This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
In this blog post, we’ll discuss how the metadata layer of Apache Iceberg can be used to make data lakes more efficient. You will learn about an open-source solution that can collect important metrics from the Iceberg metadata layer. This ensures that each change is tracked and reversible, enhancing data governance and auditability.
Our previous solution offered visualization of key metrics, but point-in-time snapshots produced only in PDF format. In this post, we discuss how we built a solution using QuickSight that delivers real-time visibility of key metrics to public sector recruiters.
Since Apache Iceberg is well supported by AWS data services and Cloudinary was already using Spark on Amazon EMR, they could integrate writing to Data Catalog and start an additional Spark cluster to handle data maintenance and compaction. For example, for certain queries, Athena runtime was 2x–4x faster than Snowflake.
Some will argue that observability is nothing more than testing and monitoring applications using tests, metrics, logs, and other artifacts. That’s a fair point, and it places emphasis on what is most important – what best practices should data teams employ to apply observability to data analytics. Location Balance Tests.
The dbt-glue adapter democratized access for dbt users to data lakes, and enabled many users to effortlessly run their transformation workloads on the cloud with the serverless dataintegration capability of AWS Glue. The gold model joins the technical logs with billing data and organizes the metrics per business unit.
Using Apache Iceberg’s compaction results in significant performance improvements, especially for large tables, making a noticeable difference in query performance between compacted and uncompacted data. These files are then reconciled with the remaining data during read time.
Check the disk.avail metric for hot storage tier nodes to validate your available disk space. Use the reindex API operation The _reindex operation snapshots the index at the beginning of its run and performs processing on a snapshot to minimize impact on the source index. v The following screenshot shows the output.
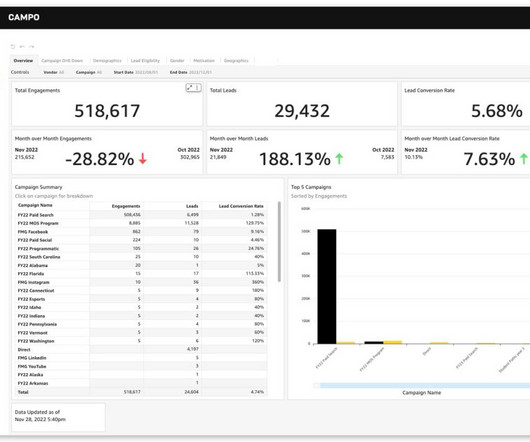
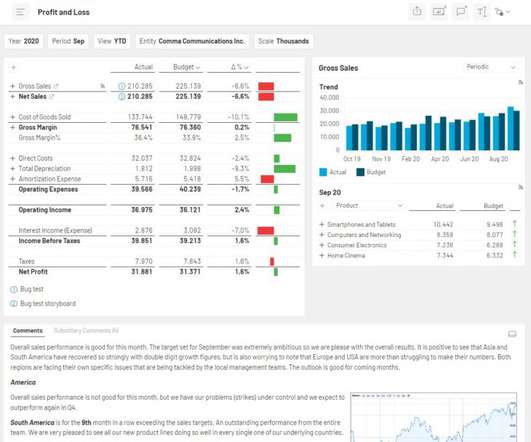
Financial Performance Dashboard The financial performance dashboard provides a comprehensive overview of key metrics related to your balance sheet, shedding light on the efficiency of your capital expenditure. While sales dashboards focus on future prospects, accounting primarily focuses on analyzing the same metrics retrospectively.
Key Performance Indicators (KPIs) serve as vital metrics that help measure progress towards business goals. To effectively monitor and analyze these metrics, businesses utilize KPI reports. Furthermore, additional metrics such as sales performance can be incorporated for customization.
On one hand, BI analytic tools can provide a quick, easy-to-understand visual snapshot of what appears to be the bottom line. Currently, BI analytic tools are crippling corporations because Finance is caught between the need to get real-time data from the ERP (and relying on IT to do so) and the need for the C-suite to get compelling visuals.
The data (business process) needs to be integrated across various departments, in this case, marketing can access the sales data. Identifying the correct business process is critical—getting this step wrong can impact the entire data mart (it can cause the grain to be duplicated and incorrect metrics on the final reports).
AWS Glue for ETL To meet customer demand while supporting the scale of new businesses’ data sources, it was critical for us to have a high degree of agility, scalability, and responsiveness in querying various data sources. Every dataset in our system is uniquely identified by snapshot ID, which we can search from our metadata store.
It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release 7 times fewer defects. Finally, dataintegrity is of paramount importance.
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into data validation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
Managers can obtain an up-to-date snapshot of the project’s scope, time, cost, and quality parameters. What specific metrics or aspects of performance do you want to assess? Gather Relevant Data : Collect accurate and relevant data from reliable sources. Here is a step-by-step guide.
A data anomaly is revealed when there is a dataset deviation or irregularity – something that is out of the bounds of expected patterns and behaviors. It is hard to overstate the criticality of anomaly detection.
In these scenarios, customers looking for a serverless dataintegration offering use AWS Glue as a core component for processing and cataloging data. A common use case with this data would be to gather usage metrics on principals acting on your account’s resources for auditing and regulatory needs.
Enterprise Performance Management (EPM) provides users throughout your company with vivid, up-to-the-minute details about the key metrics that drive your organization’s success. This creates an opportunity-cost when decision makers have to wait for the reports they’ll be using to track performance metrics. Step 6: Drill Into the Data.
All of that in-between work–the export, the consolidation, and the cleanup–means that analysts are stuck using a snapshot of the data. Executives need to know how the organization is performing relative to key metrics, and how certain external factors may impact revenue product demand, profitability, supply chain performance, and more.
You’ll learn how leading finance teams apply technology to the task of producing fast, accurate reports, eliminating tedious manual effort, giving managers visibility to real-time organizational metrics, and instilling confidence in stakeholders throughout the company. Challenge 1. ERP Complexity.
On the other hand, DataOps Observability refers to understanding the state and behavior of data as it flows through systems. It allows organizations to see how data is being used, where it is coming from, and how it is being transformed. Data lineage is static and often lags by weeks or months.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content