This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. To start the job, choose Run. format(dbname)).config("spark.sql.catalog.glue_catalog.catalog-impl",
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
The CDH is used to create, discover, and consume data products through a central metadata catalog, while enforcing permission policies and tightly integrating data engineering, analytics, and machinelearning services to streamline the user journey from data to insight.
The following requirements were essential to decide for adopting a modern data mesh architecture: Domain-oriented ownership and data-as-a-product : EUROGATE aims to: Enable scalable and straightforward data sharing across organizational boundaries. Eliminate centralized bottlenecks and complex data pipelines.
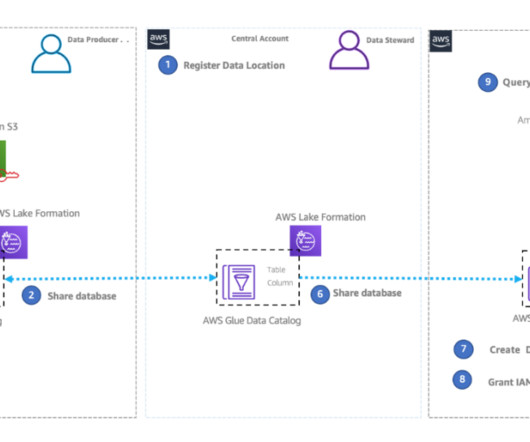
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
A domain has an important job and a dedicated team – five to nine members – who develop an intimate knowledge of data sources, data consumers and functional nuances. For example, managing ordered data dependencies, inter-domain communication, shared infrastructure, and incoherent workflows.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. To achieve this, they plan to use machinelearning (ML) models to extract insights from data.
Third, some services require you to set up and manage compute resources used for federated connectivity, and capabilities like connection testing and data preview arent available in all services. To solve for these challenges, we launched Amazon SageMaker Lakehouse unified data connectivity. For Add data source , choose Add connection.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. AWS also offers developers the technology to develop smart apps using machinelearning and complex algorithms.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
Its digital transformation began with an application modernization phase, in which Dickson and her IT teams determined which applications should be hosted in the public cloud and which should remain on a private cloud. 2, machinelearning/AI (31%), the packaging company has three use cases in proof of concept. As for No.
As a global company with more than 6,000 employees, BMC faces many of the same data challenges that other large enterprises face. The organization has 500 applications for business services, 80,000 VMs, 3,000 hosts, and more than 100,000 containers. Given the sheer volume of enterprise data, it’s impossible to do this manually.
Each data producer within the organization has its own datalake in Apache Hudi format, ensuring data sovereignty and autonomy. This enables data-driven decision-making across the organization. Her special areas of interest are data analytics, machinelearning/AI, and application modernization.
All data is held in a lake-centric hub, and protected by a strong, universal security model, with data loss prevention and protection for sensitive data, and features for auditing and forensic investigation already built-in.
The technological linchpin of its digital transformation has been its Enterprise Data Architecture & Governance platform. It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery. In its first six months of operation, OVO UnCover has proven to be 7.9
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
Previously head of cybersecurity at Ingersoll-Rand, Melby started developing neural networks and machinelearning models more than a decade ago. I was literally just waiting for commercial availability [of LLMs] but [services] like Azure MachineLearning made it so you could easily apply it to your data.
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
Because Gilead is expanding into biologics and large molecule therapies, and has an ambitious goal of launching 10 innovative therapies by 2030, there is heavy emphasis on using data with AI and machinelearning (ML) to accelerate the drug discovery pipeline. Create a datalake external schema and table in Redshift Serverless.
By using AWS Glue to integrate data from Snowflake, Amazon S3, and SaaS applications, organizations can unlock new opportunities in generative artificial intelligence (AI) , machinelearning (ML) , business intelligence (BI) , and self-service analytics or feed data to underlying applications.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
AWS Glue is a serverless data integration service that helps analytics users to discover, prepare, move, and integrate data from multiple sources for analytics, machinelearning (ML), and application development. Access to an SFTP server with permissions to upload and download data. Choose Store a new secret.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structured data stores such as data warehouses to multi-format data stores like datalakes. This makes gathering information for decision making a challenge.
At the core, digital at Dow is about changing how we work, which includes how we interact with systems, data, and each other to be more productive and to grow. Data is at the heart of everything we do today, from AI to machinelearning or generative AI. That’s what we’re running our AI and our machinelearning against.
These nodes can implement analytical platforms like datalake houses, data warehouses, or data marts, all united by producing data products. By treating the data as a product, the outcome is a reusable asset that outlives a project and meets the needs of the enterprise consumer.
Deploying new data types for machinelearning Mai-Lan Tomsen-Bukovec, vice president of foundational data services at AWS, sees the cloud giant’s enterprise customers deploying more unstructured data, as well as wider varieties of data sets, to inform the accuracy and training of ML models of late.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). About the authors Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services.
The attack targeted a host of public and private sector organizations (18,000 customers) including NASA, the Justice Department, and Homeland Security, and it is believed the attackers persisted on SolarWinds systems for 14 months prior to discovery. The world is awash in data. The benefits and challenges of ML operations.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
In today’s data-driven landscape, the quality of data is the foundation upon which the success of organizations and innovations stands. High-quality data is not just about accuracy; it’s also about timeliness. Reserve your seat now! Reserve your seat now! Reserve your seat now! Reserve your seat now!
Cloudera’s Data Warehouse service allows raw data to be stored in the cloud storage of your choice (S3, ADLSg2). It will be stored in your own namespace, and not force you to move data into someone else’s proprietary file formats or hosted storage. Proprietary file formats mean no one else is invited in! Separate compute.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
Modern applications store massive amounts of data on Amazon Simple Storage Service (Amazon S3) datalakes, providing cost-effective and highly durable storage, and allowing you to run analytics and machinelearning (ML) from your datalake to generate insights on your data.
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
Additionally, lines of business (LOBs) are able to gain access to a shared datalake that is secured and governed by the use of Cloudera Shared Data Experience (SDX). According to 451 Research’s Voice of the Enterprise: Cloud, Hosting & Managed Services study, 58% of Enterprises are moving towards a hybrid IT environment.
In addition, data pipelines include more and more stages, thus making it difficult for data engineers to compile, manage, and troubleshoot those analytical workloads. In addition, data pipelines include more and more stages, thus making it difficult for data engineers to compile, manage, and troubleshoot those analytical workloads.
The challenge is to do it right, and a crucial way to achieve it is with decisions based on data and analysis that drive measurable business results. This was the key learning from the Sisense event heralding the launch of Periscope Data in Tel Aviv, Israel — the beating heart of the startup nation. What VCs want from startups.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables. Sudipta Bagchi is a Sr.
2020 saw us hosting our first ever fully digital Data Impact Awards ceremony, and it certainly was one of the highlights of our year. We saw a record number of entries and incredible examples of how customers were using Cloudera’s platform and services to unlock the power of data. DATA FOR ENTERPRISE AI.
Finally, make sure you understand your data, because no machinelearning solution will work for you if you aren’t working with the right data. Datalakes have a new consumer in AI. Many of our service-based offerings include hosting and executing our customers’ omnichannel platforms.
That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. Plus, the more mature machinelearning (ML) practices place greater emphasis on these kinds of solutions than the less experienced organizations.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content