This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A high hurdle many enterprises have yet to overcome is accessing mainframe data via the cloud. These tools dont have the necessary connectors, metadata relationships, or lineage mapping that spans both mainframe and cloud environments. This presents a lack of visibility in the metadata lineage spanning across mainframe and cloud data.
In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in data science and for managing data infrastructure. Humans are still needed to write software, but that software is of a different type. Developers of Software 1.0
Managing the lifecycle of AI data, from ingestion to processing to storage, requires sophisticated data management solutions that can manage the complexity and volume of unstructured data. As customers entrust us with their data, we see even more opportunities ahead to help them operationalize AI and high-performance workloads.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
For producers seeking collaboration with partners, AWS Clean Rooms facilitates secure collaboration and analysis of collective datasets without the need to share or duplicate underlying data. It provides data catalog, automated crawlers, and visual job creation to streamline dataintegration across various data sources and targets.
Today’s data modeling is not your father’s data modeling software. While it’s always been the best way to understand complex data sources and automate design standards and integrity rules, the role of data modeling continues to expand as the fulcrum of collaboration between data generators, stewards and consumers.
Developers will find themselves increasingly building software that has ML elements. Thus, many developers will need to curate data, train models, and analyze the results of models. With that said, we are still in a highly empirical era for ML: we need big data, big models, and big compute. and managed services in the cloud.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and dataintegrity.
These tools range from enterprise service bus (ESB) products, dataintegration tools; extract, transform and load (ETL) tools, procedural code, application program interfaces (APIs), file transfer protocol (FTP) processes, and even business intelligence (BI) reports that further aggregate and transform data.
And if it isnt changing, its likely not being used within our organizations, so why would we use stagnant data to facilitate our use of AI? The key is understanding not IF, but HOW, our data fluctuates, and data observability can help us do just that. Tackle AI data readiness and governance with erwin.
The program must introduce and support standardization of enterprise data. Programs must support proactive and reactive change management activities for reference data values and the structure/use of master data and metadata. Your data governance program needs to continually break down new siloes.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity.
Example 2: The Data Engineering Team Has Many Small, Valuable Files Where They Need Individual Source File Tracking In a typical data processing workflow, tracking individual files as they progress through various stages—from file delivery to data ingestion—is crucial.
Data fabric and data mesh are also both related to logical data management, which is the approach of providing virtualized access to data across an enterprise without the requirement to first extract and load it into a central repository.
As I recently noted , the term “data intelligence” has been used by multiple providers across analytics and data for several years and is becoming more widespread as software providers respond to the need to provide enterprises with a holistic view of data production and consumption.
Dataintegrity constraints: Many databases don’t allow for strange or unrealistic combinations of input variables and this could potentially thwart watermarking attacks. Applying dataintegrity constraints on live, incoming data streams could have the same benefits. Disparate impact analysis: see section 1.
For this, Cargotec built an Amazon Simple Storage Service (Amazon S3) data lake and cataloged the data assets in AWS Glue Data Catalog. They chose AWS Glue as their preferred dataintegration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed.
Collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics with Amazon Q Developer , the most capable generative AI assistant for software development, helping you along the way. Having confidence in your data is key.
IT teams need to capture metadata to know where their data comes from, allowing them to map out its lineage and flow. And since data does not exist in a vacuum, it’s critical not to treat data sets as lump sums. Often organizations struggle with data replication, synchronization, and performance.
2024 Gartner Market Guide To DataOps We at DataKitchen are thrilled to see the publication of the Gartner Market Guide to DataOps, a milestone in the evolution of this critical software category. At DataKitchen, we think of this is a ‘meta-orchestration’ of the code and tools acting upon the data.
This first article emphasizes data as the ‘foundation-stone’ of AI-based initiatives. Establishing a Data Foundation. The shift away from ‘Software 1.0’ where applications have been based on hard-coded rules has begun and the ‘Software 2.0’ era is upon us. Addressing the Challenge.
Prashant Parikh, erwin’s Senior Vice President of Software Engineering, talks about erwin’s vision to automate every aspect of the data governance journey to increase speed to insights. Data Cataloging: Catalog and sync metadata with data management and governance artifacts according to business requirements in real time.
The role of data modeling (DM) has expanded to support enterprise data management, including data governance and intelligence efforts. Metadata management is the key to managing and governing your data and drawing intelligence from it. Types of Data Models: Conceptual, Logical and Physical.
KGs bring the Semantic Web paradigm to the enterprises, by introducing semantic metadata to drive data management and content management to new levels of efficiency and breaking silos to let them synergize with various forms of knowledge management. The RDF data model and the other standards in W3C’s Semantic Web stack (e.g.,
Apache Iceberg offers integrations with popular data processing frameworks such as Apache Spark, Apache Flink, Apache Hive, Presto, and more. AWS provides integrations for various AWS services with Iceberg tables as well, including AWS Glue Data Catalog for tracking table metadata.
After navigating the complexity of multiple systems and stages to bring data to its end-use case, the final product’s value becomes the ultimate yardstick for measuring success. By diligently testing and monitoring data in Use, you uphold dataintegrity and provide tangible value to end-users. Contact Us Today!
When evolving such a partition definition, the data in the table prior to the change is unaffected, as is its metadata. Only data that is written to the table after the evolution is partitioned with the new definition, and the metadata for this new set of data is kept separately. SparkActions.get().expireSnapshots(iceTable).expireOlderThan(TimeUnit.DAYS.toMillis(7)).execute()
“SAP is executing on a roadmap that brings an important semantic layer to enterprise data, and creates the critical foundation for implementing AI-based use cases,” said analyst Robert Parker, SVP of industry, software, and services research at IDC. In the SuccessFactors application, Joule will behave like an HR assistant.
Data visualization is a concept that describes any effort to help people understand the significance of data by placing it in a visual context. Patterns, trends and correlations that may go unnoticed in text-based data can be more easily exposed and recognized with data visualization software.
Each of that component has its own purpose that we will discuss in more detail while concentrating on data warehousing. A solid BI architecture framework consists of: Collection of data. Dataintegration. Storage of data. Data analysis. Distribution of data. Dataintegration.
If your organization has any kind of data and analytics initiative, then chances are you have people – maybe even an entire department dedicated to managing and integratingdata for (and between) software applications to achieve some sort of business outcome. Is a Power-User or a Data Scientist an Information Steward?
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Many are focused on delivering the best returns for marketing teams but some are more general tools that can handle any data science task. Analytics, Data Management, Marketing Software
‘Data Fabric’ has reached where ‘Cloud Computing’ and ‘Grid Computing’ once trod. Data Fabric hit the Gartner top ten in 2019. The purpose of weaving a Data Fabric is to remove the friction and cost from accessing and sharing data in the distributed ICT environment that is the norm.
Many AWS customers adopted Apache Hudi on their data lakes built on top of Amazon S3 using AWS Glue , a serverless dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources for analytics, machine learning (ML), and application development.
This is done by mining complex data using BI software and tools , comparing data to competitors and industry trends, and creating visualizations that communicate findings to others in the organization. Real-time problem-solving exercises using Excel or other BI tools. More on BI: What is business intelligence?
The construction of big data applications based on open source software has become increasingly uncomplicated since the advent of projects like Data on EKS , an open source project from AWS to provide blueprints for building data and machine learning (ML) applications on Amazon Elastic Kubernetes Service (Amazon EKS).
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data discoverability Unlike structured data, which is managed in well-defined rows and columns, unstructured data is stored as objects.
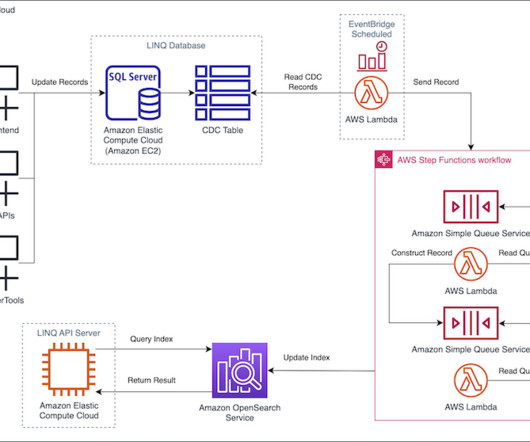
Following the best practices section of the OpenSearch Service Developer Guide, AVB selected an optimal cluster configuration with three dedicated cluster manager nodes and six data nodes, across three Availability Zones , while keeping shard size between 10–30 GiB. The following figure outlines the solution.
You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. With these insights, teams have the visibility to make dataintegration pipelines more efficient. An AWS Glue crawler scans data on the S3 bucket and populates table metadata on the AWS Glue Data Catalog.
Google acquires Looker – June 2019 (infrastructure/search/data broker vendor acquires analytics/BI). Salesforce closes acquisition of Mulesoft – May 2018 (business app vendor acquires dataintegration). Even the vast spend on software in D&A is centered on aspects of the two parts.
If you do a general internet search for data catalogs, all sorts of possibilities emerge. If you look closely, and ask a lot of questions, you will find that some of these products are not actually fully functional data catalogs at all. Some software products start out life-solving a specific use case related to data, […].
AWS Glue, with its ability to process data using Apache Spark and connect to various data sources, is a suitable solution for addressing the challenges of accessing data across multiple cloud environments. Navigate to the AWS Marketplace page for the Azure Data Lake Storage Connector for AWS Glue.
Poor data management, data silos, and a lack of a common understanding across systems and/or teams are the root cause that prohibits an organization from scaling the business in a dynamic environment. As a result, organizations have spent untold money and time gathering and integratingdata.
Aruba offers networking hardware like access points, switches, routers, software, security devices, and Internet of Things (IoT) products. AWS Transfer Family seamlessly integrates with other AWS services, automates transfer, and makes sure data is protected with encryption and access controls. 2 GB into the landing zone daily.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content