This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Managing the lifecycle of AI data, from ingestion to processing to storage, requires sophisticated data management solutions that can manage the complexity and volume of unstructureddata. As the leader in unstructureddata storage, customers trust NetApp with their most valuable data assets.
In the era of big data, data lakes have emerged as a cornerstone for storing vast amounts of raw data in its native format. They support structured, semi-structured, and unstructureddata, offering a flexible and scalable environment for data ingestion from multiple sources.
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
If you’re a mystery lover, I’m sure you’ve read that classic tale: Sherlock Holmes and the Case of the Deceptive Data, and you know how a metadata catalog was a key plot element. In The Case of the Deceptive Data, Holmes is approached by B.I. He goes on to explain: Reasons for inaccurate data. Big data is BIG.
They also face increasing regulatory pressure because of global data regulations , such as the European Union’s General Data Protection Regulation (GDPR) and the new California Consumer Privacy Act (CCPA), that went into effect last week on Jan. So here’s why data modeling is so critical to data governance.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprises core has never been more significant.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data governance is a critical building block across all these approaches, and we see two emerging areas of focus.
S3 Tables integration with the AWS Glue Data Catalog is in preview, allowing you to stream, query, and visualize dataincluding Amazon S3 Metadata tablesusing AWS analytics services such as Amazon Data Firehose , Amazon Athena , Amazon Redshift, Amazon EMR, and Amazon QuickSight. With AWS Glue 5.0, With AWS Glue 5.0,
Data modeling is a process that enables organizations to discover, design, visualize, standardize and deploy high-quality data assets through an intuitive, graphical interface. Data models provide visualization, create additional metadata and standardize data design across the enterprise. SQL or NoSQL?
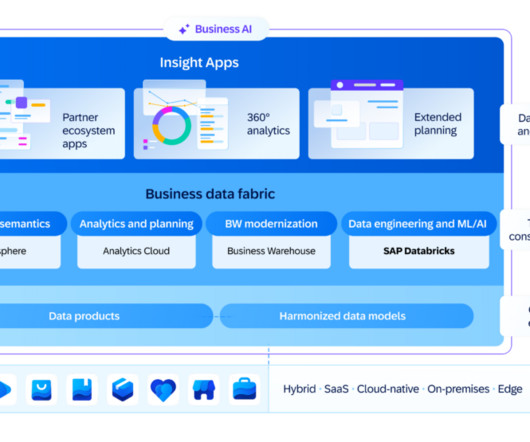
“SAP is executing on a roadmap that brings an important semantic layer to enterprise data, and creates the critical foundation for implementing AI-based use cases,” said analyst Robert Parker, SVP of industry, software, and services research at IDC. We are also seeing customers bringing in other data assets from other apps or data sources.
A data lake is a centralized repository that you can use to store all your structured and unstructureddata at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. target_iceberg_add_files/metadata/.
There is no disputing the fact that the collection and analysis of massive amounts of unstructureddata has been a huge breakthrough. We would like to talk about data visualization and its role in the big data movement. Does Data Virtualization support web dataintegration?
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Data and Metadata: Data inputs and data outputs produced based on the application logic.
That means removing errors, filling in missing information and harmonizing the various data sources so that there is consistency. Once that is done, data can be transformed and enriched with metadata to facilitate analysis. Knowledge graphs help with data analysis in a number of ways.
Loading complex multi-point datasets into a dimensional model, identifying issues, and validating dataintegrity of the aggregated and merged data points are the biggest challenges that clinical quality management systems face. Build a data vault schema for the raw vault and create materialized views for the business vault.
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic dataintegration , and ontology building.
Some examples include AWS data analytics services such as AWS Glue for dataintegration, Amazon QuickSight for business intelligence (BI), as well as third-party software and services from AWS Marketplace. We create an S3 bucket to store data that exceeds the Lambda function’s response size limits.
We offer two different PowerPacks – Agile DataIntegration and High-Performance Tagging. The High-Performance Tagging PowerPack bundle The High-Performance Tagging PowerPack is designed to satisfy taxonomy and metadata management needs by allowing enterprise tagging at a scale.
At the same time, there are more demands for data to be used in real-time and for businesses to have a better understanding of it. In addition, there is a growing trend of automating dataintegration and management processes. All this makes it difficult to navigate the enterprise data landscape and stay ahead of the competition.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. .
Instead, it creates a unified way, sometimes called a data fabric, of accessing an organization’s data as well as 3rd party or global data in a seamless manner. Data is represented in a holistic, human-friendly and meaningful way. For efficient drug discovery, linked data is key.
Instead of relying on one-off scripts or unstructured transformation logic, dbt Core structures transformations as models, linking them through a Directed Acyclic Graph (DAG) that automatically handles dependencies. Data freshness propagation: No automatic tracking of data propagation delays across multiplemodels.
To overcome these issues, Orca decided to build a data lake. A data lake is a centralized data repository that enables organizations to store and manage large volumes of structured and unstructureddata, eliminating data silos and facilitating advanced analytics and ML on the entire data.
Both approaches were typically monolithic and centralized architectures organized around mechanical functions of data ingestion, processing, cleansing, aggregation, and serving. Monitor and identify data quality issues closer to the source to mitigate the potential impact on downstream processes or workloads.
A data catalog is a central hub for XAI and understanding data and related models. While “operational exhaust” arrived primarily as structured data, today’s corpus of data can include so-called unstructureddata. Other Technologies. Conclusion.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, data lakes, data warehouses and SQL databases, providing a holistic view into business performance. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
From a technological perspective, RED combines a sophisticated knowledge graph with large language models (LLM) for improved natural language processing (NLP), dataintegration, search and information discovery, built on top of the metaphactory platform. Let’s have a quick look under the bonnet.
It supports a variety of storage engines that can handle raw files, structured data (tables), and unstructureddata. It also supports a number of frameworks that can process data in parallel, in batch or in streams, in a variety of languages. The foundation of this end-to-end AML solution is Cloudera Enterprise.
An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 data lake hourly with incremental data. The AWS Glue job can transform the raw data in Amazon S3 to Parquet format, which is optimized for analytic queries. All the metadata of the tables is stored in the AWS Glue Data Catalog, including the Hudi tables.
Let’s discuss what data classification is, the processes for classifying data, data types, and the steps to follow for data classification: What is Data Classification? Either completed manually or using automation, the data classification process is based on the data’s context, content, and user discretion.
In the upcoming years, augmented data management solutions will drive efficiency and accuracy across multiple domains, from data cataloguing to anomaly detection. AI-driven platforms process vast datasets to identify patterns, automating tasks like metadata tagging, schema creation and data lineage mapping.
These tools fall into four categories: Data (Warehouse) Automation Tools simplify and automate schema creation and pipeline management, making them ideal for rapid deployment of entire data warehouses. DataIntegration Specialists focus on connectivity and transformation logic, enabling robust data pipelines.
Instead, SAP is focusing on its core strength leveraging its deep understanding of business processes to transform the resulting data and metadata into valuable D&A insights. Instead, the Databricks object store provides an industry-standard and more cost-efficient solution for storing data.
This configuration allows you to augment your sensitive on-premises data with cloud data while making sure all data processing and compute runs on-premises in AWS Outposts Racks. Additionally, Oktank must comply with data residency requirements, making sure that confidential data is stored and processed strictly on premises.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content