
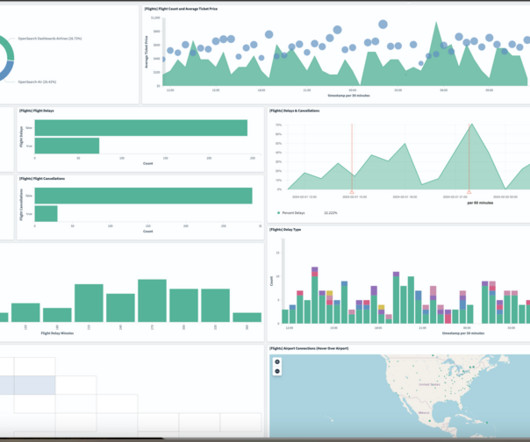
Building a scalable streaming data platform that enables real-time and batch analytics of electric vehicles on AWS
AWS Big Data
JULY 17, 2024
sink: - opensearch: # Provide an AWS OpenSearch Service domain endpoint hosts: [ "[link]. > arn: "arn:aws:kafka:us-east-1: >:cluster/ >/ >" processor: - parse_json: sink: - opensearch: # Provide an AWS OpenSearch Service domain endpoint hosts: [ "[link] > us-east-1.es.amazonaws.com"













Let's personalize your content