This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Large language models (LLMs) just keep getting better. In just about two years since OpenAI jolted the news cycle with the introduction of ChatGPT, weve already seen the launch and subsequent upgrades of dozens of competing models. million on inference, grounding, and dataintegration for just proof-of-concept AI projects.
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learning models from malicious actors. Like many others, I’ve known for some time that machine learning models themselves could pose security risks. This is like a denial-of-service (DOS) attack on your model itself.
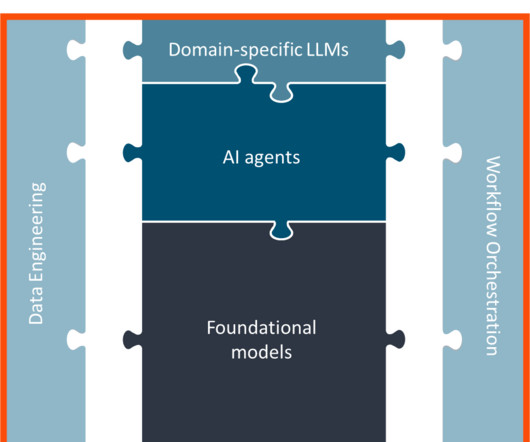
Introduction Large language models (LLMs) have revolutionized natural language processing (NLP), enabling various applications, from conversational assistants to content generation and analysis. However, working with LLMs can be challenging, requiring developers to navigate complex prompting, dataintegration, and memory management tasks.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
Speaker: Dave Mariani, Co-founder & Chief Technology Officer, AtScale; Bob Kelly, Director of Education and Enablement, AtScale
Workshop video modules include: Breaking down data silos. Integratingdata from third-party sources. Developing a data-sharing culture. Combining dataintegration styles. Translating DevOps principles into your data engineering process. Using datamodels to create a single source of truth.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
The dataintegration landscape is under a constant metamorphosis. In the current disruptive times, businesses depend heavily on information in real-time and data analysis techniques to make better business decisions, raising the bar for dataintegration. Why is DataIntegration a Challenge for Enterprises?
Citizens expect efficient services, The post Empowering the Public Sector with Data: A New Model for a Modern Age appeared first on Data Management Blog - DataIntegration and Modern Data Management Articles, Analysis and Information. In this dynamic environment, time is everything.
Data architecture definition Data architecture describes the structure of an organizations logical and physical data assets, and data management resources, according to The Open Group Architecture Framework (TOGAF). An organizations data architecture is the purview of data architects. Curate the data.
What is DataModeling? Datamodeling is a process that enables organizations to discover, design, visualize, standardize and deploy high-quality data assets through an intuitive, graphical interface. Datamodels provide visualization, create additional metadata and standardize data design across the enterprise.
Machine learning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. The problem is even more magnified in the case of structured enterprise data.
How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising dataintegrity and compliance? While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business.
Then there’s unstructured data with no contextual framework to govern data flows across the enterprise not to mention time-consuming manual data preparation and limited views of data lineage. Today’s datamodeling is not your father’s datamodeling software.
This article was published as a part of the Data Science Blogathon. Introduction to ETL ETL is a type of three-step dataintegration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build Big Data.
The core of their problem is applying AI technology to the data they already have, whether in the cloud, on their premises, or more likely both. Imagine that you’re a data engineer. The data is spread out across your different storage systems, and you don’t know what is where. What does the next generation of AI workloads need?
“The challenge that a lot of our customers have is that requires you to copy that data, store it in Salesforce; you have to create a place to store it; you have to create an object or field in which to store it; and then you have to maintain that pipeline of data synchronization and make sure that data is updated,” Carlson said.
Reading Time: 2 minutes When making decisions that are critical to national security, governments rely on data, and those that leverage the cutting edge technology of generative AI foundation models will have a distinct advantage over their adversaries. Pros and Cons of generative AI.
In this post, I’ll describe some of the key areas of interest and concern highlighted by respondents from Europe, while describing how some of these topics will be covered at the upcoming Strata Data conference in London (April 29 - May 2, 2019). Data Platforms. DataIntegration and Data Pipelines.
We actually started our AI journey using agents almost right out of the gate, says Gary Kotovets, chief data and analytics officer at Dun & Bradstreet. The problem is that, before AI agents can be integrated into a companys infrastructure, that infrastructure must be brought up to modern standards. Thats what Cisco is doing.
Data professionals need to access and work with this information for businesses to run efficiently, and to make strategic forecasting decisions through AI-powered datamodels. Without integrating mainframe data, it is likely that AI models and analytics initiatives will have blind spots.
So from the start, we have a dataintegration problem compounded with a compliance problem. An AI project that doesn’t address dataintegration and governance (including compliance) is bound to fail, regardless of how good your AI technology might be. Data needs to become the means, a tool for making good decisions.
Bigeye’s anomaly detection capabilities rely on the automated generation of data quality thresholds based on machine learning (ML) models fueled by historical data. The company also offers associated alerts delivered to data owners and data consumers, and reinforcement learning to adapt notifications based on user feedback.
These strategies, such as investing in AI-powered cleansing tools and adopting federated governance models, not only address the current data quality challenges but also pave the way for improved decision-making, operational efficiency and customer satisfaction. When financial data is inconsistent, reporting becomes unreliable.
Companies successfully adopt machine learning either by building on existing data products and services, or by modernizing existing models and algorithms. In this post, I share slides and notes from a keynote I gave at the Strata Data Conference in London earlier this year. A typical data pipeline for machine learning.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. Meta-Orchestration .
Considerations for a world where ML models are becoming mission critical. In this post, I share slides and notes from a keynote I gave at the Strata Data Conference in New York last September. As the data community begins to deploy more machine learning (ML) models, I wanted to review some important considerations.
In addition to real-time analytics and visualization, the data needs to be shared for long-term data analytics and machine learning applications. To achieve this, EUROGATE designed an architecture that uses Amazon DataZone to publish specific digital twin data sets, enabling access to them with SageMaker in a separate AWS account.
We need to do more than automate model building with autoML; we need to automate tasks at every stage of the data pipeline. In a previous post , we talked about applications of machine learning (ML) to software development, which included a tour through sample tools in data science and for managing data infrastructure.
The challenge is that these architectures are convoluted, requiring diverse and multiple models, sophisticated retrieval-augmented generation stacks, advanced data architectures, and niche expertise,” they said. They predicted more mature firms will seek help from AI service providers and systems integrators.
Q: Is datamodeling cool again? In today’s fast-paced digital landscape, data reigns supreme. The data-driven enterprise relies on accurate, accessible, and actionable information to make strategic decisions and drive innovation. A: It always was and is getting cooler!!
AWS Glue provides different authoring experiences for you to build dataintegration jobs. Data scientists tend to run queries interactively and retrieve results immediately to author dataintegration jobs. This interactive experience can accelerate building dataintegration pipelines.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
ChatGPT is capable of doing many of these tasks, but the custom support chatbot is using another model called text-embedding-ada-002, another generative AI model from OpenAI, specifically designed to work with embeddings—a type of database specifically designed to feed data into large language models (LLM).
From within the unified studio, you can discover data and AI assets from across your organization, then work together in projects to securely build and share analytics and AI artifacts, including data, models, and generative AI applications.
They’re taking data they’ve historically used for analytics or business reporting and putting it to work in machine learning (ML) models and AI-powered applications. Amazon SageMaker Unified Studio (Preview) solves this challenge by providing an integrated authoring experience to use all your data and tools for analytics and AI.
The development of business intelligence to analyze and extract value from the countless sources of data that we gather at a high scale, brought alongside a bunch of errors and low-quality reports: the disparity of data sources and data types added some more complexity to the dataintegration process.
Chris will overview data at rest and in use, with Eric returning to demonstrate the practical steps in data testing for both states. Session 3: Mastering Data Testing in Development and Migration During our third session, the focus will shift towards regression and impact assessment in development cycles. Reserve Your Spot!
You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model. Amazon Redshift provides built-in features to accelerate the process of modeling, orchestrating, and reporting from a dimensional model. Declare the grain of your data.
The post Bridging the Gap: Democratizing Data for Traditional Users and GenAI Models appeared first on Data Management Blog - DataIntegration and Modern Data Management Articles, Analysis and Information.
When dealing with third-party data sources, AWS Data Exchange simplifies the discovery, subscription, and utilization of third-party data from a diverse range of producers or providers. As a producer, you can also monetize your data through the subscription model using AWS Data Exchange.
Simplified data corrections and updates Iceberg enhances data management for quants in capital markets through its robust insert, delete, and update capabilities. These features allow efficient data corrections, gap-filling in time series, and historical data updates without disrupting ongoing analyses or compromising dataintegrity.
Reading Time: 6 minutes The emergence of Large Language Models (LLMs) and Generative AI marks a significant leap in technology, promising to deliver transformational automation and innovation across diverse industries and use cases. Having said that, as everyone races to develop next generation AI.
Foundational data technologies. Machine learning and AI require data—specifically, labeled data for training models. Data lineage, data catalog, and data governance solutions can increase usage of data systems by enhancing trustworthiness of data. Data Platforms.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content