This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
In order to figure out why the numbers in the two reports didn’t match, Steve needed to understand everything about the data that made up those reports – when the report was created, who created it, any changes made to it, which system it was created in, etc. Enterprise data governance. Metadata in data governance.
An extract, transform, and load (ETL) process using AWS Glue is triggered once a day to extract the required data and transform it into the required format and quality, following the data product principle of data mesh architectures. From here, the metadata is published to Amazon DataZone by using AWS Glue Data Catalog.
We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producers data is being updated. Industry-leading price-performance: Amazon Redshift launches RA3.large
If you suddenly see unexpected patterns in your social data, that may mean adversaries are attempting to poison your data sources. Anomaly detection may have originated in finance, but it is becoming a part of every data scientist’s toolkit. Tim Kraska on “How machine learning will accelerate data management systems”.
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. The program must introduce and support standardization of enterprise data.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data discoverability Unlike structureddata, which is managed in well-defined rows and columns, unstructured data is stored as objects.
KGs bring the Semantic Web paradigm to the enterprises, by introducing semantic metadata to drive data management and content management to new levels of efficiency and breaking silos to let them synergize with various forms of knowledge management. The RDF data model and the other standards in W3C’s Semantic Web stack (e.g.,
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. With AWS Glue 5.0, With AWS Glue 5.0,
And each of these gains requires dataintegration across business lines and divisions. Limiting growth by (dataintegration) complexity Most operational IT systems in an enterprise have been developed to serve a single business function and they use the simplest possible model for this. We call this the Bad Data Tax.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic.
Let’s explore the continued relevance of data modeling and its journey through history, challenges faced, adaptations made, and its pivotal role in the new age of data platforms, AI, and democratized data access. Embracing the future In the dynamic world of data, data modeling remains an indispensable tool.
Added to this is the increasing demands being made on our data from event-driven and real-time requirements, the rise of business-led use and understanding of data, and the move toward automation of dataintegration, data and service-level management. Knowledge Graphs are the Warp and Weft of a Data Fabric.
It won’t protect you from issues of data quality or from service failures. […] But Linked Data does provide you with new ways to manage these existing data-management challenges. 6 Linked Data, StructuredData on the Web. Linked Data and Information Retrieval.
That means removing errors, filling in missing information and harmonizing the various data sources so that there is consistency. Once that is done, data can be transformed and enriched with metadata to facilitate analysis. Knowledge graphs help with data analysis in a number of ways.
It won’t protect you from issues of data quality or from service failures. […] But Linked Data does provide you with new ways to manage these existing data-management challenges. 6 Linked Data, StructuredData on the Web. Linked Data and Information Retrieval.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. The Central IT team manages a unified Redshift data warehouse, handling all dataintegration, processing, and maintenance.
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Then, you transform this data into a concise format.
Knowledge graphs have greatly helped to successfully enhance business-critical enterprise applications, especially those where high performance tagging and agile dataintegration is needed. Enterprises generate an enormous amount of data and content every minute. How can you build knowledge graphs for enterprise applications?
A data catalog is a central hub for XAI and understanding data and related models. While “operational exhaust” arrived primarily as structureddata, today’s corpus of data can include so-called unstructured data. These methods and their results need to be captured, but how? Other Technologies. Conclusion.
An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 data lake hourly with incremental data. The AWS Glue job can transform the raw data in Amazon S3 to Parquet format, which is optimized for analytic queries. All the metadata of the tables is stored in the AWS Glue Data Catalog, including the Hudi tables.
Instead of relying on one-off scripts or unstructured transformation logic, dbt Core structures transformations as models, linking them through a Directed Acyclic Graph (DAG) that automatically handles dependencies. Data freshness propagation: No automatic tracking of data propagation delays across multiplemodels.
From a technological perspective, RED combines a sophisticated knowledge graph with large language models (LLM) for improved natural language processing (NLP), dataintegration, search and information discovery, built on top of the metaphactory platform.
The solution combines Cloudera Enterprise , the scalable distributed platform for big data, machine learning, and analytics, with riskCanvas , the financial crime software suite from Booz Allen Hamilton. It supports a variety of storage engines that can handle raw files, structureddata (tables), and unstructured data.
Specifically, the increasing amount of data being generated and collected, and the need to make sense of it, and its use in artificial intelligence and machine learning, which can benefit from the structureddata and context provided by knowledge graphs. We get this question regularly. million users.
Knowledge graphs, while not as well-known as other data management offerings, are a proven dynamic and scalable solution for addressing enterprise data management requirements across several verticals. This often leaves business insights and opportunities lost among a tangled complexity of meaningless, siloed data and content.
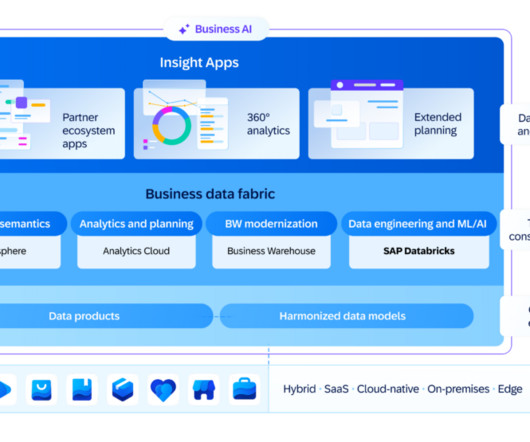
Instead, SAP is focusing on its core strength leveraging its deep understanding of business processes to transform the resulting data and metadata into valuable D&A insights. Instead, the Databricks object store provides an industry-standard and more cost-efficient solution for storing data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content