This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Migrate data, workloads, and applications.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Open AWS Glue Studio. Choose ETL Jobs.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
With over 10 PB of data across 1,500 data assets, 1,000 data use cases, and more than 9000 users, the BMW CDH has become a resounding success since BMW decided to build it in a strategic collaboration with Amazon Web Services (AWS) in 2020. This led to inefficiencies in data governance and access control.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. Let’s walk through the architecture chronologically for a closer look at each step.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
Many in the data industry recognize the serious impact of AI bias and seek to take active steps to mitigate it. The data industry realizes that AI bias is simply a quality problem, and AI systems should be subject to this same level of process control as an automobile rolling off an assembly line. Rise of the DataOps Engineer.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. With in-prompt context awareness, you can now include this information in your natural language query, and Amazon Q data integration will automatically extract and incorporate it into the workflow.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. These controls are designed to grant access with the right level of privileges and context.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. Recently, EUROGATE has developed a digital twin for its container terminal Hamburg (CTH), generating millions of data points every second from Internet of Things (IoT)devices attached to its container handling equipment (CHE).
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP. On your Visual Editor canvas, select your SAP sources.
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls. This is where data solutions like Dell AI-Ready Data Platform come in handy.
The organization has 500 applications for business services, 80,000 VMs, 3,000 hosts, and more than 100,000 containers. BMC needed a solution to transform this large volume of data and enable observability to understand thousands of events as a single scenario. This is turn ensures availability, reliability, and performance.
With the rapid growth of technology, more and more data volume is coming in many different formats—structured, semi-structured, and unstructured. Data analytics on operational data at near-real time is becoming a common need. Then we can query the data with Amazon Athena visualize it in Amazon QuickSight.
Now they have a new requirement to allow ad-hoc queries through SageMaker Unified Studio to enable data engineers, data analysts, sales representatives, and others to take advantage of its unified experience. For Host , enter your host name of your Aurora PostgreSQL database cluster. Choose Add data.
While cloud-native, point-solution data warehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. And you also already know siloed data is costly, as that means it will be much tougher to derive novel insights from all of your data by joining data sets.
Snapshot and restore results in longer downtimes and greater loss of data between when the disaster event occurs and recovery. The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region.
Finally, make sure you understand your data, because no machine learning solution will work for you if you aren’t working with the right data. Datalakes have a new consumer in AI. Many of our service-based offerings include hosting and executing our customers’ omnichannel platforms.
To build a data-driven business, it is important to democratize enterprise data assets in a data catalog. With a unified data catalog, you can quickly search datasets and figure out data schema, data format, and location. Verify all table metadata is stored in the AWS Glue Data Catalog.
Many companies whose AI model training infrastructure is not proximal to their datalake incur steeper costs as the data sets grow larger and AI models become more complex. Companies such as Cyxtera, Digital Realty and Equinix, among others, offer hosting, managing and operations services for AI infrastructure.
A data management platform (DMP) is a group of tools designed to help organizations collect and manage data from a wide array of sources and to create reports that help explain what is happening in those data streams. Deploying a DMP can be a great way for companies to navigate a business world dominated by data.
But to get maximum value out of data and analytics, companies need to have a data-driven culture permeating the entire organization, one in which every business unit gets full access to the data it needs in the way it needs it. This is called data democratization. They have data swamps,” he says.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
It’s necessary to say that these processes are recurrent and require continuous evolution of reports, online data visualization , dashboards, and new functionalities to adapt current processes and develop new ones. You need to determine if you are going with an on-premise or cloud-hosted strategy. Construction Iterations.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Therefore, organizations have come to host huge volumes of metadata of their structured datasets in the Hive metastore.
Whether it’s data management, analytics, or scalability, AWS can be the top-notch solution for any SaaS company. It has brought a lot of data to the cloud in recent years. Data storage databases. With the advancement of technology and more people accessing the internet, data security has become increasingly important.
Cloudera Data Warehouse (CDW) is a cloud native data warehouse service that runs Cloudera’s powerful query engines on a containerized architecture to do analytics on any type of data. It is part of the Cloudera Data Platform, or CDP , which runs on Azure and AWS, as well as in the private cloud.
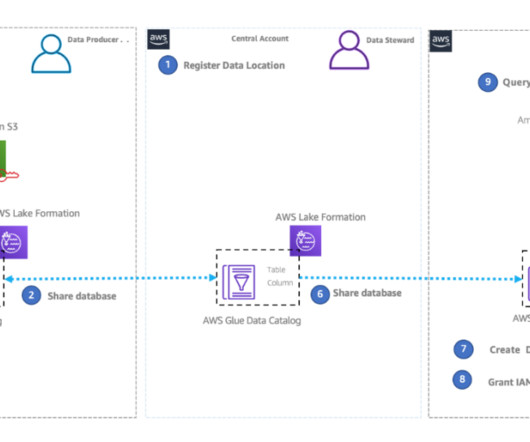
Today’s modern datalakes span multiple accounts, AWS Regions, and lines of business in organizations. It’s important that their data solution gives them the ability to share and access data securely and safely across Regions. For example, we are using a datalake administrator role called LF-Admin.
Generative AI tools are only as accurate and effective as the data they can access, and while government and public service agencies will have invested in their data infrastructure, it still may not be optimised for the demands of generative AI. This seems a formidable task. Microsoft Fabric could be one way to deal with it.
Its digital transformation began with an application modernization phase, in which Dickson and her IT teams determined which applications should be hosted in the public cloud and which should remain on a private cloud. This enables the company to extract additional value from the data through real-time availability and contextualization.
Data governance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or datalakes cataloged with the AWS Glue data catalog.
We needed a solution to manage our data at scale, to provide greater experiences to our customers. The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL was the first Pakistani commercial bank to be established in Pakistan in 1947.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
During the first-ever virtual broadcast of our annual Data Impact Awards (DIA) ceremony, we had the great pleasure of announcing this year’s finalists and winners. The technological linchpin of its digital transformation has been its Enterprise Data Architecture & Governance platform. Connect the Data Lifecycle .
In the ever-evolving world of finance and lending, the need for real-time, reliable, and centralized data has become paramount. Bluestone , a leading financial institution, embarked on a transformative journey to modernize its data infrastructure and transition to a data-driven organization.
In today’s rapidly evolving financial landscape, data is the bedrock of innovation, enhancing customer and employee experiences and securing a competitive edge. Like many large financial institutions, ANZ Institutional Division operated with siloed data practices and centralized data management teams.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users.
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public Cloud DataLake. CDP DataLake cluster versions – CM 7.4.0, Pre-Check: DataLake Cluster. Understanding Ranger Policies in DataLake Cluster. Runtime 7.2.8.
At the lowest layer is the infrastructure, made up of databases and datalakes. These applications live on innumerable servers, yet some technology is hosted in the public cloud. Data that unlocks value at both ends is key. This allows us greater productivity and creativity on the part of developers,” he says.
For Melanie Kalmar, the answer is data literacy and a strong foundation in tech. We also have a blended architecture of deep process capabilities in our SAP system and decision-making capabilities in our Microsoft tools, and a great base of information in our integrated data hub, or datalake, which is all Microsoft-based.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. Iceberg provides several implementation options for the Iceberg catalog, including the AWS Glue Data Catalog, Hive Metastore, and JDBC catalogs. Choose Create.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content