This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, we’re making available a new capability of AWS Glue Data Catalog that allows generating column-level statistics for AWS Glue tables. These statistics are now integrated with the cost-based optimizers (CBO) of Amazon Athena and Amazon Redshift Spectrum , resulting in improved query performance and potential cost savings.
In these instances, data feeds come largely from various advertising channels, and the reports they generate are designed to help marketers spend wisely. All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. SAS Data Management. Of course, marketing also works.
What are the benefits of data management platforms? Modern, data-driven marketing teams must navigate a web of connected data sources and formats. All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Of course, marketing also works.
Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. Delta tables technical metadata is stored in the Data Catalog, which is a native source for creating assets in the Amazon DataZone business catalog.
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public Cloud DataLake. CDP DataLake cluster versions – CM 7.4.0, Pre-Check: DataLake Cluster. Understanding Ranger Policies in DataLake Cluster. Runtime 7.2.8.
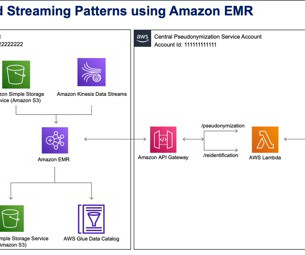
The account on the right hosts the pseudonymization service, which you can deploy using the instructions provided in the Part 1 of this series. For an overview of how to build an ACID compliant datalake using Iceberg, refer to Build a high-performance, ACID compliant, evolving datalake using Apache Iceberg on Amazon EMR.
Let’s consider the differences between the two, and why they’re both important to the success of data-driven organizations. Digging into quantitative data. This is quantitative data. It’s “hard,” structured data that answers questions such as “how many?” First, data isn’t created in a uniform, consistent format.
They recently needed to do a monthly load of 140 TB of uncompressed healthcare claims data in under 24 hours after receiving it to provide analysts and data scientists with up-to-date information on a patient’s healthcare journey. This data volume is expected to increase monthly and is fully refreshed each month.
The challenge is to do it right, and a crucial way to achieve it is with decisions based on data and analysis that drive measurable business results. This was the key learning from the Sisense event heralding the launch of Periscope Data in Tel Aviv, Israel — the beating heart of the startup nation. What VCs want from startups.
We can determine the following are needed: An open data format ingestion architecture processing the source dataset and refining the data in the S3 datalake. This requires a dedicated team of 3–7 members building a serverless datalake for all data sources. Vijay Bagur is a Sr.
On January 4th I had the pleasure of hosting a webinar. It was titled, The Gartner 2021 Leadership Vision for Data & Analytics Leaders. This was for the Chief Data Officer, or head of data and analytics. Does Data warehouse as a software tool will play role in future of Data & Analytics strategy?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content