This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Determine your preparedness.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Open AWS Glue Studio. Choose ETL Jobs.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. About the Authors Dave Horne is a Sr.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
This led to inefficiencies in data governance and access control. AWS Lake Formation is a service that streamlines and centralizes the datalake creation and management process. The Solution: How BMW CDH solved data duplication The CDH is a company-wide datalake built on Amazon Simple Storage Service (Amazon S3).
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
A domain has an important job and a dedicated team – five to nine members – who develop an intimate knowledge of data sources, data consumers and functional nuances. For example, managing ordered data dependencies, inter-domain communication, shared infrastructure, and incoherent workflows.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. Next, the merged data is filtered to include only a specific geographic region. Then the transformed output data is saved to Amazon S3 for further processing in future.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. To incorporate this third-party data, AWS Data Exchange is the logical choice.
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. For more information, see Changing the default settings for your datalake.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau.
Verify all table metadata is stored in the AWS Glue Data Catalog. Consume data with Athena or Amazon EMR Trino for business analysis. Update and delete source records in Amazon RDS for MySQL and validate the reflection of the datalake tables. the Flink table API/SQL can integrate with the AWS Glue Data Catalog.
On your project, in the navigation pane, choose Data. For Add data source , choose Add connection. For Host , enter your host name of your Aurora PostgreSQL database cluster. format(connection_properties["HOST"],connection_properties["PORT"],connection_properties["DATABASE"]) df.write.format("jdbc").option("url",
SnapLogic published Eight Data Management Requirements for the Enterprise DataLake. They are: Storage and Data Formats. The company also recently hosted a webinar on Democratizing the DataLake with Constellation Research and published 2 whitepapers from Mark Madsen. Ingest and Delivery.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region. Sesha Sanjana Mylavarapu is an Associate DataLake Consultant at AWS Professional Services.
Many companies whose AI model training infrastructure is not proximal to their datalake incur steeper costs as the data sets grow larger and AI models become more complex. Companies such as Cyxtera, Digital Realty and Equinix, among others, offer hosting, managing and operations services for AI infrastructure.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Of course, cost is a big consideration, says Orlandini, as well as deciding where to host the data, and having it available in a fiscally responsible way. An organization might also question if the data should be maintained on-premises due to security concerns in the public cloud. They have data swamps,” he says.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Therefore, organizations have come to host huge volumes of metadata of their structured datasets in the Hive metastore.
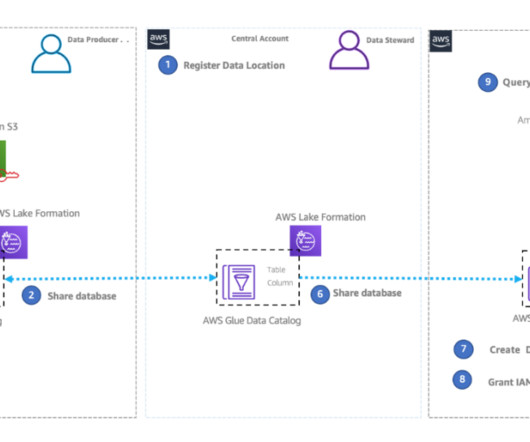
Today’s modern datalakes span multiple accounts, AWS Regions, and lines of business in organizations. It’s important that their data solution gives them the ability to share and access data securely and safely across Regions. For example, we are using a datalake administrator role called LF-Admin.
As a global company with more than 6,000 employees, BMC faces many of the same data challenges that other large enterprises face. The organization has 500 applications for business services, 80,000 VMs, 3,000 hosts, and more than 100,000 containers. Given the sheer volume of enterprise data, it’s impossible to do this manually.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Well, let’s find out. Artificial intelligence (AI). Easy to use.
In addition to AKS and the load balancers mentioned above, this includes VNET, DataLake Storage, PostgreSQL Azure database, and more. By default Azure DataLake Storage, PostgreSQL Database, and Virtual Machines are accessible over public endpoints. Additional Aspects of a Private CDW Environment on Azure. Next Steps.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
Its digital transformation began with an application modernization phase, in which Dickson and her IT teams determined which applications should be hosted in the public cloud and which should remain on a private cloud. Here, Dickson sees data generated from its industrial machines being very productive.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
All data is held in a lake-centric hub, and protected by a strong, universal security model, with data loss prevention and protection for sensitive data, and features for auditing and forensic investigation already built-in.
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public Cloud DataLake. CDP DataLake cluster versions – CM 7.4.0, Pre-Check: DataLake Cluster. Understanding Ranger Policies in DataLake Cluster. Runtime 7.2.8.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. Solution overview For our example use case, a customer uses Amazon EMR for data processing and Iceberg format for the transactional data. Choose Create.
Each data producer within the organization has its own datalake in Apache Hudi format, ensuring data sovereignty and autonomy. This enables data-driven decision-making across the organization.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). About the authors Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services.
The technological linchpin of its digital transformation has been its Enterprise Data Architecture & Governance platform. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, datalakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
You need to determine if you are going with an on-premise or cloud-hosted strategy. For example, you can collect the amount of business information fed into a datalake weekly, therefore, have the advantage to react immediately if issues arise. Then, you need to choose AND set-up the right BI solution for your organization!
They recently needed to do a monthly load of 140 TB of uncompressed healthcare claims data in under 24 hours after receiving it to provide analysts and data scientists with up-to-date information on a patient’s healthcare journey. This data volume is expected to increase monthly and is fully refreshed each month.
With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes. Choose Store a new secret.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content