This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations are collecting and storing vast amounts of structured and unstructured data like reports, whitepapers, and research documents. By consolidating this information, analysts can discover and integrate data from across the organization, creating valuable data products based on a unified dataset.
For example, as manufacturers, we create a knowledge base, but no one can find anything without spending hours searching and browsing through the contents. Or we create a datalake, which quickly degenerates to a data swamp. Contextual data understanding Data systems often cause major problems in manufacturing firms.
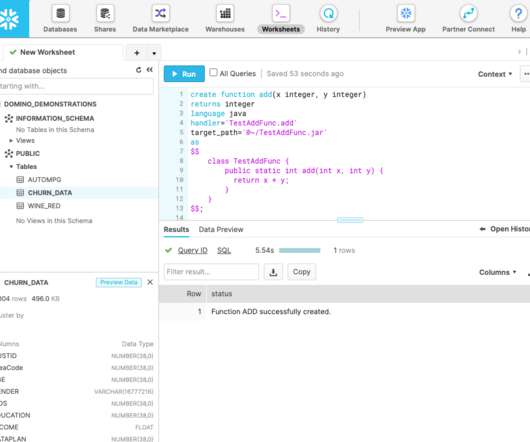
Over the next decade, the companies that will beat competitors will be “model-driven” businesses. These companies often undertake large data science efforts in order to shift from “data-driven” to “model-driven” operations, and to provide model-underpinned insights to the business. Why Snowflake UDFs.
Gartner predicts that graph technologies will be used in 80% of data and analytics innovations by 2025, up from 10% in 2021. Several factors are driving the adoption of knowledge graphs. Use Case #1: Customer 360 / Enterprise 360 Customer data is typically spread across multiple applications, departments, and regions.
There is a confluence of activity—including generative AI models, digital twins, and shared ledger capabilities—that are having a profound impact on helping enterprises meet their goal of becoming datadriven. But until they connect the dots across their data, they will never be able to truly leverage their information assets.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content