This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the growing emphasis on data, organizations are constantly seeking more efficient and agile ways to integrate their data, especially from a wide variety of applications. We take care of the ETL for you by automating the creation and management of data replication. Glue ETL offers customer-managed data ingestion.
This article was published as a part of the Data Science Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective dataintegration. Building an ETL pipeline using Apache […].
This article was published as a part of the Data Science Blogathon. Introduction to ETL ETL is a type of three-step dataintegration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build Big Data.
This article was published as a part of the Data Science Blogathon. Introduction Azure Synapse Analytics is a cloud-based service that combines the capabilities of enterprise data warehousing, big data, dataintegration, data visualization and dashboarding.
Amazon Web Services (AWS) has been recognized as a Leader in the 2024 Gartner Magic Quadrant for DataIntegration Tools. This recognition, we feel, reflects our ongoing commitment to innovation and excellence in dataintegration, demonstrating our continued progress in providing comprehensive data management solutions.
This article was published as a part of the Data Science Blogathon. Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and dataintegration service which allows you to create a data-driven workflow. In this article, I’ll show […].
In 2017, we published “ How Companies Are Putting AI to Work Through Deep Learning ,” a report based on a survey we ran aiming to help leaders better understand how organizations are applying AI through deep learning. Companies are building or evaluating solutions in foundational technologies needed to sustain success in analytics and AI.
Plug-and-play integration : A seamless, plug-and-play integration between data producers and consumers should facilitate rapid use of new data sets and enable quick proof of concepts, such as in the data science teams. As part of the required data, CHE data is shared using Amazon DataZone.
Machine learning solutions for dataintegration, cleaning, and data generation are beginning to emerge. “AI AI starts with ‘good’ data” is a statement that receives wide agreement from data scientists, analysts, and business owners. Dataintegration and cleaning.
Let’s briefly describe the capabilities of the AWS services we referred above: AWS Glue is a fully managed, serverless, and scalable extract, transform, and load (ETL) service that simplifies the process of discovering, preparing, and loading data for analytics.
Like software, data products should have versioning and changelogs to track evolution and impact. Publish metadata, documentation and use guidelines. Make it easy to discover, understand and use data through accessible catalogs and standardized documentation. Establishing clear accountability ensures dataintegrity.
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity. Choose Run all.
From the Unified Studio, you can collaborate and build faster using familiar AWS tools for model development, generative AI, data processing, and SQL analytics. This experience includes visual ETL, a new visual interface that makes it simple for data engineers to author, run, and monitor extract, transform, load (ETL) dataintegration flow.
Industry analysts who follow the data and analytics industry tell DataKitchen that they are receiving inquiries about “data fabrics” from enterprise clients on a near-daily basis. Gartner included data fabrics in their top ten trends for data and analytics in 2019.
For these reasons, publishing the data related to elections is obligatory for all EU member states under Directive 2003/98/EC on the re-use of public sector information and the Bulgarian Central Elections Committee (CEC) has released a complete export of every election database since 2011. Easily accessible linked open elections data.
They give data scientists tools to instantiate development sandboxes on demand. They automate the data operations pipeline and create platforms used to test and monitor data from ingestion to published charts and graphs.
Dataintegrity constraints: Many databases don’t allow for strange or unrealistic combinations of input variables and this could potentially thwart watermarking attacks. Applying dataintegrity constraints on live, incoming data streams could have the same benefits. Disparate impact analysis: see section 1.
Here, I’ll highlight the where and why of these important “dataintegration points” that are key determinants of success in an organization’s data and analytics strategy. It’s the foundational architecture and dataintegration capability for high-value data products. Data and cloud strategy must align.
This unified catalog enables engineers, data scientists, and analysts to securely discover and access approved data and models using semantic search with generative AI-created metadata. Collaboration is seamless, with straightforward publishing and subscribing workflows, fostering a more connected and efficient work environment.
A data fabric is an architectural approach that enables organizations to simplify data access and data governance across a hybrid multicloud landscape for better 360-degree views of the customer and enhanced MLOps and trustworthy AI. The post What is a data fabric architecture? appeared first on Journey to AI Blog.
Their rule says that if it costs $1 to check the quality of data at source, it costs $10 to clean up the same data and $100 if bad quality data is used. Couple this with the results of a study published in the Harvard Business Review which finds that only 3% of companies data meets basic quality standards !
Its platform supports both publishers and advertisers so both can understand which creative work delivers the best results. Publishers find a privacy-safe way to deliver first-party information to advertisers while advertisers get the information they need to track performance across all of the publishing platforms in the open web.
In addition to providing the core functionality for standardizing data governance and enabling self-service data access across a distributed enterprise, Collibra was early to identify the need to provide customers with information about how, when and where data is being produced and consumed across an enterprise.
This has been their play in other segments, especially automotive: to become the exclusive provider of this data. Kirkpatrick also speculated that, despite the lack of a published acquisition price, the quality of the Kyklo data is probably quite strong. Epicor “is getting product data. It’s probably pretty good.”
Some fantastic components of Power BI include: Power Query lets you merge data from different sources Power Pivot aids in data modelling for creating data models Power View constructs interactive charts, graphs and maps. Data Processing, DataIntegration, and Data Presenting form the nucleus of Power BI.
You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. With these insights, teams have the visibility to make dataintegration pipelines more efficient. Select Publish new dashboard as , and enter GlueObservabilityDashboard. Choose Publish dashboard.
Features: intuitive visualizations on-premise and cloud report sharing dashboard and report publishing to the web indicators of data patterns integration with third-party services (Salesforce, Google Analytics, Zendesk, Azure, Mailchimp, etc.). Yet, there are promising rival products, worth attention. SAP Lumira.
Reading Time: 3 minutes While cleaning up our archive recently, I found an old article published in 1976 about data dictionary/directory systems (DD/DS). Nowadays, we no longer use the term DD/DS, but “data catalog” or simply “metadata system”. It was written by L.
The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. Read: The first capability of a data fabric is a semantic knowledge data catalog, but what are the other 5 core capabilities of a data fabric? 11 May 2021. .
However, embedding ESG into an enterprise data strategy doesnt have to start as a C-suite directive. Developers, data architects and data engineers can initiate change at the grassroots level from integrating sustainability metrics into data models to ensuring ESG dataintegrity and fostering collaboration with sustainability teams.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and dataintegrity.
Multi-channel publishing of data services. Agile BI and Reporting, Single Customer View, Data Services, Web and Cloud Computing Integration are scenarios where Data Virtualization offers feasible and more efficient alternatives to traditional solutions. Does Data Virtualization support web dataintegration?
AWS Glue is a serverless dataintegration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. For example, you can configure an Amazon EventBridge rule to invoke an AWS Lambda function to publish CloudWatch metrics every time AWS Glue jobs finish.
Business units can simply share data and collaborate by publishing and subscribing to the data assets. The Central IT team (Spoke N) subscribes the data from individual business units and consumes this data using Redshift Spectrum.
The second one is the Linked Open Data (LOD): a cloud of interlinked structured datasets published without centralized control across thousands of servers. In more detail, they explained that just as the hypertext Web changed how we think about the availability of documents, the Semantic Web is a radical way of thinking about data.
IT team members or consultants could leverage a simple, basic programming or scripting environment to define format templates and use data from Smarten Datasets and Smarten objects to produce stunning pixel perfect reports. Find out how Smarten Pixel Perfect Print Reports can simplify your workflow and speed the decision process.
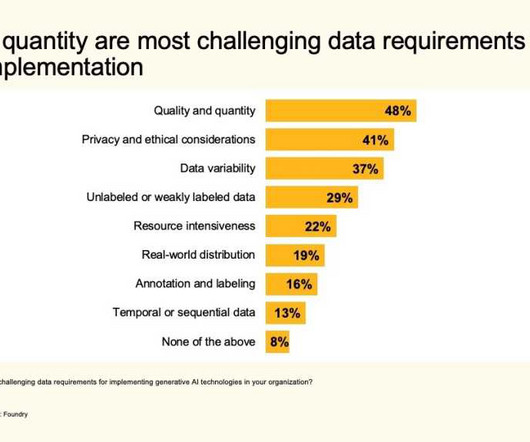
Enterprises are looking to AI to boost productivity and innovation, and one-third of organizations with an interest in the technology have hired or are looking for a chief AI officer, according to new research from Foundry, publisher of CIO.com.
We talk about systemic change, and it certainly helps to have the support of management, but data engineers should not underestimate the power of the keyboard. DataOps methods can help data organizations follow the path of continuous improvement forged by other industries and prevent data team burnout in the process.
We will partition and format the server access logs with Amazon Web Services (AWS) Glue , a serverless dataintegration service, to generate a catalog for access logs and create dashboards for insights. Both the user data and logs buckets must be in the same AWS Region and owned by the same account.
SageMaker Lakehouse offers integrated access controls and fine-grained permissions that are consistently applied across all analytics engines and AI models and tools. Existing Redshift data warehouses can be made available through SageMaker Lakehouse in just a simple publish step, opening up all your data warehouse data with Iceberg REST API.
Our services consuming this data inherit the same resilience from Amazon MSK. If our backend ingestion services face disruptions, no event is lost, because Kafka retains all published messages. Amazon MSK enables us to tailor the data retention duration to our specific requirements, ranging from seconds to unlimited duration.
Its platform supports both publishers and advertisers so both can understand which creative work delivers the best results. Publishers find a privacy-safe way to deliver first-party information to advertisers while advertisers get the information they need to track performance across all of the publishing platforms in the open web.
AWS Transfer Family seamlessly integrates with other AWS services, automates transfer, and makes sure data is protected with encryption and access controls. The Redshift publish zone is a different set of tables in the same Redshift provisioned cluster. 2 GB into the landing zone daily.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content