This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
This is also a good opportunity to build a data lineage capability if it doesnt already exist. Should the company make changes to improve data flows and infrastructure, there will be additional opportunities to optimize the data footprint.
Though loosely applied, agentic AI generally refers to granting AI agents more autonomy to optimize tasks and chain together increasingly complex actions. Agentic AI can make sales more effective by handling lead scoring, assisting with customer segmentation, and optimizing targeted outreach, he says.
The growing volume of data is a concern, as 20% of enterprises surveyed by IDG are drawing from 1000 or more sources to feed their analytics systems. Dataintegration needs an overhaul, which can only be achieved by considering the following gaps. Heterogeneous sources produce data sets of different formats and structures.
Invest in core functions that perform data curation such as modeling important relationships, cleansing raw data, and curating key dimensions and measures. Optimizedata flows for agility. Limit the times data must be moved to reduce cost, increase data freshness, and optimize enterprise agility.
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. One of the most common questions we get from customers is how to effectively monitor and optimize costs on AWS Glue for Spark.
Applying customization techniques like prompt engineering, retrieval augmented generation (RAG), and fine-tuning to LLMs involves massive data processing and engineering costs that can quickly spiral out of control depending on the level of specialization needed for a specific task. to autonomously address lost card calls.
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability.
In addition to various deployment options, Oracle offers several database services, including Oracle Exadata optimized infrastructure, Oracle Autonomous Database, Oracle Autonomous Data Warehouse and Heatwave MySQL service. Exadata is Oracles engineered system for data and now artificial intelligence (AI) operations.
It’s also a critical trait for the data assets of your dreams. What is data with integrity? Dataintegrity is the extent to which you can rely on a given set of data for use in decision-making. Where can dataintegrity fall short? Too much or too little access to data systems.
Some challenges include data infrastructure that allows scaling and optimizing for AI; data management to inform AI workflows where data lives and how it can be used; and associated data services that help data scientists protect AI workflows and keep their models clean. Seamless dataintegration.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Unlike direct Amazon S3 access, Iceberg supports these operations on petabyte-scale data lakes without requiring complex custom code.
This brief explains how data virtualization, an advanced dataintegration and data management approach, enables unprecedented control over security and governance. In addition, data virtualization enables companies to access data in real time while optimizing costs and ROI.
Parameters can also help connect one dashboard to another, allowing a dashboard user to drill down into data that’s in a different analysis. With dataset parameters, authors can optimize the experience and load time of dashboards that are connected live to external SQL-based sources. With dataset parameters!
First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimaldata layout recommendations for distribution and sort keys, further optimizing performance.
Data is typically organized into project-specific schemas optimized for business intelligence (BI) applications, advanced analytics, and machine learning. After all, having a customer uncover a data error is always embarrassing and potentially damaging, so rigorous quality assurance within the Medallion architecture is critical.
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. While real-time data is processed by other applications, this setup maintains high-performance analytics without the expense of continuous processing.
Machine learning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Dataintegration and cleaning. Data programming.
So from the start, we have a dataintegration problem compounded with a compliance problem. An AI project that doesn’t address dataintegration and governance (including compliance) is bound to fail, regardless of how good your AI technology might be. Some of these tasks have been automated, but many aren’t.
The only question is, how do you ensure effective ways of breaking down data silos and bringing data together for self-service access? It starts by modernizing your dataintegration capabilities – ensuring disparate data sources and cloud environments can come together to deliver data in real time and fuel AI initiatives.
RightData – A self-service suite of applications that help you achieve Data Quality Assurance, DataIntegrity Audit and Continuous Data Quality Control with automated validation and reconciliation capabilities. QuerySurge – Continuously detect data issues in your delivery pipelines. Data breaks.
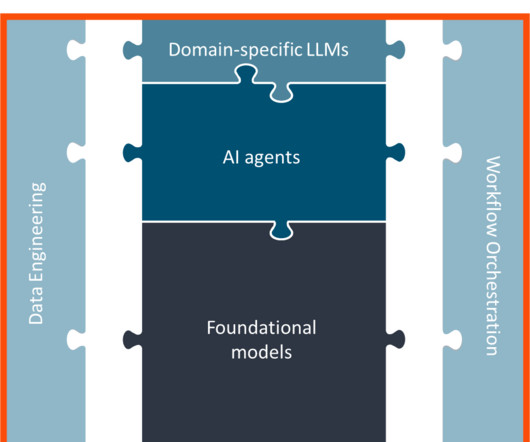
Unique DataIntegration and Experimentation Capabilities: Enable users to bridge the gap between choosing from and experimenting with several data sources and testing multiple AI foundational models, enabling quicker iterations and more effective testing.
Companies implementing task orchestration tools can quickly generate new ideas and optimize existing processes to drive significant innovation. Integrating with various data sources is crucial for enhancing the capabilities of automation platforms , allowing enterprises to derive actionable insights from all available datasets.
At the recent Strata Data conference we had a series of talks on relevant cultural, organizational, and engineering topics. Here's a list of a few clusters of relevant sessions from the recent conference: DataIntegration and Data Pipelines. Data Platforms. Model lifecycle management. Culture and organization.
In Figure 1, the nodes could be sources of data, storage, internal/external applications, users – anything that accesses or relates to data. Data fabrics provide reusable services that span dataintegration, access, transformation, modeling, visualization, governance, and delivery.
Forrester said gen AI will affect process design, development, and dataintegration, thereby reducing design and development time and the need for desktop and mobile interfaces. Forrester predicts that vague business objectives and premature integration in decision-making will create confusion when it comes to leveraging AI agents.
AWS Transfer Family seamlessly integrates with other AWS services, automates transfer, and makes sure data is protected with encryption and access controls. Conclusion In this post, we showed you how HPE Aruba Supply Chain successfully re-architected and deployed their data solution by adopting a modern data architecture on AWS.
Improved decision-making: Making decisions based on data instead of human intuition can be defined as the core benefit of BI software. By optimizing every single department and area of your business with powerful insights extracted from your own data you will ensure your business succeeds in the long run. click to enlarge**.
Likes, comments, shares, reach, CTR, conversions – all have become extremely significant to optimize and manage regularly in order to grow in our competitive digital environment. You need to know how the audience responds, whether you need further adjustments, and how to gather accurate, real-time data. With more than 2.70
How will organizations wield AI to seize greater opportunities, engage employees, and drive secure access without compromising dataintegrity and compliance? While it may sound simplistic, the first step towards managing high-quality data and right-sizing AI is defining the GenAI use cases for your business.
Important considerations for preview As you begin using automated Spark upgrades during the preview period, there are several important aspects to consider for optimal usage of the service: Service scope and limitations – The preview release focuses on PySpark code upgrades from AWS Glue versions 2.0 to version 4.0.
The development of business intelligence to analyze and extract value from the countless sources of data that we gather at a high scale, brought alongside a bunch of errors and low-quality reports: the disparity of data sources and data types added some more complexity to the dataintegration process.
Recognizing and rewarding data-centric achievements reinforces the value placed on analytical ability. Establishing clear accountability ensures dataintegrity. Implementing Service Level Agreements (SLAs) for data quality and availability sets measurable standards, promoting responsibility and trust in data assets.
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG dataintegrity and fostering collaboration with sustainability teams.
Leveraging the advanced tools of the Vertex AI platform, Gemini models, and BigQuery, organizations can harness AI-driven insights and real-time data analysis, all within the trusted Google Cloud ecosystem. We believe an actionable business strategy begins and ends with accessible data.
Not surprisingly, dataintegration and ETL were among the top responses, with 60% currently building or evaluating solutions in this area. In an age of data-hungry algorithms, everything really begins with collecting and aggregating data. and managed services in the cloud.
Here, I’ll highlight the where and why of these important “dataintegration points” that are key determinants of success in an organization’s data and analytics strategy. It’s the foundational architecture and dataintegration capability for high-value data products. Data and cloud strategy must align.
AWS Glue is a serverless dataintegration service that makes it easier to discover, prepare, and combine data for analytics, machine learning (ML), and application development. One of the most common questions we get from customers is how to effectively optimize costs on AWS Glue.
The benefits of hybrid multicloud in healthcare When it comes to cloud adoption, the healthcare industry has been slow to relinquish the traditional on-premises data center due to strict regulatory and security requirements and concerns around interoperability and dataintegration.
By providing real-time visibility into the performance and behavior of data-related systems, DataOps observability enables organizations to identify and address issues before they become critical, and to optimize their data-related workflows for maximum efficiency and effectiveness.
By using the AWS Glue OData connector for SAP, you can work seamlessly with your data on AWS Glue and Apache Spark in a distributed fashion for efficient processing. AWS Glue OData connector for SAP uses the SAP ODP framework and OData protocol for data extraction.
As organizations increasingly rely on data stored across various platforms, such as Snowflake , Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these disparate data sources together has never been more pressing.
Agile BI and Reporting, Single Customer View, Data Services, Web and Cloud Computing Integration are scenarios where Data Virtualization offers feasible and more efficient alternatives to traditional solutions. Does Data Virtualization support web dataintegration? In improving operational processes.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content