This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
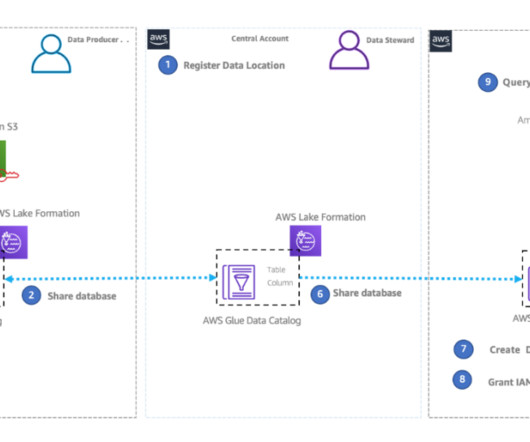
This led to inefficiencies in data governance and access control. AWS Lake Formation is a service that streamlines and centralizes the datalake creation and management process. The Solution: How BMW CDH solved data duplication The CDH is a company-wide datalake built on Amazon Simple Storage Service (Amazon S3).
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. About the Authors Dave Horne is a Sr.
One key component that plays a central role in modern data architectures is the datalake, which allows organizations to store and analyze large amounts of data in a cost-effective manner and run advanced analytics and machine learning (ML) at scale. Why did Orca build a datalake?
However, this enthusiasm may be tempered by a host of challenges and risks stemming from scaling GenAI. As the technology subsists on data, customer trust and their confidential information are at stake—and enterprises cannot afford to overlook its pitfalls.
Doing it right requires thoughtful data collection, careful selection of a data platform that allows holistic and secure access to the data, and training and empowering employees to have a data-first mindset. Security and compliance risks also loom. Most organizations don’t end up with datalakes, says Orlandini.
At the lowest layer is the infrastructure, made up of databases and datalakes. These applications live on innumerable servers, yet some technology is hosted in the public cloud. User data is also housed in this layer, including profile, behavior, transactions, and risk.
Globally, financial institutions have been experiencing similar issues, prompting a widespread reassessment of traditional data management approaches. With this approach, each node in ANZ maintains its divisional alignment and adherence to datarisk and governance standards and policies to manage local data products and data assets.
With more companies increasingly migrating their data to the cloud to ensure availability and scalability, the risks associated with data management and protection also are growing. Data Security Starts with Data Governance. Lack of a solid data governance foundation increases the risk of data-security incidents.
And you also already know siloed data is costly, as that means it will be much tougher to derive novel insights from all of your data by joining data sets. Of course you don’t want to re-create the risks and costs of data silos your organization has spent the last decade trying to eliminate. Must you be: .
You need to determine if you are going with an on-premise or cloud-hosted strategy. That way, your feedback cycle will be much shorter, workflow more effective, and risks minimized. During this stage, you are also researching and vetting which online business intelligence software to use. Construction Iterations. Accept change.
Datalakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern datalakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. In the navigation pane, under Data catalog , choose Settings.
It hosts over 150 big data analytics sandboxes across the region with over 200 users utilizing the sandbox for data discovery. With this functionality, business units can now leverage big data analytics to develop better and faster insights to help achieve better revenues, higher productivity, and decrease risk. .
Each data producer within the organization has its own datalake in Apache Hudi format, ensuring data sovereignty and autonomy. This enables data-driven decision-making across the organization.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
Over the past decade, deep learning arose from a seismic collision of data availability and sheer compute power, enabling a host of impressive AI capabilities. But these powerful technologies also introduce new risks and challenges for enterprises. We stand on the frontier of an AI revolution. All watsonx.ai
While there is more of a push to use cloud data for off-site backup , this method comes with its own caveats. In the event of a network shutdown or failure, it may take much longer to restore functionality (and therefore connection) to a cloud-hosted off-site backup. Big Data Storage Concerns. Conclusion.
Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
The data lakehouse is gaining in popularity because it enables a single platform for all your enterprise data with the flexibility to run any analytic and machine learning (ML) use case. Cloud data lakehouses provide significant scaling, agility, and cost advantages compared to cloud datalakes and cloud data warehouses.
Additionally, lines of business (LOBs) are able to gain access to a shared datalake that is secured and governed by the use of Cloudera Shared Data Experience (SDX). According to 451 Research’s Voice of the Enterprise: Cloud, Hosting & Managed Services study, 58% of Enterprises are moving towards a hybrid IT environment.
2020 saw us hosting our first ever fully digital Data Impact Awards ceremony, and it certainly was one of the highlights of our year. We saw a record number of entries and incredible examples of how customers were using Cloudera’s platform and services to unlock the power of data. HYBRID & MULTI-CLOUD INNOVATION.
Cloud has given us hope, with public clouds at our disposal we now have virtually infinite resources, but they come at a different cost – using the cloud means we may be creating yet another series of silos, which also creates unmeasurable new risks in security and traceability of our data. Key areas of concern are: .
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. Over time, workloads start processing more data, tenants start onboarding more workloads, and administrators (admins) start onboarding more tenants. Cloudera Manager (CM) 6.2
Considering the potential security risks and the gravitational pull of “if it isn’t broken, don’t fix it!”, How can we mitigate security and compliance risk? . There are now tens of thousands of instances of these Big Data platforms running in production around the world today, and the number is increasing every year.
This post outlines proactive steps you can take to mitigate the risks associated with unexpected disruptions and make sure your organization is better prepared to respond and recover Amazon Redshift in the event of a disaster. Choose your hosted zone. On the Route 53 console, choose Hosted zones in the navigation pane.
“Always the gatekeepers of much of the data necessary for ESG reporting, CIOs are finding that companies are even more dependent on them,” says Nancy Mentesana, ESG executive director at Labrador US, a global communications firm focused on corporate disclosure documents.
These techniques allow you to: See trends and relationships among factors so you can identify operational areas that can be optimized Compare your data against hypotheses and assumptions to show how decisions might affect your organization Anticipate risk and uncertainty via mathematically modeling.
Munich Re collects data from sensors embedded in vehicles and heavy equipment. This enables them to experiment with building model behaviors to drive more accurate insurance risk analysis. I’ll be there with the Alation team sharing our product and discussing how we can partner with you to drive data literacy in your organization.
The workflow contains the following steps: Data is saved by the producer in their own Amazon Simple Storage Service (Amazon S3) buckets. Data source locations hosted by the producer are created within the producer’s AWS Glue Data Catalog. Data source locations are registered with Lake Formation.
The DataRobot AI Platform seamlessly integrates with Azure cloud services, including Azure Machine Learning, Azure DataLake Storage Gen 2 (ADLS), Azure Synapse Analytics, and Azure SQL database. Models trained in DataRobot can also be easily deployed to Azure Machine Learning, allowing users to host models easier in a secure way.
At Stitch Fix, we have been powered by data science since its foundation and rely on many modern datalake and data processing technologies. In our infrastructure, Apache Kafka has emerged as a powerful tool for managing event streams and facilitating real-time data processing.
Start where your data is Using your own enterprise data is the major differentiator from open access gen AI chat tools, so it makes sense to start with the provider already hosting your enterprise data. Concerns over exposing data to staff who shouldn’t have access has delayed some Copilot deployments, Wong says.
Probably the best one-liner I’ve encountered is the analogy that: DG is to data assets as HR is to people. Also, while surveying the literature two key drivers stood out: Risk management is the thin-edge-of-the-wedge ?for Somehow, the gravity of the data has a geological effect that forms datalakes.
Effective planning, thorough risk assessment, and a well-designed migration strategy are crucial to mitigating these challenges and implementing a successful transition to the new data warehouse environment on Amazon Redshift. This requires a dedicated team of 3–7 members building a serverless datalake for all data sources.
Enrichment typically involves adding demographic, behavioral, and geolocation data. You can use third-party data products from AWS Marketplace delivered through AWS Data Exchange to gain insights on income, consumption patterns, credit risk scores, and many more dimensions to further refine the customer experience.
Users can also raise requests to producers to improve the way the data is presented or to enrich the data with new data points for generating a higher business value. At the same time, each team can also map other catalogs to their own account and use their own data, which they produce along with the data from other accounts.
Tens of thousands of customers use Amazon Redshift to gain business insights from their data. With Amazon Redshift, you can use standard SQL to query data across your data warehouse, operational data stores, and datalake. After you install the data extraction agent, register it in AWS SCT.
In this example, the analytics tool accesses the datalake on Amazon Simple Storage Service (Amazon S3) through Athena queries. As the data mesh pattern expands across domains covering more downstream services, we need a mechanism to keep IdPs and IAM role trusts continuously updated.
It is also hard to know whether one can trust the data within a spreadsheet. And they rarely, if ever, host the most current data available. Sathish Raju, cofounder & CTO, Kloudio and senior director of engineering, Alation: This presents challenges for both business users and data teams.
On January 4th I had the pleasure of hosting a webinar. It was titled, The Gartner 2021 Leadership Vision for Data & Analytics Leaders. This was for the Chief Data Officer, or head of data and analytics. But we also know not all data is equal, and not all data is equally valuable. Governance.
There are a lot of risks and a lot of land mines to navigate,” says the analyst. Coming to grips with risk The first step in making any bet — or investment — is to understand your ability to withstand risk. This ensures that none of our sensitive data and intellectual property are availed to an outside provider.”
The use of separate data warehouses and lakes has created data silos, leading to problems such as lack of interoperability, duplicate governance efforts, complex architectures, and slower time to value. You can use Amazon SageMaker Lakehouse to achieve unified access to data in both data warehouses and datalakes.
It automated and streamlined complex workflows, thereby reducing the risk of errors and enabling analysts to concentrate on more strategic tasks. Options included hosting a secondary data center, outsourcing business continuity to a vendor, and establishing private cloud solutions.
An on-premise solution provides a high level of control and customization as it is hosted and managed within the organization’s physical infrastructure, but it can be expensive to set up and maintain. Data warehouses can be complex, time-consuming, and expensive. Data sources can have different formats, structures, and schemas.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content