS Region and owned by the same account.
Hudi provides tables , transactions , efficient upserts and deletes , advanced indexes , streaming ingestion services , data clustering and compaction optimizations, and concurrency control , all while keeping your data in open source file formats. This effectively provides change streams to enable incremental data pipelines.
L1 is usually the raw, unprocessed data ingested directly from various sources; L2 is an intermediate layer featuring data that has undergone some form of transformation or cleaning; and L3 contains highly processed, optimized, and typically ready for analytics and decision-making processes.
Despite soundings on this from leading thinkers such as Andrew Ng , the AI community remains largely oblivious to the important data management capabilities, practices, and – importantly – the tools that ensure the success of AI development and deployment. Further, data management activities don’t end once the AI model has been developed.
Figure 1: Apache Iceberg fits the next generation data architecture by abstracting storage layer from analytics layer while introducing net new capabilities like time-travel and partition evolution. #1: Apache Iceberg enables seamless integration between different streaming and processing engines while maintaining dataintegrity between them.
This introduces the need for both polling and pushing the data to access and analyze in near-real time. From an operational standpoint, we designed a new shared responsibility model for data ingestion using AWS Glue instead of internal services (REST APIs) designed on Amazon EC2 to extract the data.
Modernizing analytics for scale, performance, and reliability “Our migration from legacy on-premises platform to Amazon Redshift allows us to ingest data 88% faster, query data 3x faster, and load daily data to the cloud 6x faster. Here’s a couple of highlights from this week and for the full list, see below.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic.
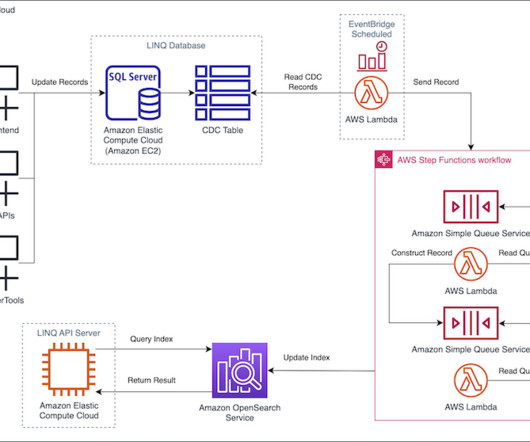
During implementation, the LINQ team worked with OpenSearch Service specialists to optimize the OpenSearch Service cluster configuration to maximize performance and optimize cost of the solution. This results in an optimized record for each product for quick and efficient search in OpenSearch Service.
Get a closer look at how scaling for data warehousing works in AWS with the latest introduction of AI driven scaling and optimizations in Amazon Redshift Serverless to enable better price-performance for your workloads. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
Addressing big data challenges – Big data comes with unique challenges, like managing large volumes of rapidly evolving data across multiple platforms. Effective permission management helps tackle these challenges by controlling how data is accessed and used, providing dataintegrity and minimizing the risk of data breaches.
Ontotext’s GraphDB is an enterprise-ready semantic graph database (also called RDF triplestore as it stores data in RDF triples). It provides the core infrastructure for solutions where modeling agility, dataintegration, relationship exploration, cross-enterprise data publishing and consumption are critical.
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence (BI) tools. It provides secure, real-time access to Redshift data without copying, keeping enterprise data in place.
While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake. Now the admins need to synchronize multiple copies of the data and metadata and ensure that users across the many clusters are not viewing stale information.
The Iceberg specification allows seamless table evolution such as schema and partition evolution, and its design is optimized for usage on Amazon S3. Iceberg stores the metadata pointer for all the metadata files. In this post, we use the Yellow taxi public dataset from NYC Taxi & Limousine Commission as our source data.
A market in need of more interoperability Systems integrators and cloud services teams have stepped in to remedy some of multicloud’s interoperability hurdles, but the optimal solution is for public cloud providers to build APIs directly into the cloud stack layer, Gartner’s Nag says.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content