This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Zero-copy integration eliminates the need for manual data movement, preserving data lineage and enabling centralized control fat the data source. Currently, Data Cloud leverages live SQL queries to access data from external data platforms via zero copy. Ground generative AI.
You can invoke these models using familiar SQL commands, making it simpler than ever to integrate generative AI capabilities into your data analytics workflows. Launch summary Following is the launch summary which provides the announcement links and reference blogs for the key announcements.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. Refer to the Amazon Redshift Database Developer Guide for more details. Refer to API Dimensions & Metrics for details.
However, enterprise data generated from siloed sources combined with the lack of a dataintegration strategy creates challenges for provisioning the data for generative AI applications. Data discoverability Unlike structureddata, which is managed in well-defined rows and columns, unstructured data is stored as objects.
The second approach is to use some DataIntegration Platform. As an enterprise-supported tool, it has already established how to make all data transformations. This makes it possible for other users to reference the information without losing this link after an update. Persistent or non-persistent IDs?
The Business Application Research Center (BARC) warns that data governance is a highly complex, ongoing program, not a “big bang initiative,” and it runs the risk of participants losing trust and interest over time. The program must introduce and support standardization of enterprise data.
The history of data analysis has been plagued with a cavalier attitude toward data sources. That is ending; discussions of data ethics have made data scientists aware of the importance of data lineage and provenance. Salesforce’s solution is TransmogrifAI , an open source automated ML library for structureddata.
We rather see it as a new paradigm that is revolutionizing enterprise dataintegration and knowledge discovery. The two distinct threads interlacing in the current Semantic Web fabrics are the semantically annotated web pages with schema.org (structureddata on top of the existing Web) and the Web of Data existing as Linked Open Data.
AWS has invested in a zero-ETL (extract, transform, and load) future so that builders can focus more on creating value from data, instead of having to spend time preparing data for analysis. To create an AWS HealthLake data store, refer to Getting started with AWS HealthLake. reference", SUBSTRING(a."
Operations data: Data generated from a set of operations such as orders, online transactions, competitor analytics, sales data, point of sales data, pricing data, etc. The gigantic evolution of structured, unstructured, and semi-structureddata is referred to as Big data.
In this article, we are going to look at how software development can leverage on Big Data. We will also briefly have a sneak preview of the connection between AI and Big Data. Software development simply refers to a set of computer science-related activities purely dedicated to building, designing, and deploying software.
Let’s explore the continued relevance of data modeling and its journey through history, challenges faced, adaptations made, and its pivotal role in the new age of data platforms, AI, and democratized data access. Embracing the future In the dynamic world of data, data modeling remains an indispensable tool.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structureddata. The Central IT team manages a unified Redshift data warehouse, handling all dataintegration, processing, and maintenance.
Amazon Redshift is a fully managed data warehousing service that offers both provisioned and serverless options, making it more efficient to run and scale analytics without having to manage your data warehouse. These query patterns and concurrency were unpredictable in nature.
We’ve seen a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. With these connectors, you can bring the data from Azure Blob Storage and Azure Data Lake Storage separately to Amazon S3. Learn more in README.
This solution is suitable for customers who don’t require real-time ingestion to OpenSearch Service and plan to use dataintegration tools that run on a schedule or are triggered through events. Before data records land on Amazon S3, we implement an ingestion layer to bring all data streams reliably and securely to the data lake.
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF) , the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP) , as a Dataintegration and Democratization fabric. Introduction.
Whether you refer to the use of semantic technology as Linked Data technology or smart data management technology, these concepts boil down to connectivity. Connectivity in the sense of connecting data from different sources and assigning these data additional machine-readable meaning. Read more at: [link].
We’ve seen that there is a demand to design applications that enable data to be portable across cloud environments and give you the ability to derive insights from one or more data sources. With this connector, you can bring the data from Google Cloud Storage to Amazon S3. A Secrets Manager secret to store a Google Cloud secret.
This post focuses on such schema changes in file-based tables and shows how to automatically replicate the schema evolution of structureddata from table formats in databases to the tables stored as files in cost-effective way. For instructions to set up Aurora, refer to Creating an Amazon Aurora DB cluster.
The end goal is to give control of health data to patients so that they can build a comprehensive, interoperable, and reusable health medical record, which they can share with their treating physician anytime, anywhere. AIDAVA starts with AI – what is the role of AI in this project?
And each of these gains requires dataintegration across business lines and divisions. Limiting growth by (dataintegration) complexity Most operational IT systems in an enterprise have been developed to serve a single business function and they use the simplest possible model for this. We call this the Bad Data Tax.
Data Pipeline Use Cases Here are just a few examples of the goals you can achieve with a robust data pipeline: Data Prep for Visualization Data pipelines can facilitate easier data visualization by gathering and transforming the necessary data into a usable state.
From a technological perspective, RED combines a sophisticated knowledge graph with large language models (LLM) for improved natural language processing (NLP), dataintegration, search and information discovery, built on top of the metaphactory platform. Why do risk and opportunity events matter?
Data ingestion You have to build ingestion pipelines based on factors like types of data sources (on-premises data stores, files, SaaS applications, third-party data), and flow of data (unbounded streams or batch data). Data exploration Data exploration helps unearth inconsistencies, outliers, or errors.
A knowledge graph can be used as a database because it structuresdata that can be queried such as through a query language like SPARQL. This led to quicker access to data, improved usefulness of search results, which ultimately provided improved evidence-based decision-making and the efficient design of new clinical studies.
Customers often use many SQL scripts to select and transform the data in relational databases hosted either in an on-premises environment or on AWS and use custom workflows to manage their ETL. AWS Glue is a serverless dataintegration and ETL service with the ability to scale on demand. Select s3_crawler and choose Run.
Achieving this advantage is dependent on their ability to capture, connect, integrate, and convert data into insight for business decisions and processes. This is the goal of a “data-driven” organization. We call this the “ Bad Data Tax ”. In spite of all the activity, the data paradigm hasn’t evolved much.
hereinafter referred to as “Yanfeng Auto”) is a leading Chinese automotive parts supplier specializing in automotive interior and exterior trim, car seats, cabin electronics and safety systems. The auto parts manufacturers caught in it are facing the problem of how to survive and grow against the increasingly fierce competition.
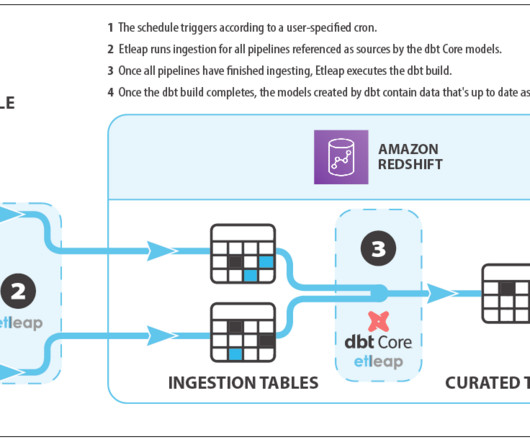
Etleap integrates key Amazon Redshift features into its product, such as streaming ingestion , Redshift Serverless , and data sharing. In Etleap, pre-load transformations are primarily used for cleaning and structuringdata, whereas post-load SQL transformations enable multi-table joins and dataset aggregations.
Whether you refer to the use of semantic technology as Linked Data technology or smart data management technology, these concepts boil down to connectivity. Connectivity in the sense of connecting data from different sources and assigning these data additional machine-readable meaning. Read more at: [link].
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into data validation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
Data Pipeline Use Cases Here are just a few examples of the goals you can achieve with a robust data pipeline: Data Prep for Visualization Data pipelines can facilitate easier data visualization by gathering and transforming the necessary data into a usable state.
Protect data at the source. Put data into action to optimize the patient experience and adapt to changing business models. What is Data Governance in Healthcare? Data governance in healthcare refers to how data is collected and used by hospitals, pharmaceutical companies, and other healthcare organizations and service providers.
We’ve listened to your requests and crafted a solution that eliminates complexity and empowers you to focus on what matters – gaining actionable insights from your data. Moving forward, Logi Symphony will be the single reference point for embedded analytics within our offerings.
Batch processing pipelines are designed to decrease workloads by handling large volumes of data efficiently and can be useful for tasks such as data transformation, data aggregation, dataintegration , and data loading into a destination system. What is the difference between ETL and data pipeline?
This often leaves business insights and opportunities lost among a tangled complexity of meaningless, siloed data and content. Knowledge graphs help overcome these challenges by unifying data access, providing flexible dataintegration, and automating data management.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content