This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Quality test suites will enforce “equity,” like any other performance metric. For example, a Hub-Spoke architecture could integrate data from a multitude of sources into a datalake.
With data becoming the driving force behind many industries today, having a modern data architecture is pivotal for organizations to be successful. In this post, we describe Orca’s journey building a transactional datalake using Amazon Simple Storage Service (Amazon S3), Apache Iceberg, and AWS Analytics.
In Part 2 of this series, we discussed how to enable AWS Glue job observability metrics and integrate them with Grafana for real-time monitoring. In this post, we explore how to connect QuickSight to Amazon CloudWatch metrics and build graphs to uncover trends in AWS Glue job observability metrics.
cycle_end"', "sagemakedatalakeenvironment_sub_db", ctas_approach=False) A similar approach is used to connect to shared data from Amazon Redshift, which is also shared using Amazon DataZone. The applications are hosted in dedicated AWS accounts and require a BI dashboard and reporting services based on Tableau.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
Truly data-driven companies see significantly better business outcomes than those that aren’t. According to a recent IDC whitepaper , leaders saw on average two and a half times better results than other organizations in many business metrics. Most organizations don’t end up with datalakes, says Orlandini.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structured data stores such as data warehouses to multi-format data stores like datalakes. This makes gathering information for decision making a challenge.
You need to determine if you are going with an on-premise or cloud-hosted strategy. It might make sense to follow-up on specific operational metrics on a weekly or bi-weekly basis so that any issues or potential bottlenecks can be addressed quickly. Then, you need to choose AND set-up the right BI solution for your organization!
For Host , enter events.PagerDuty.com. Configure OpenSearch Service alerts to send notifications to PagerDuty We can monitor OpenSearch cluster health in two different ways: Using the OpenSearch Dashboard alerting plugin by setting up a per cluster metrics monitor. For Monitor type , select Per cluster metrics monitor.
At Stitch Fix, we have been powered by data science since its foundation and rely on many modern datalake and data processing technologies. In our infrastructure, Apache Kafka has emerged as a powerful tool for managing event streams and facilitating real-time data processing.
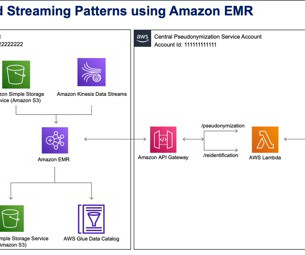
The account on the right hosts the pseudonymization service, which you can deploy using the instructions provided in the Part 1 of this series. For an overview of how to build an ACID compliant datalake using Iceberg, refer to Build a high-performance, ACID compliant, evolving datalake using Apache Iceberg on Amazon EMR.
Optimizing cloud investments requires close collaboration with the rest of the business to understand current and future needs, building effective FinOps teams, partnering with providers, and ongoing monitoring of key performance metrics. We need hard metrics because we’re running 800 instances of cloud computers.
These nodes can implement analytical platforms like datalake houses, data warehouses, or data marts, all united by producing data products. By treating the data as a product, the outcome is a reusable asset that outlives a project and meets the needs of the enterprise consumer.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
As an integrated manufacturing capability, Dow is a complex puzzle, and these AI models help us incorporate historical data, market trends, and customer behaviors, all of which allow us to produce a more precise demand plan. Also, last August, we ran an AI immersion day, which the CEO Jim Fitterling and I co-hosted for our top 200 leaders.
This allows business analysts and decision-makers to gain valuable insights, visualize key metrics, and explore the data in depth, enabling informed decision-making and strategic planning for pricing and promotional strategies. Use Amazon Route 53 to create a private hosted zone that resolves the Snowflake endpoint within your VPC.
Building datalakes from continuously changing transactional data of databases and keeping datalakes up to date is a complex task and can be an operational challenge. You can then apply transformations and store data in Delta format for managing inserts, updates, and deletes.
The function captures usage and cost metrics, which are subsequently stored in Amazon Relational Database Service (Amazon RDS) tables. The data stored in the RDS tables is then queried to derive chargeback figures and generate reporting trends using Amazon QuickSight. tbl_applicationlogs – RDS table to store EMR application run logs.
The challenge is to do it right, and a crucial way to achieve it is with decisions based on data and analysis that drive measurable business results. This was the key learning from the Sisense event heralding the launch of Periscope Data in Tel Aviv, Israel — the beating heart of the startup nation. What VCs want from startups.
Amazon Redshift , a warehousing service, offers a variety of options for ingesting data from diverse sources into its high-performance, scalable environment. This native feature of Amazon Redshift uses massive parallel processing (MPP) to load objects directly from data sources into Redshift tables. Sudipta Bagchi is a Sr.
The success criteria are the key performance indicators (KPIs) for each component of the data workflow. This includes the ETL processes that capture source data, the functional refinement and creation of data products, the aggregation for business metrics, and the consumption from analytics, business intelligence (BI), and ML.
It supports both data quality at rest and data quality in AWS Glue extract, transform, and load (ETL) pipelines. Data quality at rest focuses on validating the data stored in datalakes, databases, or data warehouses. It ensures that the data meets specific quality standards before it is consumed.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. Over time, workloads start processing more data, tenants start onboarding more workloads, and administrators (admins) start onboarding more tenants. Cloudera Manager (CM) 6.2
Since its launch in 2006, Amazon Simple Storage Service (Amazon S3) has experienced major growth, supporting multiple use cases such as hosting websites, creating datalakes, serving as object storage for consumer applications, storing logs, and archiving data. This could be your datalake or application S3 bucket.
The data lakehouse is gaining in popularity because it enables a single platform for all your enterprise data with the flexibility to run any analytic and machine learning (ML) use case. Cloud data lakehouses provide significant scaling, agility, and cost advantages compared to cloud datalakes and cloud data warehouses.
The following figure shows some of the metrics derived from the study. The AWS modern data architecture shows a way to build a purpose-built, secure, and scalable data platform in the cloud. Learn from this to build querying capabilities across your datalake and the data warehouse.
The DataRobot AI Platform seamlessly integrates with Azure cloud services, including Azure Machine Learning, Azure DataLake Storage Gen 2 (ADLS), Azure Synapse Analytics, and Azure SQL database. Models trained in DataRobot can also be easily deployed to Azure Machine Learning, allowing users to host models easier in a secure way.
Parameters of success Acast succeeded in bootstrapping and scaling a new team- and domain-oriented data product and its corresponding infrastructure and setup, resulting in less friction in gathering insights and happier users and consumers.
Security Lake automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built datalake stored in your account. With Security Lake, you can get a more complete understanding of your security data across your entire organization.
This past week, I had the pleasure of hostingData Governance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , Data Governance lead at Alation. In this way, data governance is the business or process side. Attendance was high, as were the number of excellent questions.
On January 4th I had the pleasure of hosting a webinar. It was titled, The Gartner 2021 Leadership Vision for Data & Analytics Leaders. This was for the Chief Data Officer, or head of data and analytics. Does Data warehouse as a software tool will play role in future of Data & Analytics strategy?
In this blog post, we delve into the intricacies of building a reliable data analytics pipeline that can scale to accommodate millions of vehicles, each generating hundreds of metrics every second using Amazon OpenSearch Ingestion. sink: - opensearch: # Provide an AWS OpenSearch Service domain endpoint hosts: [ "[link]. >
Our data team uses gen AI on Amazon cloud to explore sustainability metrics. Though a multicloud environment, the agency has most of its cloud implementations hosted on Microsoft Azure, with some on AWS and some on ServiceNow’s 311 citizen information platform. AI tools rely on the data in use in these solutions.
For Available load balancers , select the load balancer you created in the last step From Supported Regions, select an additional region if Data Cloud isnt hosted in the same AWS region as the Redshift instance. Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics.
Assuming the data platform roadmap aligns with required technical capabilities, this may help address downstream issues related to organic competencies versus bigger investments in acquiring competencies. The same would be true for a host of other similar cloud data platforms (Databricks, Azure Data Factory, AWS Redshift).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content