This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction All datamining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Rapidminer is a visual enterprise data science platform that includes data extraction, datamining, deep learning, artificial intelligence and machine learning (AI/ML) and predictive analytics. It can support AI/ML processes with data preparation, model validation, results visualization and model optimization.
Beyond breaking down silos, modern data architectures need to provide interfaces that make it easy for users to consume data using tools fit for their jobs. Data must be able to freely move to and from data warehouses, datalakes, and data marts, and interfaces must make it easy for users to consume that data.
A point of data entry in a given pipeline. Examples of an origin include storage systems like datalakes, data warehouses and data sources that include IoT devices, transaction processing applications, APIs or social media. The final point to which the data has to be eventually transferred is a destination.
McDermott’s sustainability innovation would not have been possible without key advancements in the cloud, analytics, and, in particular, datalakes, Dave notes. But for Dave, the key ingredient for innovation at McDermott is data. The structures for mining this fuel? Vagesh Dave. McDermott International.
In this post, we show how Ruparupa implemented an incrementally updated datalake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 datalake hourly with incremental data.
To further accurately analyze data, the company applies ML and LLM solutions to improve efficiency, and deploys datalake systems in its plants and new information monitoring systems in the production process.
Figure 2: Example data pipeline with DataOps automation. In this project, I automated data extraction from SFTP, the public websites, and the email attachments. The automated orchestration published the data to an AWS S3 DataLake. Priyanjna Sharma is a Senior DataOps Implementation Engineer at DataKitchen.
“We transferred our lab data—including safety, sensory efficacy, toxicology tests, product formulas, ingredients composition, and skin, scalp, and body diagnosis and treatment images—to our AWS datalake,” Gopalan says. This allowed us to derive insights more easily.”
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures.
Replatforming, datamining, building our datalakes to just clean the data, because back in those days it was so many systems, the data was not consistent. Now you start gathering all this information from a customer perspective,” Casanova says. Now we’re having one single point of entry.
The product line is broken into tools for basic exploration such as Visual DataMining or Visual Forecasting. A generous free tier makes it possible to experiment. There are also some focused tools for specific industries such as the Anti-Money Laundering software designed to forecast potential compliance problems.
With each game release and update, the amount of unstructured data being processed grows exponentially, Konoval says. This volume of data poses serious challenges in terms of storage and efficient processing,” he says. To address this problem RetroStyle Games invested in datalakes.
In addition to using data to inform your future decisions, you can also use current data to make immediate decisions. Some of the technologies that make modern data analytics so much more powerful than they used t be include data management, datamining, predictive analytics, machine learning and artificial intelligence.
Barbara Eckman from Comcast is another keynote speaker, and is also presenting a breakout session about Comcast’s streaming data platform. The platform comprises ingest, transformation, and storage services in the public cloud, and on-prem RDBMS’s, EDW’s, and a large, ungoverned legacy datalake.
The data science lifecycle Data science is iterative, meaning data scientists form hypotheses and experiment to see if a desired outcome can be achieved using available data. Watsonx comprises of three powerful components: the watsonx.ai
Universal data fabric : With the explosive growth of data in all different forms—structured, semi-structured and unstructured—there is a need to work with massive amounts of data, mine it, and make it easily accessible so one can gather intelligence and analytics out of it.
We can determine the following are needed: An open data format ingestion architecture processing the source dataset and refining the data in the S3 datalake. This requires a dedicated team of 3–7 members building a serverless datalake for all data sources. Vijay Bagur is a Sr.
The middle tier is typically a relational data store with schemas that support analytical processing. The top tier is an analytics tier that includes everything from standard querying tools to analytics, datamining, AI or ML capabilities, reporting, and presentation visualization tools. Analytics and BI tools are the solution.
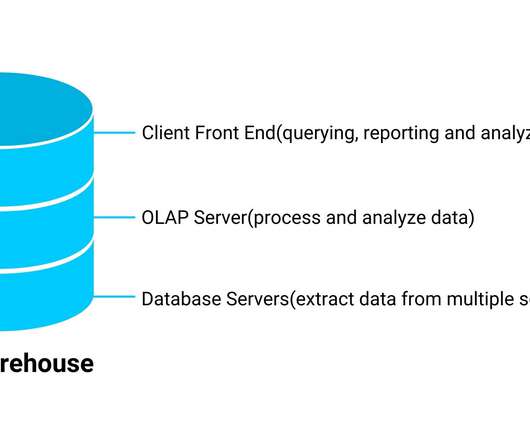
The BI infrastructure: This includes designing and implementing data warehouses, datalakes, data marts, and OLAP cubes along with datamining, and modeling. Without a strong BI infrastructure, it can be difficult to effectively collect, store, and analyze data.
The BI infrastructure: This includes designing and implementing data warehouses, datalakes, data marts, and OLAP cubes along with datamining, and modeling. Without a strong BI infrastructure, it can be difficult to effectively collect, store, and analyze data.
Try Db2 Warehouse SaaS on AWS for free Netezza SaaS on AWS IBM® Netezza® Performance Server is a cloud-native data warehouse designed to operationalize deep analytics, datamining and BI by unifying, accessing and scaling all types of data across the hybrid cloud. Netezza
Data analysts interpret data using statistical techniques, develop databases and data collection systems, and identify process improvement opportunities. They should possess technical expertise in data models, database design, and datamining, along with proficiency in reporting packages, databases, and programming languages.
The reasons for this are simple: Before you can start analyzing data, huge datasets like datalakes must be modeled or transformed to be usable. According to a recent survey conducted by IDC , 43% of respondents were drawing intelligence from 10 to 30 data sources in 2020, with a jump to 64% in 2021!
According to CIO magazine, the first chief data officer (CDO) was employed at Capital One in 2002, and since then the role has become widespread, driven by the recent explosion of big data. The CDO role has a variety of.
That was the Science, here comes the Technology… A Brief Hydrology of DataLakes. Even back then, these were used for activities such as Analytics , Dashboards , Statistical Modelling , DataMining and Advanced Visualisation. This is the essence of Convergent Evolution.
Integrating data through data warehouses and datalakes is one of the standard industry best practices for optimizing business intelligence. Datamining. Datamining is a technique used for refining data by removing any anomalies to identify and understand relationships between variables.
An excerpt from a rave review : “I would definitely recommend this book to everyone interested in learning about data from scratch and would say it is the finest resource available among all other Big Data Analytics books.”. If we had to pick one book for an absolute newbie to the field of Data Science to read, it would be this one.
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , data warehouse, datalake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content