This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale data lakes without requiring complex custom code.
This is a graph of millions of edges and vertices – in enterprise data management terms it is a giant piece of master/referencedata. Not Every Graph is a Knowledge Graph: Schemas and Semantic Metadata Matter. They aren’t concerned with publishing or integratingdata.
Organization’s cannot hope to make the most out of a data-driven strategy, without at least some degree of metadata-driven automation. The volume and variety of data has snowballed, and so has its velocity. As such, traditional – and mostly manual – processes associated with data management and data governance have broken down.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Industry-leading price-performance: Amazon Redshift launches RA3.large
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
If you’re a mystery lover, I’m sure you’ve read that classic tale: Sherlock Holmes and the Case of the Deceptive Data, and you know how a metadata catalog was a key plot element. In The Case of the Deceptive Data, Holmes is approached by B.I. He goes on to explain: Reasons for inaccurate data. Big data is BIG.
Data poisoning attacks. Data poisoning refers to someone systematically changing your training data to manipulate your model’s predictions. Data poisoning attacks have also been called “causative” attacks.) To poison data, an attacker must have access to some or all of your training data.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, move, and integratedata from multiple sources for analytics, machine learning (ML), and application development. MongoDB Atlas is a developer data service from AWS technology partner MongoDB, Inc.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics. Amazon Athena is used to query, and explore the data.
SageMaker still includes all the existing ML and AI capabilities you’ve come to know and love for data wrangling, human-in-the-loop data labeling with Amazon SageMaker Ground Truth , experiments, MLOps, Amazon SageMaker HyperPod managed distributed training, and more. Having confidence in your data is key.
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
Many longstanding providers of data management products, such as Informatica, have adopted DataOps capabilities and methodologies, adapting product portfolios to cloud-based consumption and automated, collaborative and agile processes. Informatica is still closely associated with dataintegration.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. The program must introduce and support standardization of enterprise data.
If you suddenly see unexpected patterns in your social data, that may mean adversaries are attempting to poison your data sources. Anomaly detection may have originated in finance, but it is becoming a part of every data scientist’s toolkit. Tim Kraska on “How machine learning will accelerate data management systems”.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
The Solution: ‘Payload’ Data Journeys Traditional Data Observability usually focuses on a ‘process journey,’ tracking the performance and status of data pipelines. ’ It assigns unique identifiers to each data item—referred to as ‘payloads’—related to each event.
Your organization won’t be able to take complete advantage of analytics tools to become data-driven unless you establish a foundation for agile and complete data management. You need automated data mapping and cataloging through the integration lifecycle process, inclusive of data at rest and data in motion.
KGs bring the Semantic Web paradigm to the enterprises, by introducing semantic metadata to drive data management and content management to new levels of efficiency and breaking silos to let them synergize with various forms of knowledge management. Take this restaurant, for example. Enterprise Knowledge Graphs and the Semantic Web.
Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time. Apache Iceberg offers integrations with popular data processing frameworks such as Apache Spark, Apache Flink, Apache Hive, Presto, and more.
Although the terms data fabric and data mesh are often used interchangeably, I previously explained that they are distinct but complementary. The company added a variety of new features with the launch of Denodo Platform 9 in June, designed to address requirements for intelligent applications and AI-driven integration.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data discoverability Unlike structured data, which is managed in well-defined rows and columns, unstructured data is stored as objects.
For this, Cargotec built an Amazon Simple Storage Service (Amazon S3) data lake and cataloged the data assets in AWS Glue Data Catalog. They chose AWS Glue as their preferred dataintegration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
Iceberg stores the metadata pointer for all the metadata files. When a SELECT query is reading an Iceberg table, the query engine first goes to the Iceberg catalog, then retrieves the entry of the location of the latest metadata file, as shown in the following diagram.
We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless dataintegration service, to generate a catalog for access logs and create dashboards for insights. They store attributes such as object size, total time, turn-around time, and HTTP referer for log records.
It provides secure, real-time access to Redshift data without copying, keeping enterprise data in place. This eliminates replication overhead and ensures access to current information, enhancing dataintegration while maintaining dataintegrity and efficiency.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic.
.’ It’s not just about playing detective to discover where things went wrong; it’s about proactively monitoring your entire data journey to ensure everything goes right with your data. What is Data in Place? This existing paradigm fails to address the challenges and intricacies of “Data in Use.”
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. To address this challenge, organizations can deploy a data mesh using AWS Lake Formation that connects the multiple EMR clusters. An entity can act both as a producer of data assets and as a consumer of data assets.
In most companies, an incredible amount of data flows from multiple sources in a variety of formats and is constantly being moved and federated across a changing system landscape. With an automation framework, data professionals can meet these needs at a fraction of the cost of the traditional manual way. Governing metadata.
And each of these gains requires dataintegration across business lines and divisions. Limiting growth by (dataintegration) complexity Most operational IT systems in an enterprise have been developed to serve a single business function and they use the simplest possible model for this. We call this the Bad Data Tax.
Some examples include AWS data analytics services such as AWS Glue for dataintegration, Amazon QuickSight for business intelligence (BI), as well as third-party software and services from AWS Marketplace. We deploy a Lambda function data source connector to connect AWS with Google Cloud Provider.
With Amazon DataZone, individual business units can discover and directly consume these new data assets, gaining insights to a holistic view of the data (360-degree insights) across the organization. The Central IT team manages a unified Redshift data warehouse, handling all dataintegration, processing, and maintenance.
Ontotext’s GraphDB is an enterprise-ready semantic graph database (also called RDF triplestore as it stores data in RDF triples). It provides the core infrastructure for solutions where modeling agility, dataintegration, relationship exploration, cross-enterprise data publishing and consumption are critical.
AWS Transfer Family seamlessly integrates with other AWS services, automates transfer, and makes sure data is protected with encryption and access controls. Each file arrives as a pair with a tail metadata file in CSV format containing the size and name of the file. 2 GB into the landing zone daily.
As we’ve said again and again, we believe that knowledge graphs are the next generation tool for helping businesses make critical decisions, based on harmonized knowledge models and data derived from siloed source systems. But these tasks are only part of the story. That covers the two webinars that we wanted to present to you today.
Fast forward to today and curiosity cabinets have long been replaced by galleries, libraries, archives and museums (the set of institutions often referred to as GLAM). With knowledge graphs , additional facts and figures can be threaded into the collection items and the metadata related to them.
They wanted to develop a simple incremental data processing pipeline without having to update the entire database each time the pipeline ran. The Apache Hudi framework allowed the Infomedia team to maintain a golden reference dataset and capture changes so that the downstream database could be incrementally updated in a short timeframe.
Figure 1: Apache Iceberg fits the next generation data architecture by abstracting storage layer from analytics layer while introducing net new capabilities like time-travel and partition evolution. #1: Apache Iceberg enables seamless integration between different streaming and processing engines while maintaining dataintegrity between them.
Acting as a bridge between producer and consumer apps, it enforces the schema, reduces the data footprint in transit, and safeguards against malformed data. AWS Glue is an ideal solution for running stream consumer applications, discovering, extracting, transforming, loading, and integratingdata from multiple sources.
For more information about performance improvement capabilities, refer to the list of announcements below. Amazon Redshift ML large language model (LLM) integration Amazon Redshift ML enables customers to create, train, and deploy machine learning models using familiar SQL commands.
While this approach provides isolation, it creates another significant challenge: duplication of data, metadata, and security policies, or ‘split-brain’ data lake. Now the admins need to synchronize multiple copies of the data and metadata and ensure that users across the many clusters are not viewing stale information.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Then, you transform this data into a concise format.
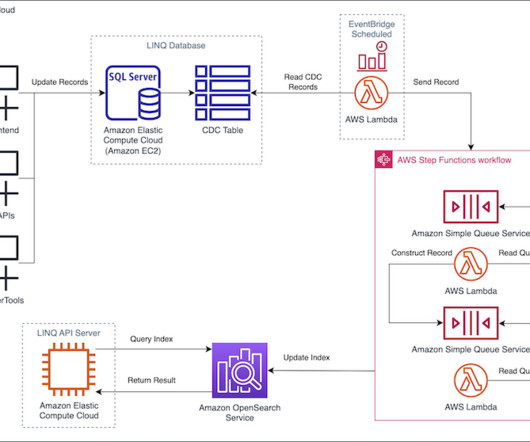
Following the best practices section of the OpenSearch Service Developer Guide, AVB selected an optimal cluster configuration with three dedicated cluster manager nodes and six data nodes, across three Availability Zones , while keeping shard size between 10–30 GiB. This approach allows updates to be executed independently and asynchronously.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content