This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is part two of a three-part series where we show how to build a datalake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional datalake ( Apache Iceberg ) using AWS Glue. source_s3_bucket – The raw S3 bucket name. S3FileIO").getOrCreate()
This led to inefficiencies in data governance and access control. AWS Lake Formation is a service that streamlines and centralizes the datalake creation and management process. The Solution: How BMW CDH solved data duplication The CDH is a company-wide datalake built on Amazon Simple Storage Service (Amazon S3).
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Determine your preparedness. Authentication.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. We will use AWS Region us-east-1.
In this post, we delve into the key aspects of using Amazon EMR for modern datamanagement, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. Preprocessing Lambda enables you to run code without provisioning or managing servers.
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls. An example is Dell Technologies Enterprise DataManagement.
Since the deluge of big data over a decade ago, many organizations have learned to build applications to process and analyze petabytes of data. Datalakes have served as a central repository to store structured and unstructured data at any scale and in various formats.
A datamanagement platform (DMP) is a group of tools designed to help organizations collect and managedata from a wide array of sources and to create reports that help explain what is happening in those data streams. Deploying a DMP can be a great way for companies to navigate a business world dominated by data.
This means you can refine your ETL jobs through natural follow-up questionsstarting with a basic data pipeline and progressively adding transformations, filters, and business logic through conversation. The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios.
However, enterprises often encounter challenges with data silos, insufficient access controls, poor governance, and quality issues. Embracing data as a product is the key to address these challenges and foster a data-driven culture. These controls are designed to grant access with the right level of privileges and context.
Data Gets Meshier. 2022 will bring further momentum behind modular enterprise architectures like data mesh. The data mesh addresses the problems characteristic of large, complex, monolithic data architectures by dividing the system into discrete domains managed by smaller, cross-functional teams.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
Their terminal operations rely heavily on seamless data flows and the management of vast volumes of data. With the addition of these technologies alongside existing systems like terminal operating systems (TOS) and SAP, the number of data producers has grown substantially. datazone_env_twinsimsilverdata"."cycle_end";')
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and test data sources. This fragmented, repetitive, and error-prone experience for data connectivity is a significant obstacle to data integration, analysis, and machine learning (ML) initiatives.
Amazon OpenSearch Service is a fully managed service offered by AWS that enables you to deploy, operate, and scale OpenSearch domains effortlessly. This process can be programmatically scheduled using an AWS Lambda function, as described in Unleash the power of Snapshot Management to take automated snapshots using Amazon OpenSearch Service.
Data analytics on operational data at near-real time is becoming a common need. Due to the exponential growth of data volume, it has become common practice to replace read replicas with datalakes to have better scalability and performance. Apache Hudi connector for AWS Glue For this post, we use AWS Glue 4.0,
The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. Apache Flink is a widely used data processing engine for scalable streaming ETL, analytics, and event-driven applications. Apache Hudi also has its own catalog management.
Datamanagement platform definition A datamanagement platform (DMP) is a suite of tools that helps organizations to collect and managedata from a wide array of first-, second-, and third-party sources and to create reports and build customer profiles as part of targeted personalization campaigns.
We needed a solution to manage our data at scale, to provide greater experiences to our customers. With Cloudera Data Platform, we aim to unlock value faster and offer consistent data security and governance to meet this goal. HBL aims to double its banked customers by 2025. “
Recognizing this paradigm shift, ANZ Institutional Division has embarked on a transformative journey to redefine its approach to datamanagement, utilization, and extracting significant business value from data insights. This enables global discoverability and collaboration without centralizing ownership or operations.
SnapLogic published Eight DataManagement Requirements for the Enterprise DataLake. They are: Storage and Data Formats. The company also recently hosted a webinar on Democratizing the DataLake with Constellation Research and published 2 whitepapers from Mark Madsen. Ingest and Delivery.
Organizations often need to manage a high volume of data that is growing at an extraordinary rate. At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. We think of this concept as inside-out data movement.
Many companies whose AI model training infrastructure is not proximal to their datalake incur steeper costs as the data sets grow larger and AI models become more complex. Companies such as Cyxtera, Digital Realty and Equinix, among others, offer hosting, managing and operations services for AI infrastructure.
At Stitch Fix, we have been powered by data science since its foundation and rely on many modern datalake and data processing technologies. In our infrastructure, Apache Kafka has emerged as a powerful tool for managing event streams and facilitating real-time data processing.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Therefore, organizations have come to host huge volumes of metadata of their structured datasets in the Hive metastore.
When it comes to implementing and managing a successful BI strategy we have always proclaimed: start small, use the right BI tools , and involve your team. To fully utilize agile business analytics, we will go through a basic agile framework in regards to BI implementation and management. Let’s start with the concept.
Of course, cost is a big consideration, says Orlandini, as well as deciding where to host the data, and having it available in a fiscally responsible way. An organization might also question if the data should be maintained on-premises due to security concerns in the public cloud. They have data swamps,” he says.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structured data stores such as data warehouses to multi-format data stores like datalakes. Trulens), but this can be much more complex at an enterprise-level to manage.
Data governance is a key enabler for teams adopting a data-driven culture and operational model to drive innovation with data. Amazon DataZone allows you to simply and securely govern end-to-end data assets stored in your Amazon Redshift data warehouses or datalakes cataloged with the AWS Glue data catalog.
Whether it’s datamanagement, analytics, or scalability, AWS can be the top-notch solution for any SaaS company. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Management of data.
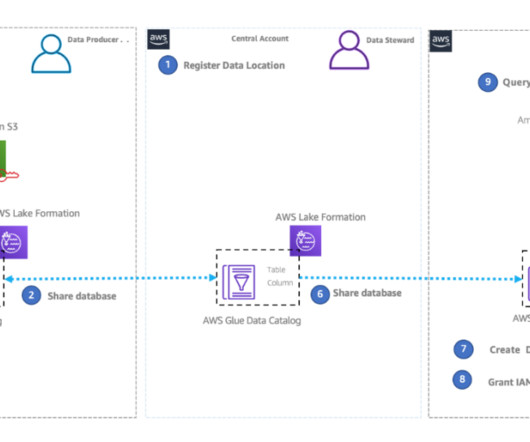
Today’s modern datalakes span multiple accounts, AWS Regions, and lines of business in organizations. It’s important that their data solution gives them the ability to share and access data securely and safely across Regions. For example, we are using a datalake administrator role called LF-Admin.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business.
AWS Glue is a serverless data integration service that helps analytics users to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. The SFTP connector is used to manage the connection to the SFTP server. Create the gateway endpoint.
The organization has 500 applications for business services, 80,000 VMs, 3,000 hosts, and more than 100,000 containers. BMC needed a solution to transform this large volume of data and enable observability to understand thousands of events as a single scenario.
Iceberg has become very popular for its support for ACID transactions in datalakes and features like schema and partition evolution, time travel, and rollback. AWS Glue crawlers will extract schema information and update the location of Iceberg metadata and schema updates in the Data Catalog. Choose Next. Choose Create.
In this post, we explore how Bluestone uses AWS services, notably the cloud data warehousing service Amazon Redshift , to implement a cutting-edge data mesh architecture, revolutionizing the way they manage, access, and utilize their data assets. This enables data-driven decision-making across the organization.
This involves creating VPC endpoints in both the AWS and Snowflake VPCs, making sure data transfer remains within the AWS network. Use Amazon Route 53 to create a private hosted zone that resolves the Snowflake endpoint within your VPC. Snowflake credentials are securely stored in AWS Secrets Manager.
In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud data warehouse.
Because Gilead is expanding into biologics and large molecule therapies, and has an ambitious goal of launching 10 innovative therapies by 2030, there is heavy emphasis on using data with AI and machine learning (ML) to accelerate the drug discovery pipeline. This data volume is expected to increase monthly and is fully refreshed each month.
Datalakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams. The queries on these large datasets read vast amounts of data and can perform complex join operations on multiple datasets.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















































Let's personalize your content