This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Oracle recently hosted its annual Database Analyst Summit, sharing the vision and strategy for its data platform. While much of the event was under non-disclosure as product plans and launch schedules are finalized, it still served as a useful recap of the broad portfolio of data platform capabilities that Oracle has to offer.
A datalake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Open AWS Glue Studio. Choose ETL Jobs.
Azure DataLake Storage Gen2 is based on Azure Blob storage and offers a suite of big data analytics features. If you don’t understand the concept, you might want to check out our previous article on the difference between datalakes and data warehouses. Migrate data, workloads, and applications.
Amazon DataZone now launched authentication supports through the Amazon Athena JDBC driver, allowing data users to seamlessly query their subscribed datalake assets via popular business intelligence (BI) and analytics tools like Tableau, Power BI, Excel, SQL Workbench, DBeaver, and more. Choose Test connection.
In 2022, data organizations will institute robust automated processes around their AI systems to make them more accountable to stakeholders. Model developers will test for AI bias as part of their pre-deployment testing. Quality test suites will enforce “equity,” like any other performance metric.
Use cases for Hive metastore federation for Amazon EMR Hive metastore federation for Amazon EMR is applicable to the following use cases: Governance of Amazon EMR-based datalakes – Producers generate data within their AWS accounts using an Amazon EMR-based datalake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase.
For many organizations, this centralized data store follows a datalake architecture. Although datalakes provide a centralized repository, making sense of this data and extracting valuable insights can be challenging. We recommend testing your use case and data with different models.
The DataFrame code generation now extends beyond AWS Glue DynamicFrame to support a broader range of data processing scenarios. Next, the merged data is filtered to include only a specific geographic region. Then the transformed output data is saved to Amazon S3 for further processing in future.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. On your project, in the navigation pane, choose Data. Choose Next.
Your Chance: Want to test an agile business intelligence solution? Business intelligence is moving away from the traditional engineering model: analysis, design, construction, testing, and implementation. You need to determine if you are going with an on-premise or cloud-hosted strategy. Finalize testing. Train end-users.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. Marketing-focused or not, DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
It also makes it easier for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization to discover, use, and collaborate to derive data-driven insights. Note that a managed data asset is an asset for which Amazon DataZone can manage permissions.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Well, let’s find out. Artificial intelligence (AI). Easy to use.
The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Therefore, organizations have come to host huge volumes of metadata of their structured datasets in the Hive metastore.
To bring their customers the best deals and user experience, smava follows the modern data architecture principles with a datalake as a scalable, durable data store and purpose-built data stores for analytical processing and data consumption.
For Host , enter events.PagerDuty.com. Choose Send test message and test to make sure you receive an alert on the PagerDuty service. This notification can be safely acknowledged and resolved from PagerDuty because this is was a test. Vivek Shrivastava is a Principal Data Architect, DataLake in AWS Professional Services.
Many organizations are building datalakes to store and analyze large volumes of structured, semi-structured, and unstructured data. In addition, many teams are moving towards a data mesh architecture, which requires them to expose their data sets as easily consumable data products.
For the past 5 years, BMS has used a custom framework called Enterprise DataLake Services (EDLS) to create ETL jobs for business users. BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). About the authors Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services.
They recently needed to do a monthly load of 140 TB of uncompressed healthcare claims data in under 24 hours after receiving it to provide analysts and data scientists with up-to-date information on a patient’s healthcare journey. This data volume is expected to increase monthly and is fully refreshed each month.
Amazon Redshift is a fast, scalable, and fully managed cloud data warehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data. It also helps you securely access your data in operational databases, datalakes, or third-party datasets with minimal movement or copying of data.
But for two years, we were testing limits within the public cloud.” While managing unstructured data remains a challenge for 36% of organizations, according to the 2022 Foundry Data and Analytics Research survey, many IT leaders are actively seeking ways of harnessing all types of data stored in datalakes.
Datalakes are designed for storing vast amounts of raw, unstructured, or semi-structured data at a low cost, and organizations share those datasets across multiple departments and teams. The queries on these large datasets read vast amounts of data and can perform complex join operations on multiple datasets.
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, datalakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets.
This will enable right-sizing the Redshift data warehouse to meet workload demands cost-effectively. Thorough testing and performance optimization will facilitate a smooth transition with minimal disruption to end-users, fostering exceptional user experiences and satisfaction.
All this data arrives by the terabyte, and a data management platform can help marketers make sense of it all. DMPs excel at negotiating with a wide array of databases, datalakes, or data warehouses, ingesting their streams of data and then cleaning, sorting, and unifying the information therein.
Well firstly, if the main data warehouses, repositories, or application databases that BusinessObjects accesses are on premise, it makes no sense to move BusinessObjects to the cloud until you move its data sources to the cloud. You also have the option of hosting with a third party.
Modern applications store massive amounts of data on Amazon Simple Storage Service (Amazon S3) datalakes, providing cost-effective and highly durable storage, and allowing you to run analytics and machine learning (ML) from your datalake to generate insights on your data.
Beginning in 2021, the Minneapolis-based Microsoft partner helped Dairyland migrate from several custom legacy applications to a commercial implementation of Dynamics 365 and an Azure datalake, which set the stage for the power company’s early foray into AI, according to the systems integrator.
In this post, we’ll perform a similar test to validate that the feature works as expected in Azure, too. Below is the Azure CLI command: Cloudera allows FreeIPA servers, enterprise datalake, and data hub to be configured as Multi-AZ deployment.
Test out the disaster recovery plan by simulating a failover event in a non-production environment. Our pre-launch tests found that the RTO with Amazon Redshift Multi-AZ deployments is under 60 seconds or less in the unlikely case of an Availability Zone failure. Choose your hosted zone. Choose your hosted zone.
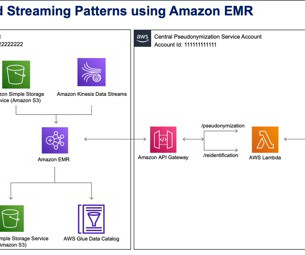
The account on the right hosts the pseudonymization service, which you can deploy using the instructions provided in the Part 1 of this series. For an overview of how to build an ACID compliant datalake using Iceberg, refer to Build a high-performance, ACID compliant, evolving datalake using Apache Iceberg on Amazon EMR.
Each service is hosted in a dedicated AWS account and is built and maintained by a product owner and a development team, as illustrated in the following figure. This separation means changes can be tested thoroughly before being deployed to live operations. The following figure illustrates the data mesh architecture.
The flow he built differentiates between test or true API call before initiating a secure log in. Completeness is estimated by comparing a test result with “estimated total.” RK built some simple flows to pull streaming data into Google Cloud Storage and Snowflake. The brilliant part comes next.
His background is in data warehouse/datalake – architecture, development and administration. He is in data and analytical field for over 14 years. Ramesh Raghupathy is a Senior Data Architect with WWCO ProServe at AWS. While not at work, Ramesh enjoys traveling, spending time with family, and yoga.
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) datalake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x
Use Lake Formation to grant permissions to users to access data. Test the solution by accessing data with a corporate identity. Audit user data access. On the Lake Formation console, choose Datalake permissions under Permissions in the navigation pane. Select Named Data Catalog resources.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. This solution uses Amazon Aurora MySQL hosting the example database salesdb.
Putting your data to work with generative AI – Innovation Talk Thursday, November 30 | 12:30 – 1:30 PM PST | The Venetian Join Mai-Lan Tomsen Bukovec, Vice President, Technology at AWS to learn how you can turn your datalake into a business advantage with generative AI. Reserve your seat now! Reserve your seat now!
Two private subnets are used to set up the Amazon MWAA environment, and the third private subnet is used to host the AWS Lambda authorizer function. Test the solution Now that the SAML configuration and relevant AWS services are created, it’s time to access the Amazon MWAA environment. For EntraIDLoginURL , enter the Azure IdP URI.
The typical Cloudera Enterprise Data Hub Cluster starts with a few dozen nodes in the customer’s datacenter hosting a variety of distributed services. Over time, workloads start processing more data, tenants start onboarding more workloads, and administrators (admins) start onboarding more tenants. Cloudera Manager (CM) 6.2
Episode 4: Unlocking the Value of Enterprise AI with Data Engineering Capabilities. Unlocking the Value of Enterprise AI with Data Engineering Capabilities. They discuss how the data engineering team is instrumental in easing collaboration between analysts, data scientists and ML engineers to build enterprise AI solutions.
As a QuickSight administrator, you can use AWS CloudFormation templates to migrate assets between distinct environments from development, to test, to production. Create an Amazon Redshift data source in AWS CloudFormation In this step, we add the AWS::QuickSight::DataSource section of the CloudFormation template.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
Additionally, quantitative data forms the basis on which you can confidently infer, estimate, and project future performance, using techniques such as regression analysis, hypothesis testing, and Monte Carlo simulations. Despite its many uses, quantitative data presents two main challenges for a data-driven organization.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content