This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. Process the file to extract or convert the text content.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
On your project, in the navigation pane, choose Data. For Add data source , choose Add connection. For Host , enter your host name of your Aurora PostgreSQL database cluster. format(connection_properties["HOST"],connection_properties["PORT"],connection_properties["DATABASE"]) df.write.format("jdbc").option("url",
Verify all table metadata is stored in the AWS Glue Data Catalog. Consume data with Athena or Amazon EMR Trino for business analysis. Update and delete source records in Amazon RDS for MySQL and validate the reflection of the datalake tables. the Flink table API/SQL can integrate with the AWS Glue Data Catalog.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Therefore, organizations have come to host huge volumes of metadata of their structured datasets in the Hive metastore.
Datalakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams. The queries on these large datasets read vast amounts of data and can perform complex join operations on multiple datasets.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes. Choose Store a new secret.
It supports both data quality at rest and data quality in AWS Glue extract, transform, and load (ETL) pipelines. Data quality at rest focuses on validating the data stored in datalakes, databases, or data warehouses. It ensures that the data meets specific quality standards before it is consumed.
Modern applications store massive amounts of data on Amazon Simple Storage Service (Amazon S3) datalakes, providing cost-effective and highly durable storage, and allowing you to run analytics and machine learning (ML) from your datalake to generate insights on your data. table1 t1 join ` /database2`.table2
Cloudera’s Data Warehouse service allows raw data to be stored in the cloud storage of your choice (S3, ADLSg2). It will be stored in your own namespace, and not force you to move data into someone else’s proprietary file formats or hosted storage. Proprietary file formats mean no one else is invited in! Separate compute.
runtime, complete the following steps to create the corresponding layer package for peycopog2 : Download psycopg2_binary-2.9.9-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl His background is in data warehouse/datalake – architecture, development and administration. cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
RK built some simple flows to pull streaming data into Google Cloud Storage and Snowflake. Many developers use DataFlow to filter/enrich streams and ingest into cloud datalakes and warehouses where the ability to process and route anywhere makes DataFlow very effective. His submission post can be found here.
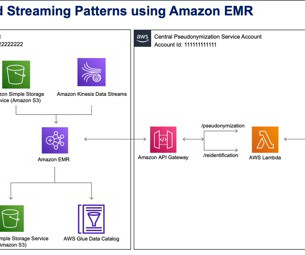
The account on the right hosts the pseudonymization service, which you can deploy using the instructions provided in the Part 1 of this series. For an overview of how to build an ACID compliant datalake using Iceberg, refer to Build a high-performance, ACID compliant, evolving datalake using Apache Iceberg on Amazon EMR.
Verify the job by running the following command: kubectl get pods -n data-team-a Enable access to the Spark UI The Spark UI is an important tool for data engineers because it allows you to track the progress of tasks, view detailed job and stage information, and analyze resource utilization to identify bottlenecks and optimize your code.
We can determine the following are needed: An open data format ingestion architecture processing the source dataset and refining the data in the S3 datalake. This requires a dedicated team of 3–7 members building a serverless datalake for all data sources. You can import this in Query Editor V2.0.
Tens of thousands of customers use Amazon Redshift to gain business insights from their data. With Amazon Redshift, you can use standard SQL to query data across your data warehouse, operational data stores, and datalake. You will specify this path in the AWS SCT and data extraction agent settings.
For instructions on installing Keycloak, refer to Keycloak Downloads. Download the SAML metadata file. Insert your specific host domain name where the Keycloak application resides in the following URL: [link] /realms/aws-realm/protocol/saml/descriptor. Download the Keycloak IdP SAML metadata file from that URL location.
Security Lake automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built datalake stored in your account. With Security Lake, you can get a more complete understanding of your security data across your entire organization. Choose Import.
OpenSearch Ingestion reads Parquet formatted security data from the Security Lake managed Amazon S3 bucket and transforms the security logs into JSON documents. OpenSearch Ingestion ingests this OCSF compliant data into OpenSearch Service. Optionally, specify the Amazon S3 storage class for the data in Amazon Security Lake.
It is also hard to know whether one can trust the data within a spreadsheet. And they rarely, if ever, host the most current data available. Sathish Raju, cofounder & CTO, Kloudio and senior director of engineering, Alation: This presents challenges for both business users and data teams.
The use of separate data warehouses and lakes has created data silos, leading to problems such as lack of interoperability, duplicate governance efforts, complex architectures, and slower time to value. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both data warehouses and datalakes.
An on-premise solution provides a high level of control and customization as it is hosted and managed within the organization’s physical infrastructure, but it can be expensive to set up and maintain. Next, identify the data sources that will be involved in the mapping.
The GPU-as-a-service model also minimizes the constantly evolving maintenance requirements of an AI infrastructure, including downloading massive amounts of genomics data, internet updates, and swapping Nvidia cards in and out, he says. We have 10 times the acceleration that we had before, Guo says.
Refer to Datalake administrator permissions and Set up AWS Lake Formation. You can also refer to Simplify data access for your enterprise using Amazon SageMaker Lakehouse for the Lake Formation admin setup in your AWS account. An S3 bucket to host the sample Iceberg table data and metadata.
Many organizations build and operate enterprise-wide data mesh architectures using the AWS Glue Data Catalog and AWS Lake Formation for their Amazon Simple Storage Service (Amazon S3) based datalakes. AWS Glue is a serverless service that makes data integration simpler, faster, and cheaper. and Python 3.11.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content