This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
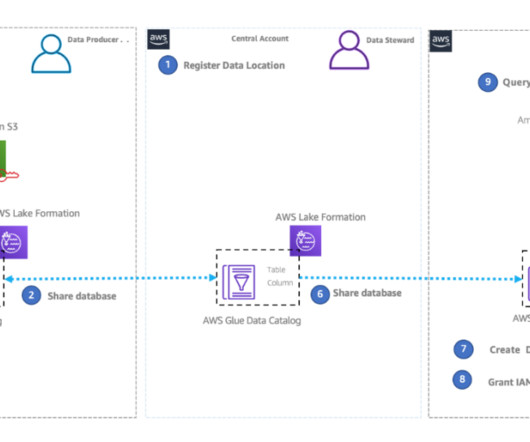
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging.
Data is the most significant asset of any organization. However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture.
DataOps adoption continues to expand as a perfect storm of social, economic, and technological factors drive enterprises to invest in process-driven innovation. As a result, enterprises will examine their end-to-end data operations and analytics creation workflows. Data Gets Meshier. Hub-Spoke Enterprise Architectures.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
The rise of generative AI (GenAI) felt like a watershed moment for enterprises looking to drive exponential growth with its transformative potential. However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. That’s why many enterprises are adopting a two-pronged approach to GenAI.
Over the past decade, deep learning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. But these powerful technologies also introduce new risks and challenges for enterprises. Data: the foundation of your foundation model Data quality matters.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Between building gen AI features into almost every enterprise tool it offers, adding the most popular gen AI developer tool to GitHub — GitHub Copilot is already bigger than GitHub when Microsoft bought it — and running the cloud powering OpenAI, Microsoft has taken a commanding lead in enterprise gen AI.
To build a data-driven business, it is important to democratize enterprisedata assets in a data catalog. With a unified data catalog, you can quickly search datasets and figure out data schema, data format, and location. Verify all table metadata is stored in the AWS Glue Data Catalog.
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region. Samir works directly with enterprise customers to design and build customized solutions catered to their data analytics and cybersecurity needs.
SnapLogic published Eight Data Management Requirements for the EnterpriseDataLake. They are: Storage and Data Formats. The company also recently hosted a webinar on Democratizing the DataLake with Constellation Research and published 2 whitepapers from Mark Madsen. Ingest and Delivery.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Under the federated mesh architecture, each divisional mesh functions as a node within the broader enterprisedata mesh, maintaining a degree of autonomy in managing its data products. This model balances node or domain-level autonomy with enterprise-level oversight, creating a scalable and consistent framework across ANZ.
Starting on a solid data foundation Before choosing a platform for sharing data, an organization needs to understand what data it already has and strip it of errors and duplicates. Data formats and data architectures are often inconsistent, and data might even be incomplete. They have data swamps,” he says.
Enterprises moving their artificial intelligence projects into full scale development are discovering escalating costs based on initial infrastructure choices. Many companies whose AI model training infrastructure is not proximal to their datalake incur steeper costs as the data sets grow larger and AI models become more complex.
Episode 4: Unlocking the Value of Enterprise AI with Data Engineering Capabilities. Unlocking the Value of Enterprise AI with Data Engineering Capabilities. Tune in to the podcast to know more about the evolving industry and how new technologies are transforming the enterprise AI landscape. PODCAST: Making AI Real.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
As a global company with more than 6,000 employees, BMC faces many of the same data challenges that other large enterprises face. The organization has 500 applications for business services, 80,000 VMs, 3,000 hosts, and more than 100,000 containers. Given the sheer volume of enterprisedata, it’s impossible to do this manually.
In fact, each of the 29 finalists represented organizations running cutting-edge use cases that showcase a winning enterprisedata cloud strategy. The technological linchpin of its digital transformation has been its EnterpriseData Architecture & Governance platform. Data for Enterprise AI.
For the past 5 years, BMS has used a custom framework called EnterpriseDataLake Services (EDLS) to create ETL jobs for business users. BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). Pavan leads enterprise metadata capabilities at BMS.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business.
Its digital transformation began with an application modernization phase, in which Dickson and her IT teams determined which applications should be hosted in the public cloud and which should remain on a private cloud. Here, Dickson sees data generated from its industrial machines being very productive.
Imagine a new type of business, one in which the fabric of data is so woven throughout the enterprise that it becomes almost a living, breathing entity that one day may even be able to make the right decisions for you. All of these Alation customers are experimenting with the beginnings of the Sentient Enterprise.
With AWS Glue, you can discover and connect to hundreds of diverse data sources and manage your data in a centralized data catalog. It enables you to visually create, run, and monitor extract, transform, and load (ETL) pipelines to load data into your datalakes. Choose Store a new secret.
And, in his experience, the public cloud is “not quite” as infinitely horizontally scalable as many think — though only a handful of enterprises come even close to reaching the barrier, he says. Randich, who came to FINRA.org in 2013 after stints as co-CIO of Citigroup and former CIO of Nasdaq, is no stranger to the public cloud.
Data is at the heart of everything we do today, from AI to machine learning or generative AI. We’ve been leveraging predictive technologies, or what I call traditional AI, across our enterprise for nearly two decades with R&D and manufacturing, for example, all partnering with IT. This work is not new to Dow.
From establishing an enterprise-wide data inventory and improving data discoverability, to enabling decentralized data sharing and governance, Amazon DataZone has been a game changer for HEMA. HEMA has a bespoke enterprise architecture, built around the concept of services.
In legacy analytical systems such as enterprisedata warehouses, the scalability challenges of a system were primarily associated with computational scalability, i.e., the ability of a data platform to handle larger volumes of data in an agile and cost-efficient way. Introduction. CRM platforms).
It’s necessary to say that these processes are recurrent and require continuous evolution of reports, online data visualization , dashboards, and new functionalities to adapt current processes and develop new ones. You need to determine if you are going with an on-premise or cloud-hosted strategy. Construction Iterations.
With more companies increasingly migrating their data to the cloud to ensure availability and scalability, the risks associated with data management and protection also are growing. Data Security Starts with Data Governance. Do You Know Where Your Sensitive Data Is?
Create a service on PagerDuty To create a service on PagerDuty, complete the following steps: Log in to PagerDuty using your personal or enterprise account that is being used to enable the integration with OpenSearch Service. For Host , enter events.PagerDuty.com. A PagerDuty account with access to create a service and integration.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structured data stores such as data warehouses to multi-format data stores like datalakes. Langchain) and LLM evaluations (e.g.
This involves creating VPC endpoints in both the AWS and Snowflake VPCs, making sure data transfer remains within the AWS network. Use Amazon Route 53 to create a private hosted zone that resolves the Snowflake endpoint within your VPC. This unlocks scalable analytics while maintaining data governance, compliance, and access control.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
Two private subnets are used to set up the Amazon MWAA environment, and the third private subnet is used to host the AWS Lambda authorizer function. Create the Azure AD service, users, groups, and enterprise application For the SSO integration with Azure, an enterprise application is required, which acts as the IdP for the SAML flow.
Typically, you have multiple accounts to manage and run resources for your data pipeline. He has a track record of more than 18 years innovating and delivering enterprise products that unlock the power of data for users. Outside of work, Xiaorun enjoys exploring new places in the Bay Area.
Small and midsize enterprises (SMEs) are the fastest-growing segment in the market due to reliability, scalability, integration, flexibility and improved productivity. As a small- to medium-sized enterprise (SME), TDC Digital needed a transparent billing system to predict its expenses and price its services effectively.
Cloudera’s Data Warehouse service allows raw data to be stored in the cloud storage of your choice (S3, ADLSg2). It will be stored in your own namespace, and not force you to move data into someone else’s proprietary file formats or hosted storage. Proprietary file formats mean no one else is invited in! Separate compute.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content