This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many AWS customers have integrated their data across multiple data sources using AWS Glue , a serverless dataintegration service, in order to make data-driven business decisions. Are there recommended approaches to provisioning components for dataintegration?
NetApp is committed to delivering industry-leading performance through its upcoming enhancements to the NetApp AFF series systems and the ONTAP software. Seamless dataintegration. The AI data management engine is designed to offer a cohesive and comprehensive view of an organization’s data assets.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and dataintegrity.
Dataintegrity constraints: Many databases don’t allow for strange or unrealistic combinations of input variables and this could potentially thwart watermarking attacks. Applying dataintegrity constraints on live, incoming data streams could have the same benefits. Disparate impact analysis: see section 1.
Iceberg tables maintain metadata to abstract large collections of files, providing data management features including time travel, rollback, data compaction, and full schema evolution, reducing management overhead. Snowflake integrates with AWS Glue Data Catalog to retrieve the snapshot location.
Some of the DataOps best practices and industry discussion around errors have coalesced around the term “data observability.” In modern IT and software dev, people use the term observability to include the ability to find the root cause of a problem. This methodology is new to data analytics. Location Balance Tests.
Cost effectively maintaining Apache Iceberg tables Maintaining Apache Iceberg tables is crucial for optimizing performance, reducing storage costs, and ensuring dataintegrity. Expire snapshots Each write to an Iceberg table creates a new snapshot , or version, of a table.
But MongoDB also offers filesystem snapshot backups and queryable backups. DynamoDB is a bit more limited and complicated to manage as indexes are sized, billed, and provisioned separately from your data. Applications might end up handling stale data as global secondary indexes (GSIs) be inconsistent with underlying data.
In this tutorial, we assume that the files are updated with new records every day, and want to store only the latest record per the primary key ( ID and ELEMENT ) to make the latest snapshotdata queryable. Now your dataintegration job is authored in the visual editor completely. Choose Jobs. For Table name , enter ghcn.
Many AWS customers adopted Apache Hudi on their data lakes built on top of Amazon S3 using AWS Glue , a serverless dataintegration service that makes it easier to discover, prepare, move, and integratedata from multiple sources for analytics, machine learning (ML), and application development.
It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more often and 106 times faster, recover from incidents 2,604 times faster, and release 7 times fewer defects. For users that require a unified view of software quality, this is unacceptable.
But what is the state of AI and Big Data, right now? In this article, we take a snapshot look at the world of information processing as it stands in the present. Big data and AI have what is referred to as a synergistic relationship. Imagine the setup of your average software company. You have a billing department.
In this post, we discuss different architecture patterns to keep data in sync and up to date between data lakes built on open table formats and data warehouses such as Amazon Redshift. Various data stores are supported in AWS Glue; for example, AWS Glue 4.0 For S3 Target location , enter s3:// / /hudi_incremental/ghcn/.
Our previous solution offered visualization of key metrics, but point-in-time snapshots produced only in PDF format. We also saved 75% on our annual external software costs. Taking care of sensitive data iostudio operates in the AWS GovCloud environment because many of our customers are government agencies.
Using Apache Iceberg’s compaction results in significant performance improvements, especially for large tables, making a noticeable difference in query performance between compacted and uncompacted data. These files are then reconciled with the remaining data during read time.
Using Amazon MSK, we securely stream data with a fully managed, highly available Apache Kafka service. Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, dataintegration, and mission-critical applications.
It enables data engineers, data scientists, and analytics engineers to define the business logic with SQL select statements and eliminates the need to write boilerplate data manipulation language (DML) and data definition language (DDL) expressions. He is responsible for building software artifacts to help customers.
Contemporary dashboards surpass basic visualization and reporting by utilizing financial analytics to amalgamate diverse financial and accounting data, empowering analysts to delve further into the data and uncover valuable insights that can optimize cost-efficiency and enhance profitability. Free Download of FineReport 1.
Customers across industries seek meaningful insights from the data captured in their Customer Relationship Management (CRM) systems. To achieve this, they combine their CRM data with a wealth of information already available in their data warehouse, enterprise systems, or other software as a service (SaaS) applications.
“Cloud data warehouses can provide a lot of upfront agility, especially with serverless databases,” says former CIO and author Isaac Sacolick. There are tools to replicate and snapshotdata, plus tools to scale and improve performance.” Migration leaders would be wise to filter out data, not to migrate via a clear policy.
Users can apply built-in schema tests (such as not null, unique, or accepted values) or define custom SQL-based validation rules to enforce dataintegrity. dbt Core allows for data freshness monitoring and timeliness assessments, ensuring tables are updated within anticipated intervals in addition to standard schema validations.
Note: All the KPI report templates shown in this article are created by FineReport , a powerful reportin g software that has been honorably mentioned by Gartner Magic Quadrant for ABI Platforms in 2023. Additionally, the report presents daily sales revenue, which gives a snapshot of the revenue generated on a daily basis.
Managers can obtain an up-to-date snapshot of the project’s scope, time, cost, and quality parameters. This may include financial records, sales reports, customer feedback, or any other data that aligns with your performance objectives. Ensure the data is comprehensive and representative of the period or project under evaluation.
The importance of publishing only high-quality data cant be overstatedits the foundation for accurate analytics, reliable machine learning (ML) models, and sound decision-making. AWS Glue is a serverless dataintegration service that you can use to effectively monitor and manage data quality through AWS Glue Data Quality.
That might be a sales performance dashboard for your Chief Revenue Officer, a snapshot of “days sales outstanding” (DSO) for the A/R collections team, or an item sales trend analysis for product management. The finance experts at CXO Software ?have Step 6: Drill Into the Data. CXO Software: Intelligent Reporting Solutions.
Enterprise Resource Planning (ERP) software plays a central role in the finance function. Inventory management, MRP, project management, and customer relationship management (CRM) are now commonplace, extending or integrating with existing ERP software. Challenge 1. ERP Complexity.
It relieves them of the burdens typically associated with installing and maintaining complex software systems, and it’s arguably more secure because it’s monitored 24/7 by dedicated experts. The problem is that the exported data rarely conforms to the format you need. The Many Problems of Manual Reporting Processes.
Many of the problems faced by today’s companies originate from the use of disparate software systems, all of which operate somewhat independently. All of that in-between work–the export, the consolidation, and the cleanup–means that analysts are stuck using a snapshot of the data. CXO Software is a finance-driven solution.
Imagine the following scenario: You’re building next year’s budget in Microsoft Excel, using current year-to-date actuals that you exported from your enterprise resource planning (ERP) software. The source data in this scenario represents a snapshot of the information in your ERP system. Going Beyond the General Ledger.
Instead of poring over reams of columnar data, users can intuitively grasp what is happening in the business with just a glance. The best dashboard software enables users to drill down to the details in the ERP system to further explore what is happening and why. Hidden Do you resell software? Highlight key takeaways.
And that is only a snapshot of the benefits your finance users will enjoy with Angles for Deltek. Angles has been effective to providing us real-time financial and operational data that otherwise we would have to manually parse together. Hidden Do you resell software? Prospective Customer. Current Customer.
Advantages : Replication reduces the load on source systems because data extraction occurs at predefined intervals, reducing the real-time impact on production systems. It provides consistency in data for reporting purposes, as you are working with snapshots of the data at a particular point in time.
Apache HBase is an open source, non-relational distributed database developed as part of the Apache Software Foundation’s Hadoop project. Running HBase on Amazon S3 has several added benefits, including lower costs, data durability, and easier scalability. HBase provided by other cloud platforms doesn’t support snapshots.
The company wanted to leverage all the benefits the cloud could bring, get out of the business of managing hardware and software, and not have to deal with all the complexities around security, he says. “Quite frankly, we didn’t have the internal resources to support an on-premise solution,” Shannon says.
Data lineage is typically stored in separate systems from the data itself and can be difficult to keep up-to-date. Five on DataOps Observability : DataOps Observability is the ability to understand the state and behavior of data and the software and hardware that carries and transforms it as it flows through systems.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














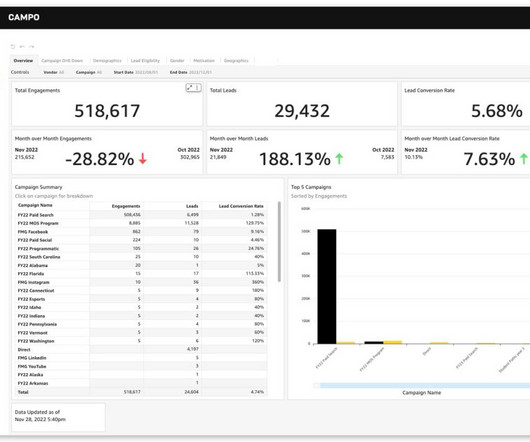











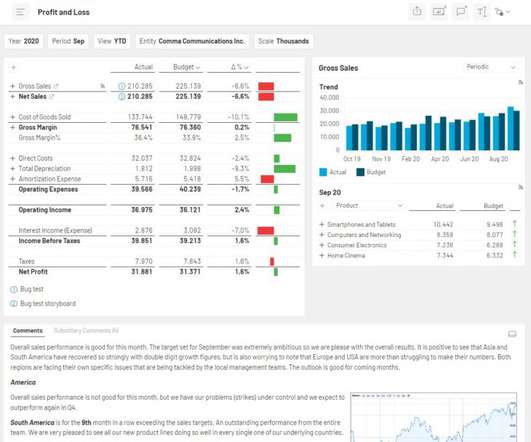

















Let's personalize your content