This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For container terminal operators, data-driven decision-making and efficient data sharing are vital to optimizing operations and boosting supply chain efficiency. Two use cases illustrate how this can be applied for business intelligence (BI) and datascience applications, using AWS services such as Amazon Redshift and Amazon SageMaker.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. For more information, see Changing the default settings for your datalake.
Many companies whose AI model training infrastructure is not proximal to their datalake incur steeper costs as the data sets grow larger and AI models become more complex. Companies such as Cyxtera, Digital Realty and Equinix, among others, offer hosting, managing and operations services for AI infrastructure.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
This post was co-written with Rajiv Arora, Director of DataScience Platform at Gilead Life Sciences. Gilead Sciences, Inc. This data volume is expected to increase monthly and is fully refreshed each month. Create a datalake external schema and table in Redshift Serverless.
It unifies all data on a single platform, including data integration, engineering, and warehousing, where it can be used for datascience, real-time analytics, and business intelligence – and accessed with natural language queries and the power of generative AI.
The technological linchpin of its digital transformation has been its Enterprise Data Architecture & Governance platform. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
We also have a blended architecture of deep process capabilities in our SAP system and decision-making capabilities in our Microsoft tools, and a great base of information in our integrated data hub, or datalake, which is all Microsoft-based. That’s what we’re running our AI and our machine learning against.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
At the lowest layer is the infrastructure, made up of databases and datalakes. These applications live on innumerable servers, yet some technology is hosted in the public cloud. One strategy, five keys From a technological point of view, the brand’s strategic engine is divided into five investment areas.
This involves creating VPC endpoints in both the AWS and Snowflake VPCs, making sure data transfer remains within the AWS network. Use Amazon Route 53 to create a private hosted zone that resolves the Snowflake endpoint within your VPC. This unlocks scalable analytics while maintaining data governance, compliance, and access control.
Cloudera’s Data Warehouse service allows raw data to be stored in the cloud storage of your choice (S3, ADLSg2). It will be stored in your own namespace, and not force you to move data into someone else’s proprietary file formats or hosted storage. Proprietary file formats mean no one else is invited in! Separate compute.
The attack targeted a host of public and private sector organizations (18,000 customers) including NASA, the Justice Department, and Homeland Security, and it is believed the attackers persisted on SolarWinds systems for 14 months prior to discovery. The benefits and challenges of ML operations.
Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog.
2020 saw us hosting our first ever fully digital Data Impact Awards ceremony, and it certainly was one of the highlights of our year. We saw a record number of entries and incredible examples of how customers were using Cloudera’s platform and services to unlock the power of data. INDUSTRY TRANSFORMATION.
The AWS modern data architecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your datalake and the data warehouse. Let’s find out what role each of these components play in the context of C360.
The top three items are essentially “the devil you know” for firms which want to invest in datascience: data platform, integration, data prep. Data governance shows up as the fourth-most-popular kind of solution that enterprise teams were adopting or evaluating during 2019. Rinse, lather, repeat.
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating datalakes, serving as object storage for consumer applications, storing logs, and archiving data. This could be your datalake or application S3 bucket.
The workflow contains the following steps: Data is saved by the producer in their own Amazon Simple Storage Service (Amazon S3) buckets. Data source locations hosted by the producer are created within the producer’s AWS Glue Data Catalog. Data source locations are registered with Lake Formation.
IAM Identity Center now supports trusted identity propagation , a streamlined experience for users who require access to data with AWS analytics services. On the Lake Formation console, choose Datalake permissions under Permissions in the navigation pane. Select Named Data Catalog resources. Choose Grant.
Episode 4: Unlocking the Value of Enterprise AI with Data Engineering Capabilities. Unlocking the Value of Enterprise AI with Data Engineering Capabilities. They discuss how the data engineering team is instrumental in easing collaboration between analysts, data scientists and ML engineers to build enterprise AI solutions.
At Stitch Fix, we have been powered by datascience since its foundation and rely on many modern datalake and data processing technologies. In our infrastructure, Apache Kafka has emerged as a powerful tool for managing event streams and facilitating real-time data processing.
The DataRobot AI Platform seamlessly integrates with Azure cloud services, including Azure Machine Learning, Azure DataLake Storage Gen 2 (ADLS), Azure Synapse Analytics, and Azure SQL database. Models trained in DataRobot can also be easily deployed to Azure Machine Learning, allowing users to host models easier in a secure way.
There are now tens of thousands of instances of these Big Data platforms running in production around the world today, and the number is increasing every year. Many of them are increasingly deployed outside of traditional data centers in hosted, “cloud” environments. Streaming data analytics. .
By supporting open-source frameworks and tools for code-based, automated and visual datascience capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks.
Cargotec captures terabytes of IoT telemetry data from their machinery operated by numerous customers across the globe. This data needs to be ingested into a datalake, transformed, and made available for analytics, machine learning (ML), and visualization. The job runs in the target account.
On January 4th I had the pleasure of hosting a webinar. It was titled, The Gartner 2021 Leadership Vision for Data & Analytics Leaders. This was for the Chief Data Officer, or head of data and analytics. As such a head of analytics, BI and datascience may emerge. CAO may well be a name for that role.
This past week, I had the pleasure of hostingData Governance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , Data Governance lead at Alation. Can you differentiate between governance of raw data and enhanced data (information)? Where do you govern?
But Barnett, who started work on a strategy in 2023, wanted to continue using Baptist Memorial’s on-premise data center for financial, security, and continuity reasons, so he and his team explored options that allowed for keeping that data center as part of the mix.
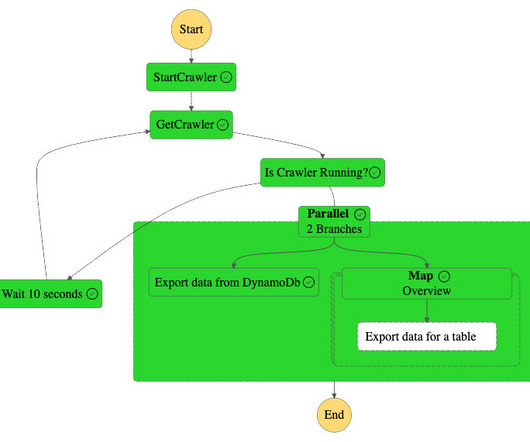
Solution overview One of the common functionalities involved in data pipelines is extracting data from multiple data sources and exporting it to a datalake or synchronizing the data to another database. There are multiple tables related to customers and order data in the RDS database.
Flexible deployment options for StarTree Cloud StarTree offers multiple deployment options, including a StarTree hosted software as a service (SaaS) or customer hosted SaaS. StarTrees customer hosted SaaS provides flexibility for customers interested in deploying the solution within their AWS environment or other platform of choice.
Refer to Datalake administrator permissions and Set up AWS Lake Formation. You can also refer to Simplify data access for your enterprise using Amazon SageMaker Lakehouse for the Lake Formation admin setup in your AWS account. An S3 bucket to host the sample Iceberg table data and metadata.
The absence of known authoritative sources for something as fundamental as product data meant data fragmentation and data inaccuracies would be continually at odds with the quality of informed business decisions. A decision made with AI based on bad data is still the same bad decision without it.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content